 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRational Sparse Autoencoder
Jun 16, 2026Sparse autoencoders (SAEs) are standard tools for mechanistic interpretability, but current SAE families are constrained by fixed encoder nonlinearities such as ReLU, JumpReLU, and TopK. This hard-codes a particular sparsity mechanism into the model and can distort the reconstruction-versus-sparsity trade-off. We introduce the Rational Sparse Autoencoder (RSAE), which replaces the fixed encoder activation with a trainable rational function. Rational activations are flexible enough to uniformly approximate the activation primitives used by existing SAE families on compact domains (for TopK, the thresholded gate obtained after a separating top-k threshold is supplied), while also providing a richer function class for adapting to the observed pre-activation geometry. We realise this idea through a two-stage pipeline: an initialisation procedure that copies the pre-trained baseline SAE weights, plugs in rational coefficients obtained by the relaxed Remez exchange on synthetic data, and calibrates the scale parameters along with the rational coefficients; followed by a fine-tuning step under the standard sparsity-regularised reconstruction objective. Empirically, on residual-stream activations of three open-weight language models and across all three baseline activation families, the RSAE strictly improves on it after the fine-tuning step, both on reconstruction-side metrics and on downstream-behaviour metrics, without sacrificing feature-level interpretability under sparse probing. These gains are consistent across host language models, across baseline activation families, and across the full range of baseline sparsity we tested, while the upgrade itself adds only a handful of scalar parameters per autoencoder and runs in minutes on a single consumer GPU.
Scalable Circuit Learning for Interpreting Large Language Models
Jun 15, 2026A prominent research direction in mechanistic interpretability is learning sparse circuits over LLM components to reveal how they jointly produce model behavior. However, raw neurons are polysemantic, making learned circuits hard to interpret. Sparse autoencoder (SAE) features alleviate this, but their high dimensionality makes existing intervention-based circuit learning methods computationally prohibitive. We propose CircuitLasso, a scalable circuit-learning approach based on sparse linear regression. CircuitLasso recovers circuits whose structural accuracy matches that of state-of-the-art intervention-based methods on the benchmark data, at a fraction of the computational cost. For interpretability, CircuitLasso efficiently uncovers relationships among SAE features, showing how human-interpretable semantic features propagate through the model and influence its predictions. Finally, we validate the utility of our learned circuits by leveraging their insights to achieve comparable performance at substantially lower cost on a domain-generalization task.
Causal Discovery under Identifiable Heteroscedastic Noise Model
Dec 20, 2023Capturing the underlying structural causal relations represented by Directed Acyclic Graphs (DAGs) has been a fundamental task in various AI disciplines. Causal DAG learning via the continuous optimization framework has recently achieved promising performance in terms of both accuracy and efficiency. However, most methods make strong assumptions of homoscedastic noise, i.e., exogenous noises have equal variances across variables, observations, or even both. The noises in real data usually violate both assumptions due to the biases introduced by different data collection processes. To address the issue of heteroscedastic noise, we introduce relaxed and implementable sufficient conditions, proving the identifiability of a general class of SEM subject to these conditions. Based on the identifiable general SEM, we propose a novel formulation for DAG learning that accounts for the variation in noise variance across variables and observations. We then propose an effective two-phase iterative DAG learning algorithm to address the increasing optimization difficulties and to learn a causal DAG from data with heteroscedastic variable noise under varying variance. We show significant empirical gains of the proposed approaches over state-of-the-art methods on both synthetic data and real data.
