 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Energy: Detecting LLM Hallucination Beyond Entropy
Aug 20, 2025Large Language Models (LLMs) are being increasingly deployed in real-world applications, but they remain susceptible to hallucinations, which produce fluent yet incorrect responses and lead to erroneous decision-making. Uncertainty estimation is a feasible approach to detect such hallucinations. For example, semantic entropy estimates uncertainty by considering the semantic diversity across multiple sampled responses, thus identifying hallucinations. However, semantic entropy relies on post-softmax probabilities and fails to capture the model's inherent uncertainty, causing it to be ineffective in certain scenarios. To address this issue, we introduce Semantic Energy, a novel uncertainty estimation framework that leverages the inherent confidence of LLMs by operating directly on logits of penultimate layer. By combining semantic clustering with a Boltzmann-inspired energy distribution, our method better captures uncertainty in cases where semantic entropy fails. Experiments across multiple benchmarks show that Semantic Energy significantly improves hallucination detection and uncertainty estimation, offering more reliable signals for downstream applications such as hallucination detection.
A Novel Spreading-Factor-Index-Aided LoRa Scheme: Design and Performance Analysis
Jun 07, 2025LoRa is a widely recognized modulation technology in the field of low power wide area networks (LPWANs). However, the data rate of LoRa is too low to satisfy the requirements in the context of modern Internet of Things (IoT) applications. To address this issue, we propose a novel high-data-rate LoRa scheme based on the spreading factor index (SFI). In the proposed SFI-LoRa scheme, the starting frequency bin (SFB) of chirp signals is used to transmit information bits, while the combinations of spreading factors (SFs) are exploited as a set of indices to convey additional information bits. Moreover, theoretical expressions for the symbol error rate (SER) and throughput of the proposed SFI-LoRa scheme are derived over additive white Gaussian noise (AWGN) and Rayleigh fading channels. Simulation results not only verify the accuracy of the theoretical analysis, but also demonstrate that the proposed SFI-LoRa scheme improves both the bit error rate (BER) and throughput performance compared to existing high-data-rate LoRa schemes. Therefore, the proposed SFI-LoRa scheme is a potential solution for applications requiring a high data rate in the LPWAN domain.
Exploring Task-Level Optimal Prompts for Visual In-Context Learning
Jan 15, 2025With the development of Vision Foundation Models (VFMs) in recent years, Visual In-Context Learning (VICL) has become a better choice compared to modifying models in most scenarios. Different from retraining or fine-tuning model, VICL does not require modifications to the model's weights or architecture, and only needs a prompt with demonstrations to teach VFM how to solve tasks. Currently, significant computational cost for finding optimal prompts for every test sample hinders the deployment of VICL, as determining which demonstrations to use for constructing prompts is very costly. In this paper, however, we find a counterintuitive phenomenon that most test samples actually achieve optimal performance under the same prompts, and searching for sample-level prompts only costs more time but results in completely identical prompts. Therefore, we propose task-level prompting to reduce the cost of searching for prompts during the inference stage and introduce two time-saving yet effective task-level prompt search strategies. Extensive experimental results show that our proposed method can identify near-optimal prompts and reach the best VICL performance with a minimal cost that prior work has never achieved.
Scaling Law for Time Series Forecasting
May 27, 2024



Scaling law that rewards large datasets, complex models and enhanced data granularity has been observed in various fields of deep learning. Yet, studies on time series forecasting have cast doubt on scaling behaviors of deep learning methods for time series forecasting: while more training data improves performance, more capable models do not always outperform less capable models, and longer input horizons may hurt performance for some models. We propose a theory for scaling law for time series forecasting that can explain these seemingly abnormal behaviors. We take into account the impact of dataset size and model complexity, as well as time series data granularity, particularly focusing on the look-back horizon, an aspect that has been unexplored in previous theories. Furthermore, we empirically evaluate various models using a diverse set of time series forecasting datasets, which (1) verifies the validity of scaling law on dataset size and model complexity within the realm of time series forecasting, and (2) validates our theoretical framework, particularly regarding the influence of look back horizon. We hope our findings may inspire new models targeting time series forecasting datasets of limited size, as well as large foundational datasets and models for time series forecasting in future works.\footnote{Codes for our experiments will be made public at: \url{https://github.com/JingzheShi/ScalingLawForTimeSeriesForecasting}.
CHOPS: CHat with custOmer Profile Systems for Customer Service with LLMs
Apr 15, 2024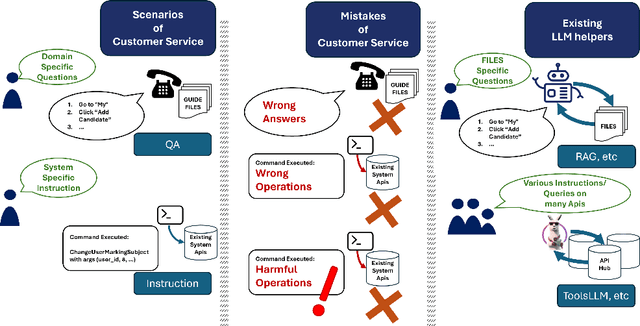

