 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAFF-Net: Filter False Positive for 3D Vehicle Detection with Multi-modal Adaptive Feature Fusion
Sep 23, 2020

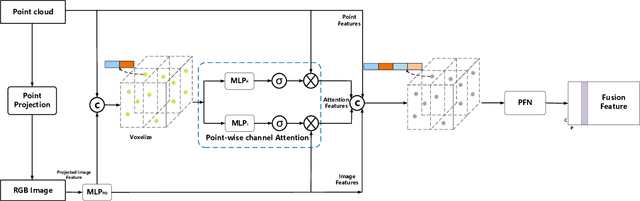
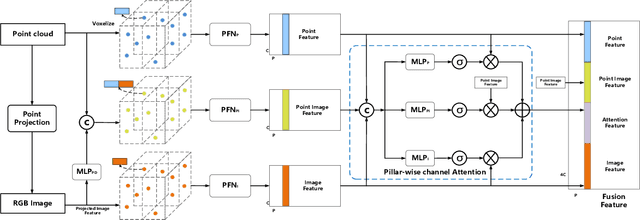
3D vehicle detection based on multi-modal fusion is an important task of many applications such as autonomous driving. Although significant progress has been made, we still observe two aspects that need to be further improvement: First, the specific gain that camera images can bring to 3D detection is seldom explored by previous works. Second, many fusion algorithms run slowly, which is essential for applications with high real-time requirements(autonomous driving). To this end, we propose an end-to-end trainable single-stage multi-modal feature adaptive network in this paper, which uses image information to effectively reduce false positive of 3D detection and has a fast detection speed. A multi-modal adaptive feature fusion module based on channel attention mechanism is proposed to enable the network to adaptively use the feature of each modal. Based on the above mechanism, two fusion technologies are proposed to adapt to different usage scenarios: PointAttentionFusion is suitable for filtering simple false positive and faster; DenseAttentionFusion is suitable for filtering more difficult false positive and has better overall performance. Experimental results on the KITTI dataset demonstrate significant improvement in filtering false positive over the approach using only point cloud data. Furthermore, the proposed method can provide competitive results and has the fastest speed compared to the published state-of-the-art multi-modal methods in the KITTI benchmark.
RangeRCNN: Towards Fast and Accurate 3D Object Detection with Range Image Representation
Sep 01, 2020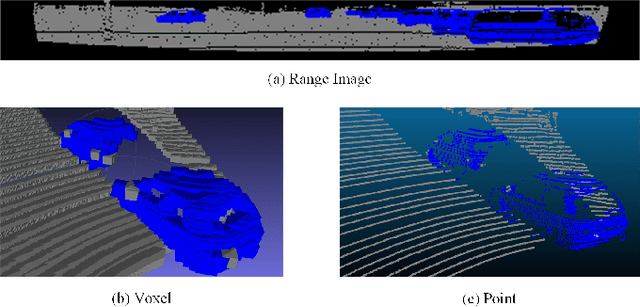