Empirical Bayesian Approaches for Robust Constraint-based Causal Discovery under Insufficient Data
Jun 16, 2022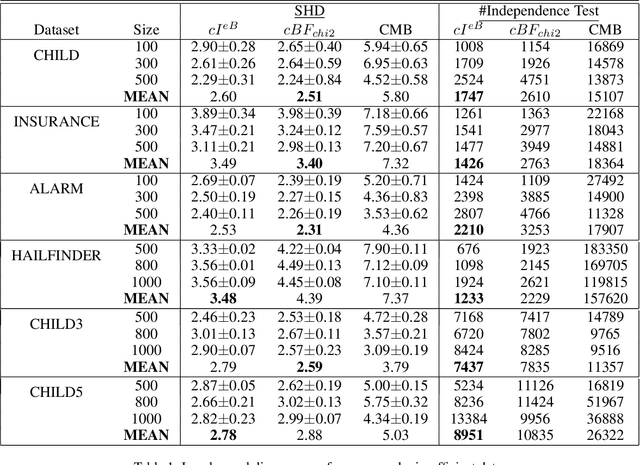
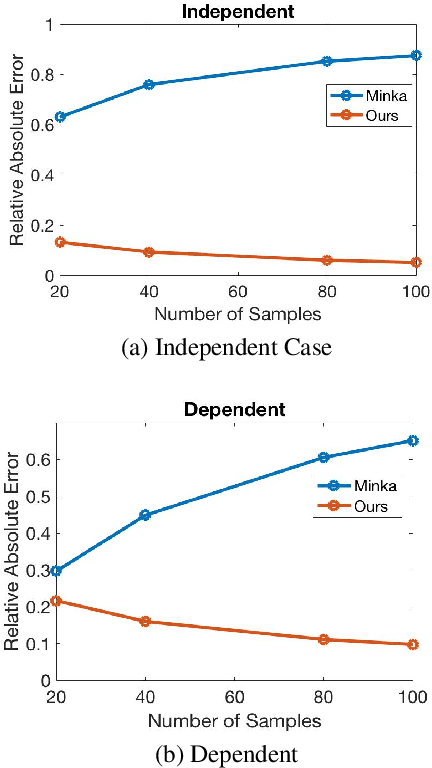
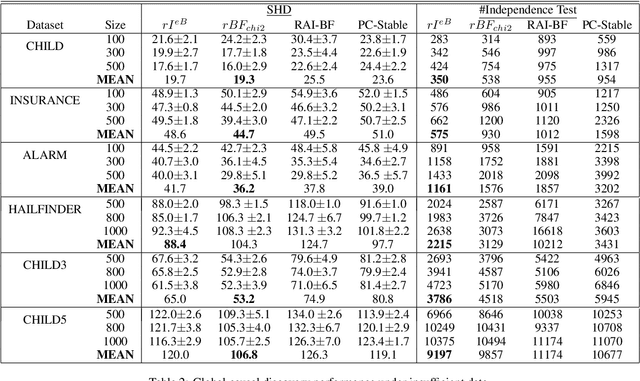
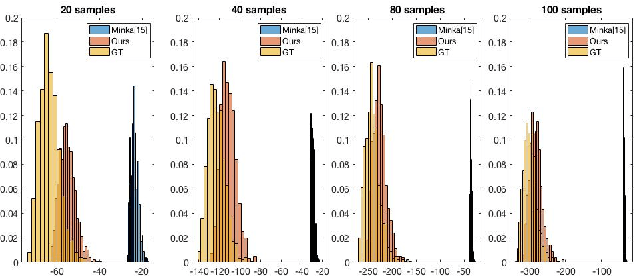
Causal discovery is to learn cause-effect relationships among variables given observational data and is important for many applications. Existing causal discovery methods assume data sufficiency, which may not be the case in many real world datasets. As a result, many existing causal discovery methods can fail under limited data. In this work, we propose Bayesian-augmented frequentist independence tests to improve the performance of constraint-based causal discovery methods under insufficient data: 1) We firstly introduce a Bayesian method to estimate mutual information (MI), based on which we propose a robust MI based independence test; 2) Secondly, we consider the Bayesian estimation of hypothesis likelihood and incorporate it into a well-defined statistical test, resulting in a robust statistical testing based independence test. We apply proposed independence tests to constraint-based causal discovery methods and evaluate the performance on benchmark datasets with insufficient samples. Experiments show significant performance improvement in terms of both accuracy and efficiency over SOTA methods.
