 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniPLV: Towards Label-Efficient Open-World 3D Scene Understanding by Regional Visual Language Supervision
Dec 24, 2024We present UniPLV, a powerful framework that unifies point clouds, images and text in a single learning paradigm for open-world 3D scene understanding. UniPLV employs the image modal as a bridge to co-embed 3D points with pre-aligned images and text in a shared feature space without requiring carefully crafted point cloud text pairs. To accomplish multi-modal alignment, we propose two key strategies:(i) logit and feature distillation modules between images and point clouds, and (ii) a vison-point matching module is given to explicitly correct the misalignment caused by points to pixels projection. To further improve the performance of our unified framework, we adopt four task-specific losses and a two-stage training strategy. Extensive experiments show that our method outperforms the state-of-the-art methods by an average of 15.6% and 14.8% for semantic segmentation over Base-Annotated and Annotation-Free tasks, respectively. The code will be released later.
Verbalized Probabilistic Graphical Modeling with Large Language Models
Jun 08, 2024Faced with complex problems, the human brain demonstrates a remarkable capacity to transcend sensory input and form latent understandings of perceived world patterns. However, this cognitive capacity is not explicitly considered or encoded in current large language models (LLMs). As a result, LLMs often struggle to capture latent structures and model uncertainty in complex compositional reasoning tasks. This work introduces a novel Bayesian prompting approach that facilitates training-free Bayesian inference with LLMs by using a verbalized Probabilistic Graphical Model (PGM). While traditional Bayesian approaches typically depend on extensive data and predetermined mathematical structures for learning latent factors and dependencies, our approach efficiently reasons latent variables and their probabilistic dependencies by prompting LLMs to adhere to Bayesian principles. We evaluated our model on several compositional reasoning tasks, both close-ended and open-ended. Our results indicate that the model effectively enhances confidence elicitation and text generation quality, demonstrating its potential to improve AI language understanding systems, especially in modeling uncertainty.
Benchmarking Large Language Models on Communicative Medical Coaching: a Novel System and Dataset
Feb 08, 2024


Traditional applications of natural language processing (NLP) in healthcare have predominantly focused on patient-centered services, enhancing patient interactions and care delivery, such as through medical dialogue systems. However, the potential of NLP to benefit inexperienced doctors, particularly in areas such as communicative medical coaching, remains largely unexplored. We introduce ``ChatCoach,'' an integrated human-AI cooperative framework. Within this framework, both a patient agent and a coaching agent collaboratively support medical learners in practicing their medical communication skills during consultations. Unlike traditional dialogue systems, ChatCoach provides a simulated environment where a human doctor can engage in medical dialogue with a patient agent. Simultaneously, a coaching agent provides real-time feedback to the doctor. To construct the ChatCoach system, we developed a dataset and integrated Large Language Models such as ChatGPT and Llama2, aiming to assess their effectiveness in communicative medical coaching tasks. Our comparative analysis demonstrates that instruction-tuned Llama2 significantly outperforms ChatGPT's prompting-based approaches.
Semantic Entropy Can Simultaneously Benefit Transmission Efficiency and Channel Security of Wireless Semantic Communications
Feb 07, 2024Recently proliferated deep learning-based semantic communications (DLSC) focus on how transmitted symbols efficiently convey a desired meaning to the destination. However, the sensitivity of neural models and the openness of wireless channels cause the DLSC system to be extremely fragile to various malicious attacks. This inspires us to ask a question: "Can we further exploit the advantages of transmission efficiency in wireless semantic communications while also alleviating its security disadvantages?". Keeping this in mind, we propose SemEntropy, a novel method that answers the above question by exploring the semantics of data for both adaptive transmission and physical layer encryption. Specifically, we first introduce semantic entropy, which indicates the expectation of various semantic scores regarding the transmission goal of the DLSC. Equipped with such semantic entropy, we can dynamically assign informative semantics to Orthogonal Frequency Division Multiplexing (OFDM) subcarriers with better channel conditions in a fine-grained manner. We also use the entropy to guide semantic key generation to safeguard communications over open wireless channels. By doing so, both transmission efficiency and channel security can be simultaneously improved. Extensive experiments over various benchmarks show the effectiveness of the proposed SemEntropy. We discuss the reason why our proposed method benefits secure transmission of DLSC, and also give some interesting findings, e.g., SemEntropy can keep the semantic accuracy remain 95% with 60% less transmission.