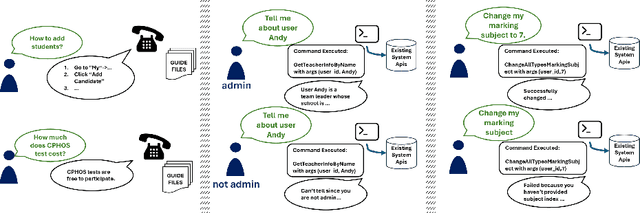

Businesses and software platforms are increasingly turning to Large Language Models (LLMs) such as GPT-3.5, GPT-4, GLM-3, and LLaMa-2 for chat assistance with file access or as reasoning agents for customer service. However, current LLM-based customer service models have limited integration with customer profiles and lack the operational capabilities necessary for effective service. Moreover, existing API integrations emphasize diversity over the precision and error avoidance essential in real-world customer service scenarios. To address these issues, we propose an LLM agent named CHOPS (CHat with custOmer Profile in existing System), designed to: (1) efficiently utilize existing databases or systems for accessing user information or interacting with these systems following existing guidelines; (2) provide accurate and reasonable responses or carry out required operations in the system while avoiding harmful operations; and (3) leverage a combination of small and large LLMs to achieve satisfying performance at a reasonable inference cost. We introduce a practical dataset, the CPHOS-dataset, which includes a database, guiding files, and QA pairs collected from CPHOS, an online platform that facilitates the organization of simulated Physics Olympiads for high school teachers and students. We have conducted extensive experiments to validate the performance of our proposed CHOPS architecture using the CPHOS-dataset, with the aim of demonstrating how LLMs can enhance or serve as alternatives to human customer service. Code for our proposed architecture and dataset can be found at {https://github.com/JingzheShi/CHOPS}.
Invariant Test-Time Adaptation for Vision-Language Model Generalization
Mar 01, 2024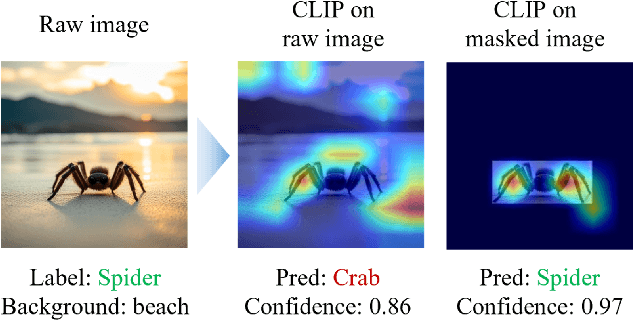

