 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrioritized Guidance for Efficient Multi-Agent Reinforcement Learning Exploration
Paper and Code
Jul 19, 2019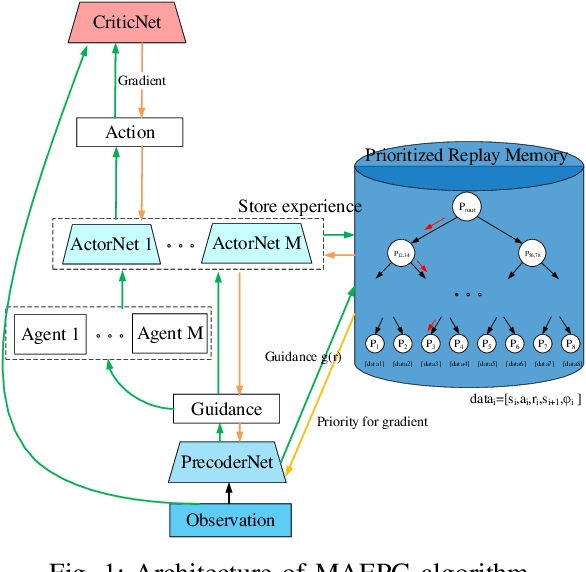
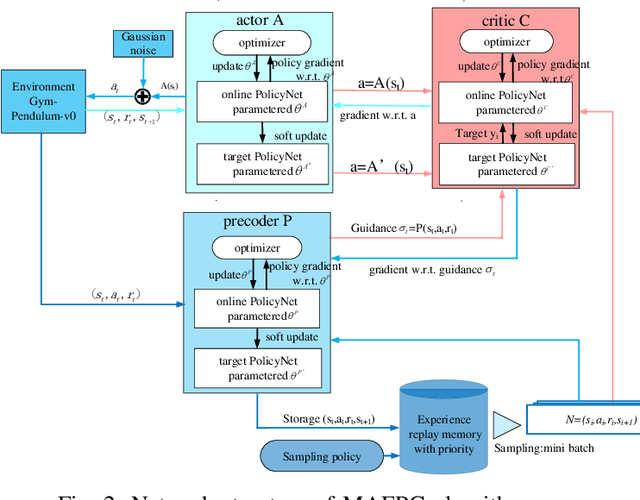

Exploration efficiency is a challenging problem in multi-agent reinforcement learning (MARL), as the policy learned by confederate MARL depends on the collaborative approach among multiple agents. Another important problem is the less informative reward restricts the learning speed of MARL compared with the informative label in supervised learning. In this work, we leverage on a novel communication method to guide MARL to accelerate exploration and propose a predictive network to forecast the reward of current state-action pair and use the guidance learned by the predictive network to modify the reward function. An improved prioritized experience replay is employed to better take advantage of the different knowledge learned by different agents which utilizes Time-difference (TD) error more effectively. Experimental results demonstrates that the proposed algorithm outperforms existing methods in cooperative multi-agent environments. We remark that this algorithm can be extended to supervised learning to speed up its training.