 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniPLV: Towards Label-Efficient Open-World 3D Scene Understanding by Regional Visual Language Supervision
Dec 24, 2024We present UniPLV, a powerful framework that unifies point clouds, images and text in a single learning paradigm for open-world 3D scene understanding. UniPLV employs the image modal as a bridge to co-embed 3D points with pre-aligned images and text in a shared feature space without requiring carefully crafted point cloud text pairs. To accomplish multi-modal alignment, we propose two key strategies:(i) logit and feature distillation modules between images and point clouds, and (ii) a vison-point matching module is given to explicitly correct the misalignment caused by points to pixels projection. To further improve the performance of our unified framework, we adopt four task-specific losses and a two-stage training strategy. Extensive experiments show that our method outperforms the state-of-the-art methods by an average of 15.6% and 14.8% for semantic segmentation over Base-Annotated and Annotation-Free tasks, respectively. The code will be released later.
Benchmarking the CoW with the TopCoW Challenge: Topology-Aware Anatomical Segmentation of the Circle of Willis for CTA and MRA
Dec 29, 2023



The Circle of Willis (CoW) is an important network of arteries connecting major circulations of the brain. Its vascular architecture is believed to affect the risk, severity, and clinical outcome of serious neuro-vascular diseases. However, characterizing the highly variable CoW anatomy is still a manual and time-consuming expert task. The CoW is usually imaged by two angiographic imaging modalities, magnetic resonance angiography (MRA) and computed tomography angiography (CTA), but there exist limited public datasets with annotations on CoW anatomy, especially for CTA. Therefore we organized the TopCoW Challenge in 2023 with the release of an annotated CoW dataset and invited submissions worldwide for the CoW segmentation task, which attracted over 140 registered participants from four continents. TopCoW dataset was the first public dataset with voxel-level annotations for CoW's 13 vessel components, made possible by virtual-reality (VR) technology. It was also the first dataset with paired MRA and CTA from the same patients. TopCoW challenge aimed to tackle the CoW characterization problem as a multiclass anatomical segmentation task with an emphasis on topological metrics. The top performing teams managed to segment many CoW components to Dice scores around 90%, but with lower scores for communicating arteries and rare variants. There were also topological mistakes for predictions with high Dice scores. Additional topological analysis revealed further areas for improvement in detecting certain CoW components and matching CoW variant's topology accurately. TopCoW represented a first attempt at benchmarking the CoW anatomical segmentation task for MRA and CTA, both morphologically and topologically.
MAFF-Net: Filter False Positive for 3D Vehicle Detection with Multi-modal Adaptive Feature Fusion
Sep 23, 2020

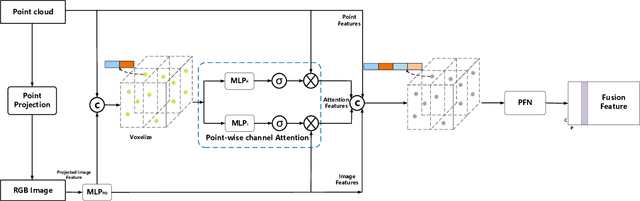
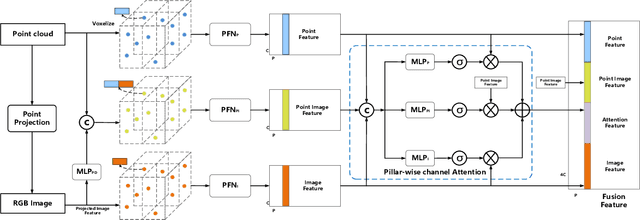
3D vehicle detection based on multi-modal fusion is an important task of many applications such as autonomous driving. Although significant progress has been made, we still observe two aspects that need to be further improvement: First, the specific gain that camera images can bring to 3D detection is seldom explored by previous works. Second, many fusion algorithms run slowly, which is essential for applications with high real-time requirements(autonomous driving). To this end, we propose an end-to-end trainable single-stage multi-modal feature adaptive network in this paper, which uses image information to effectively reduce false positive of 3D detection and has a fast detection speed. A multi-modal adaptive feature fusion module based on channel attention mechanism is proposed to enable the network to adaptively use the feature of each modal. Based on the above mechanism, two fusion technologies are proposed to adapt to different usage scenarios: PointAttentionFusion is suitable for filtering simple false positive and faster; DenseAttentionFusion is suitable for filtering more difficult false positive and has better overall performance. Experimental results on the KITTI dataset demonstrate significant improvement in filtering false positive over the approach using only point cloud data. Furthermore, the proposed method can provide competitive results and has the fastest speed compared to the published state-of-the-art multi-modal methods in the KITTI benchmark.
RangeRCNN: Towards Fast and Accurate 3D Object Detection with Range Image Representation
Sep 01, 2020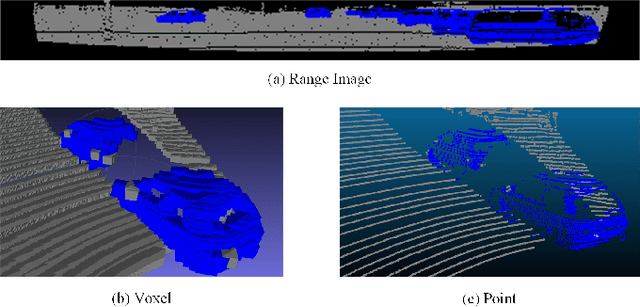