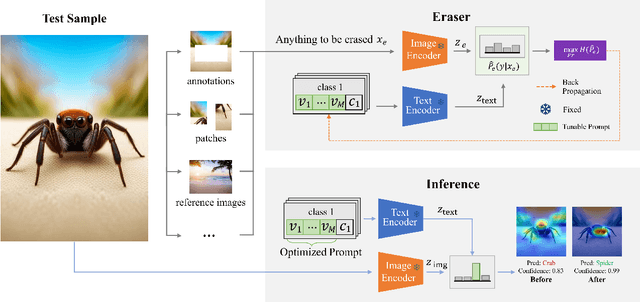

Vision-language foundation models have exhibited remarkable success across a multitude of downstream tasks due to their scalability on extensive image-text paired datasets. However, these models display significant limitations when applied to long-tail tasks, such as fine-grained image classification, as a result of "decision shortcuts" that hinders their generalization capabilities. In this work, we find that the CLIP model possesses a rich set of features, encompassing both \textit{desired invariant causal features} and \textit{undesired decision shortcuts}. Moreover, the underperformance of CLIP on downstream tasks originates from its inability to effectively utilize pre-trained features in accordance with specific task requirements. To address this challenge, this paper introduces a test-time prompt tuning paradigm that optimizes a learnable prompt, thereby compelling the model to exploit genuine causal invariant features while disregarding decision shortcuts during the inference phase. The proposed method effectively alleviates excessive dependence on potentially misleading, task-irrelevant contextual information, while concurrently emphasizing critical, task-related visual cues. We conduct comparative analysis of the proposed method against various approaches which validates its effectiveness.
PT-Tuning: Bridging the Gap between Time Series Masked Reconstruction and Forecasting via Prompt Token Tuning
Nov 07, 2023Self-supervised learning has been actively studied in time series domain recently, especially for masked reconstruction. Most of these methods follow the "Pre-training + Fine-tuning" paradigm in which a new decoder replaces the pre-trained decoder to fit for a specific downstream task, leading to inconsistency of upstream and downstream tasks. In this paper, we first point out that the unification of task objectives and adaptation for task difficulty are critical for bridging the gap between time series masked reconstruction and forecasting. By reserving the pre-trained mask token during fine-tuning stage, the forecasting task can be taken as a special case of masked reconstruction, where the future values are masked and reconstructed based on history values. It guarantees the consistency of task objectives but there is still a gap in task difficulty. Because masked reconstruction can utilize contextual information while forecasting can only use historical information to reconstruct. To further mitigate the existed gap, we propose a simple yet effective prompt token tuning (PT-Tuning) paradigm, in which all pre-trained parameters are frozen and only a few trainable prompt tokens are added to extended mask tokens in element-wise manner. Extensive experiments on real-world datasets demonstrate the superiority of our proposed paradigm with state-of-the-art performance compared to representation learning and end-to-end supervised forecasting methods.
Adapting Large Language Models for Content Moderation: Pitfalls in Data Engineering and Supervised Fine-tuning
Oct 05, 2023Nowadays, billions of people engage in communication and express their opinions on the internet daily. Unfortunately, not all of these expressions are friendly or compliant, making content moderation an indispensable task. With the successful development of Large Language Models (LLMs) in recent years, LLM-based methods have become a feasible solution for handling tasks in various domains. However, in the field of content moderation, there is still a lack of detailed work that systematically introduces implementation details. In this paper, we introduce how to fine-tune an LLM model that can be privately deployed for content moderation. Specifically, we discuss whether incorporating reasons during the fine-tuning process would be better or if it should be treated as a classification task directly. We also explore the benefits of utilizing reasons generated by more powerful LLMs for fine-tuning privately deployed models and the impact of different processing approaches when the answers generated by the more powerful LLMs are incorrect. We report the entire research process and the key findings in this paper, hoping to provide valuable experience for researchers who are fine-tuning privately deployed models in their domain-specific research.
Design of a New CIM-DCSK-Based Ambient Backscatter Communication System
Sep 05, 2023To improve the data rate in differential chaos shift keying (DCSK) based ambient backscatter communication (AmBC) system, we propose a new AmBC system based on code index modulation (CIM), referred to as CIM-DCSK-AmBC system. In the proposed system, the CIM-DCSK signal transmitted in the direct link is used as the radio frequency source of the backscatter link. The signal format in the backscatter link is designed to increase the data rate as well as eliminate the interference of the direct link signal. As such, the direct link signal and the backscatter link signal can be received and demodulated simultaneously. Moreover, we derive and validate the theoretical bit error rate (BER) expressions of the CIM-DCSK-AmBC system over multipath Rayleigh fading channels. Regarding the short reference DCSK-based AmBC (SR-DCSK-AmBC) system as a benchmark system, numerical results reveal that the CIM-DCSK-AmBC system can achieve better BER performance in the direct link and higher throughput in the backscatter link than the benchmark system.
Attention Paper: How Generative AI Reshapes Digital Shadow Industry?
May 26, 2023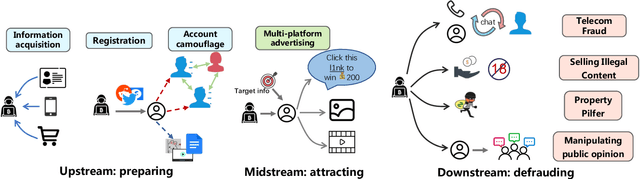
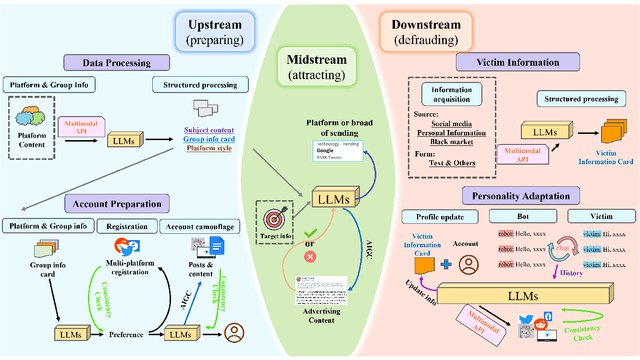

The rapid development of digital economy has led to the emergence of various black and shadow internet industries, which pose potential risks that can be identified and managed through digital risk management (DRM) that uses different techniques such as machine learning and deep learning. The evolution of DRM architecture has been driven by changes in data forms. However, the development of AI-generated content (AIGC) technology, such as ChatGPT and Stable Diffusion, has given black and shadow industries powerful tools to personalize data and generate realistic images and conversations for fraudulent activities. This poses a challenge for DRM systems to control risks from the source of data generation and to respond quickly to the fast-changing risk environment. This paper aims to provide a technical analysis of the challenges and opportunities of AIGC from upstream, midstream, and downstream paths of black/shadow industries and suggest future directions for improving existing risk control systems. The paper will explore the new black and shadow techniques triggered by generative AI technology and provide insights for building the next-generation DRM system.