 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Reinforcement Learning for Large Reasoning Models
Sep 10, 2025In this paper, we survey recent advances in Reinforcement Learning (RL) for reasoning with Large Language Models (LLMs). RL has achieved remarkable success in advancing the frontier of LLM capabilities, particularly in addressing complex logical tasks such as mathematics and coding. As a result, RL has emerged as a foundational methodology for transforming LLMs into LRMs. With the rapid progress of the field, further scaling of RL for LRMs now faces foundational challenges not only in computational resources but also in algorithm design, training data, and infrastructure. To this end, it is timely to revisit the development of this domain, reassess its trajectory, and explore strategies to enhance the scalability of RL toward Artificial SuperIntelligence (ASI). In particular, we examine research applying RL to LLMs and LRMs for reasoning abilities, especially since the release of DeepSeek-R1, including foundational components, core problems, training resources, and downstream applications, to identify future opportunities and directions for this rapidly evolving area. We hope this review will promote future research on RL for broader reasoning models. Github: https://github.com/TsinghuaC3I/Awesome-RL-for-LRMs
UniPLV: Towards Label-Efficient Open-World 3D Scene Understanding by Regional Visual Language Supervision
Dec 24, 2024We present UniPLV, a powerful framework that unifies point clouds, images and text in a single learning paradigm for open-world 3D scene understanding. UniPLV employs the image modal as a bridge to co-embed 3D points with pre-aligned images and text in a shared feature space without requiring carefully crafted point cloud text pairs. To accomplish multi-modal alignment, we propose two key strategies:(i) logit and feature distillation modules between images and point clouds, and (ii) a vison-point matching module is given to explicitly correct the misalignment caused by points to pixels projection. To further improve the performance of our unified framework, we adopt four task-specific losses and a two-stage training strategy. Extensive experiments show that our method outperforms the state-of-the-art methods by an average of 15.6% and 14.8% for semantic segmentation over Base-Annotated and Annotation-Free tasks, respectively. The code will be released later.
Empirical Bayesian Approaches for Robust Constraint-based Causal Discovery under Insufficient Data
Jun 16, 2022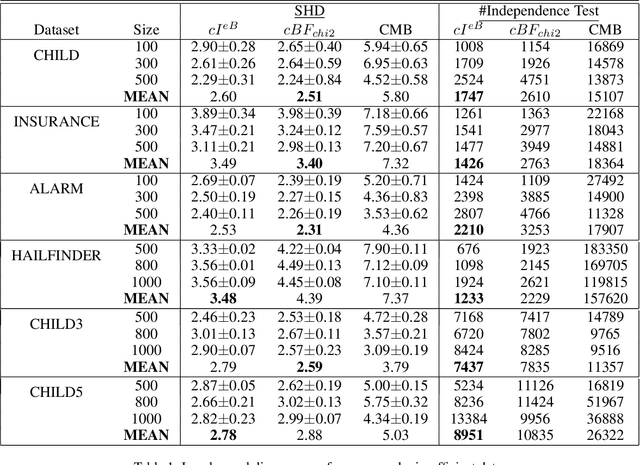
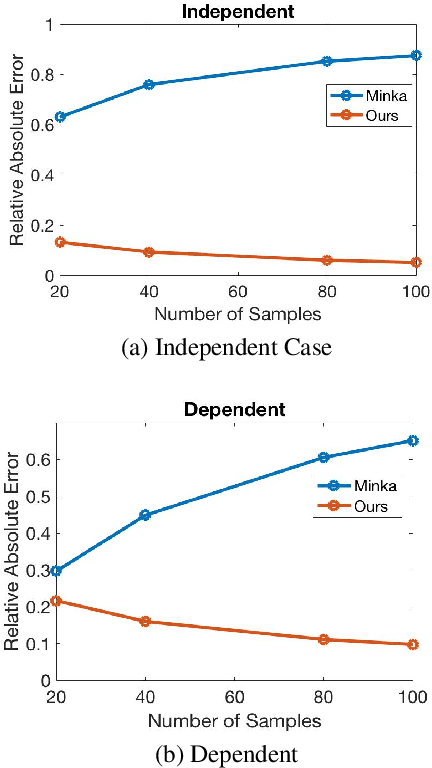
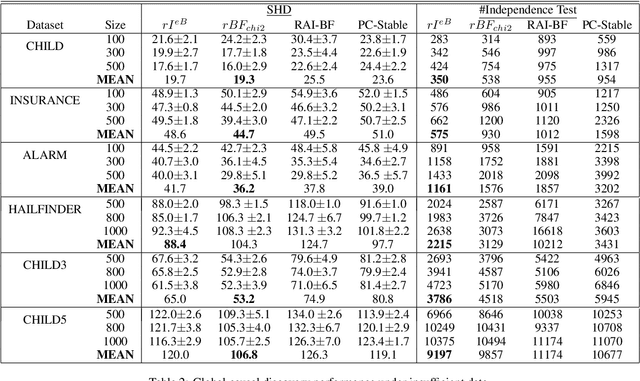
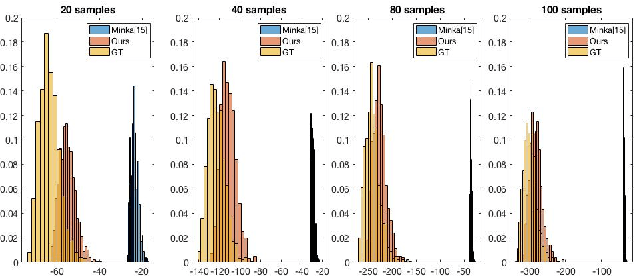
Causal discovery is to learn cause-effect relationships among variables given observational data and is important for many applications. Existing causal discovery methods assume data sufficiency, which may not be the case in many real world datasets. As a result, many existing causal discovery methods can fail under limited data. In this work, we propose Bayesian-augmented frequentist independence tests to improve the performance of constraint-based causal discovery methods under insufficient data: 1) We firstly introduce a Bayesian method to estimate mutual information (MI), based on which we propose a robust MI based independence test; 2) Secondly, we consider the Bayesian estimation of hypothesis likelihood and incorporate it into a well-defined statistical test, resulting in a robust statistical testing based independence test. We apply proposed independence tests to constraint-based causal discovery methods and evaluate the performance on benchmark datasets with insufficient samples. Experiments show significant performance improvement in terms of both accuracy and efficiency over SOTA methods.