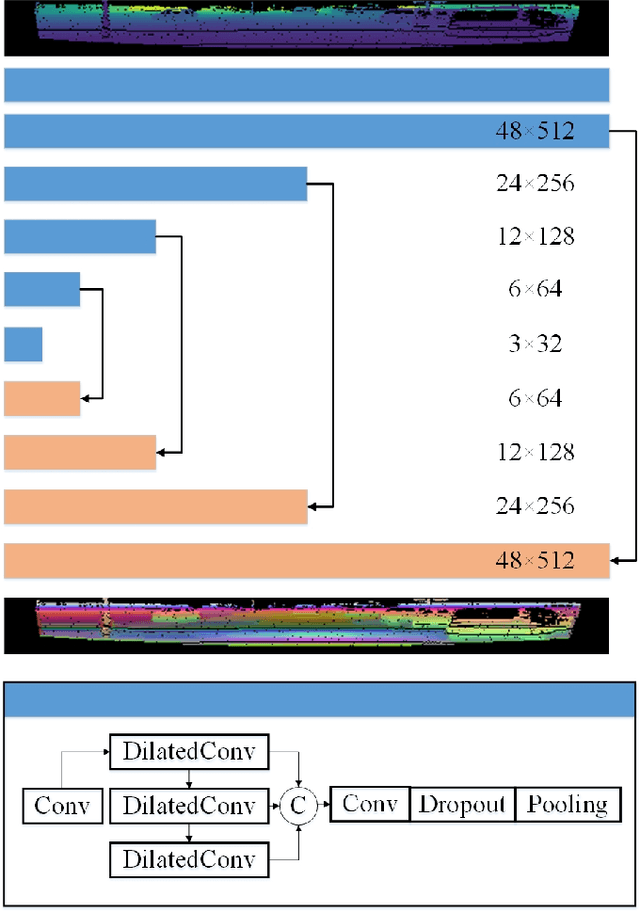

We present RangeRCNN, a novel and effective 3D object detection framework based on the range image representation. Most existing 3D object detection methods are either voxel-based or point-based. Though several optimizations have been introduced to ease the sparsity issue and speed up the running time, the two representations are still computationally inefficient. Compared to these two representations, the range image representation is dense and compact which can exploit the powerful 2D convolution and avoid the uncertain receptive field caused by the sparsity issue. Even so, the range image representation is not preferred in 3D object detection due to the scale variation and occlusion. In this paper, we utilize the dilated residual block to better adapt different object scales and obtain a more flexible receptive field on range image. Considering the scale variation and occlusion of the range image, we propose the RV-PV-BEV~(Range View to Point View to Bird's Eye View) module to transfer the feature from the range view to the bird's eye view. The anchor is defined in the BEV space which avoids the scale variation and occlusion. Both RV and BEV cannot provide enough information for height estimation, so we propose a two-stage RCNN for better 3D detection performance. The point view aforementioned does not only serve as a bridge from RV to BEV but also provides pointwise features for RCNN. Extensive experiments show that the proposed RangeRCNN achieves state-of-the-art performance on the KITTI 3D object detection dataset. We prove that the range image based methods can be effective on the KITTI dataset which provides more possibilities for real-time 3D object detection.
3D Graph Embedding Learning with a Structure-aware Loss Function for Point Cloud Semantic Instance Segmentation
Feb 14, 2019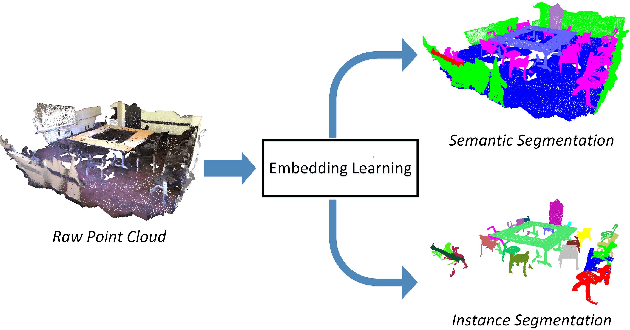


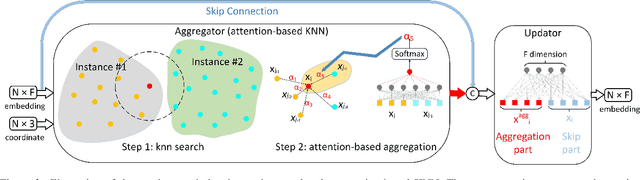
This paper introduces a novel approach for 3D semantic instance segmentation on point clouds. A 3D convolutional neural network called submanifold sparse convolutional network is used to generate semantic predictions and instance embeddings simultaneously. To obtain discriminative embeddings for each 3D instance, a structure-aware loss function is proposed which considers both the structure information and the embedding information. To get more consistent embeddings for each 3D instance, attention-based k nearest neighbour (KNN) is proposed to assign different weights for different neighbours. Based on the attention-based KNN, we add a graph convolutional network after the sparse convolutional network to get refined embeddings. Our network can be trained end-to-end. A simple mean-shift algorithm is utilized to cluster refined embeddings to get final instance predictions. As a result, our framework can output both the semantic prediction and the instance prediction. Experiments show that our approach outperforms all state-of-art methods on ScanNet benchmark and NYUv2 dataset.