NormalGAN: Learning Detailed 3D Human from a Single RGB-D Image
Jul 30, 2020
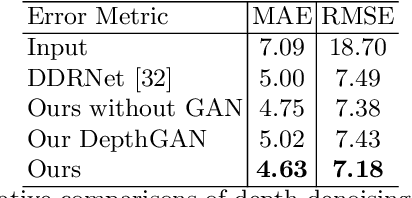
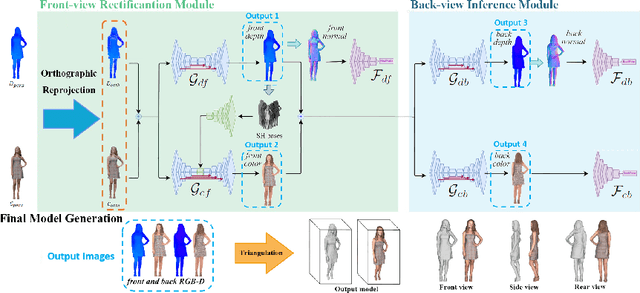

We propose NormalGAN, a fast adversarial learning-based method to reconstruct the complete and detailed 3D human from a single RGB-D image. Given a single front-view RGB-D image, NormalGAN performs two steps: front-view RGB-D rectification and back-view RGBD inference. The final model was then generated by simply combining the front-view and back-view RGB-D information. However, inferring backview RGB-D image with high-quality geometric details and plausible texture is not trivial. Our key observation is: Normal maps generally encode much more information of 3D surface details than RGB and depth images. Therefore, learning geometric details from normal maps is superior than other representations. In NormalGAN, an adversarial learning framework conditioned by normal maps is introduced, which is used to not only improve the front-view depth denoising performance, but also infer the back-view depth image with surprisingly geometric details. Moreover, for texture recovery, we remove shading information from the front-view RGB image based on the refined normal map, which further improves the quality of the back-view color inference. Results and experiments on both testing data set and real captured data demonstrate the superior performance of our approach. Given a consumer RGB-D sensor, NormalGAN can generate the complete and detailed 3D human reconstruction results in 20 fps, which further enables convenient interactive experiences in telepresence, AR/VR and gaming scenarios.
Improving Positive Unlabeled Learning: Practical AUL Estimation and New Training Method for Extremely Imbalanced Data Sets
Apr 21, 2020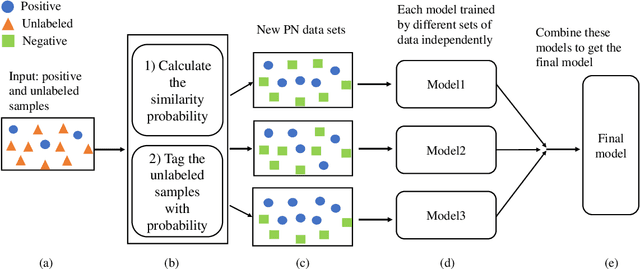
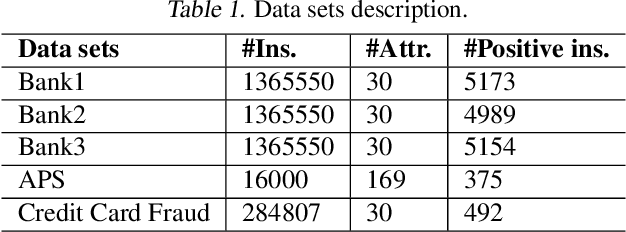
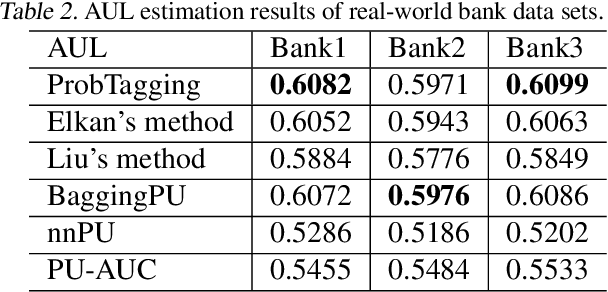
Positive Unlabeled (PU) learning is widely used in many applications, where a binary classifier is trained on the datasets consisting of only positive and unlabeled samples. In this paper, we improve PU learning over state-of-the-art from two aspects. Firstly, existing model evaluation methods for PU learning requires ground truth of unlabeled samples, which is unlikely to be obtained in practice. In order to release this restriction, we propose an asymptotic unbiased practical AUL (area under the lift) estimation method, which makes use of raw PU data without prior knowledge of unlabeled samples. Secondly, we propose ProbTagging, a new training method for extremely imbalanced data sets, where the number of unlabeled samples is hundreds or thousands of times that of positive samples. ProbTagging introduces probability into the aggregation method. Specifically, each unlabeled sample is tagged positive or negative with the probability calculated based on the similarity to its positive neighbors. Based on this, multiple data sets are generated to train different models, which are then combined into an ensemble model. Compared to state-of-the-art work, the experimental results show that ProbTagging can increase the AUC by up to 10%, based on three industrial and two artificial PU data sets.