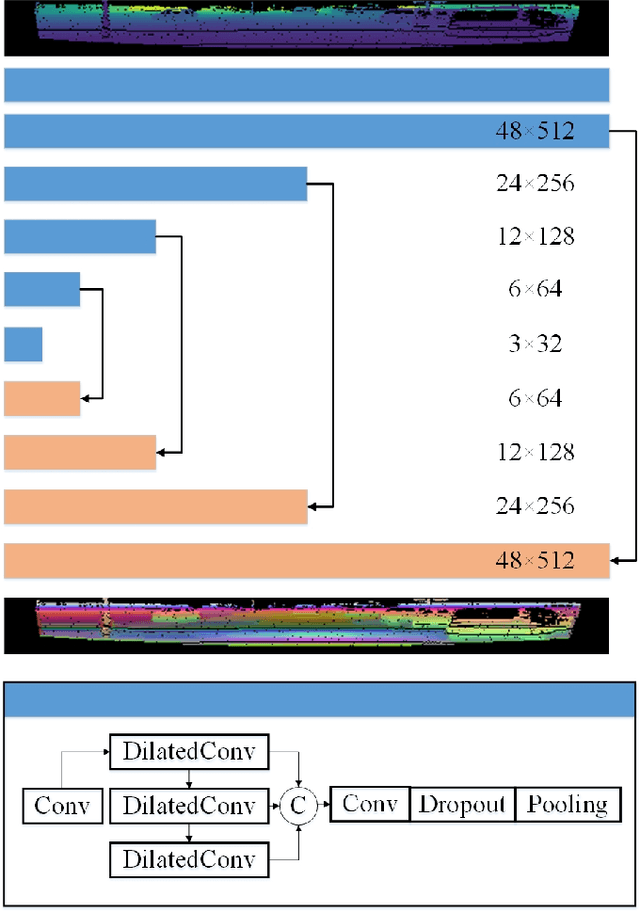

We present RangeRCNN, a novel and effective 3D object detection framework based on the range image representation. Most existing 3D object detection methods are either voxel-based or point-based. Though several optimizations have been introduced to ease the sparsity issue and speed up the running time, the two representations are still computationally inefficient. Compared to these two representations, the range image representation is dense and compact which can exploit the powerful 2D convolution and avoid the uncertain receptive field caused by the sparsity issue. Even so, the range image representation is not preferred in 3D object detection due to the scale variation and occlusion. In this paper, we utilize the dilated residual block to better adapt different object scales and obtain a more flexible receptive field on range image. Considering the scale variation and occlusion of the range image, we propose the RV-PV-BEV~(Range View to Point View to Bird's Eye View) module to transfer the feature from the range view to the bird's eye view. The anchor is defined in the BEV space which avoids the scale variation and occlusion. Both RV and BEV cannot provide enough information for height estimation, so we propose a two-stage RCNN for better 3D detection performance. The point view aforementioned does not only serve as a bridge from RV to BEV but also provides pointwise features for RCNN. Extensive experiments show that the proposed RangeRCNN achieves state-of-the-art performance on the KITTI 3D object detection dataset. We prove that the range image based methods can be effective on the KITTI dataset which provides more possibilities for real-time 3D object detection.