DAGs with No Curl: An Efficient DAG Structure Learning Approach
Jun 14, 2021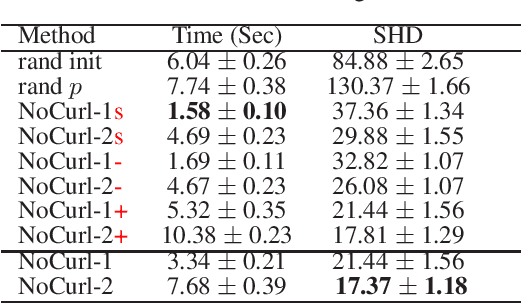
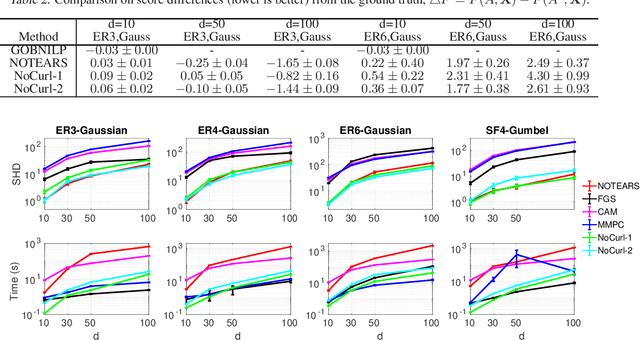
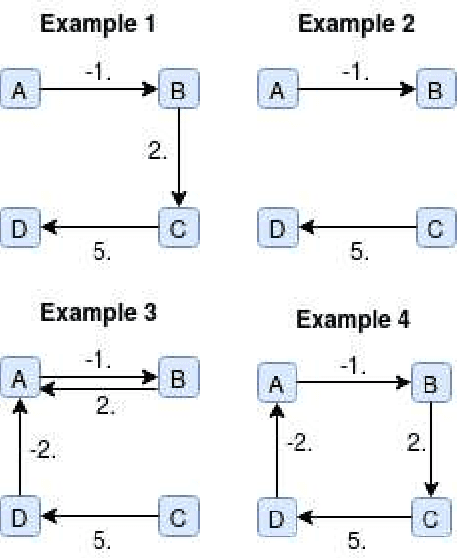
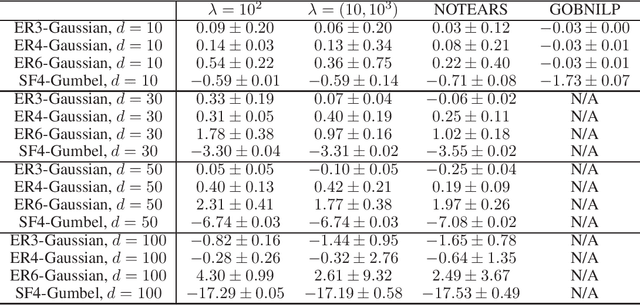
Recently directed acyclic graph (DAG) structure learning is formulated as a constrained continuous optimization problem with continuous acyclicity constraints and was solved iteratively through subproblem optimization. To further improve efficiency, we propose a novel learning framework to model and learn the weighted adjacency matrices in the DAG space directly. Specifically, we first show that the set of weighted adjacency matrices of DAGs are equivalent to the set of weighted gradients of graph potential functions, and one may perform structure learning by searching in this equivalent set of DAGs. To instantiate this idea, we propose a new algorithm, DAG-NoCurl, which solves the optimization problem efficiently with a two-step procedure: 1) first we find an initial cyclic solution to the optimization problem, and 2) then we employ the Hodge decomposition of graphs and learn an acyclic graph by projecting the cyclic graph to the gradient of a potential function. Experimental studies on benchmark datasets demonstrate that our method provides comparable accuracy but better efficiency than baseline DAG structure learning methods on both linear and generalized structural equation models, often by more than one order of magnitude.