 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvariant Test-Time Adaptation for Vision-Language Model Generalization
Paper and Code
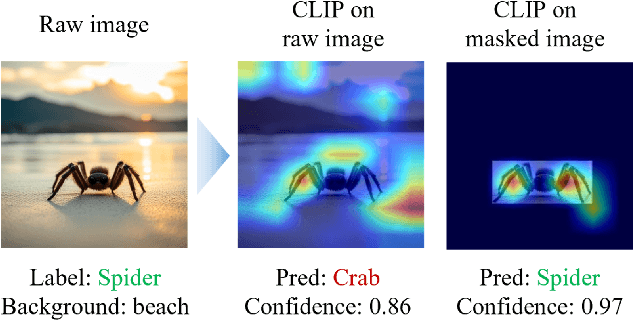

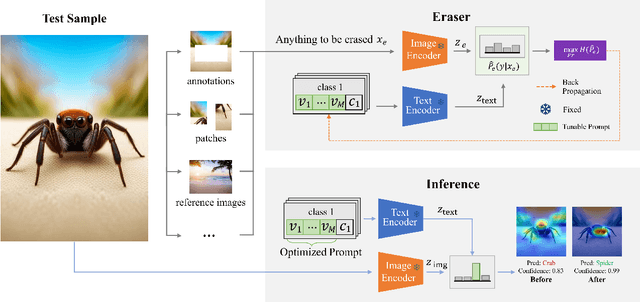

Vision-language foundation models have exhibited remarkable success across a multitude of downstream tasks due to their scalability on extensive image-text paired datasets. However, these models display significant limitations when applied to long-tail tasks, such as fine-grained image classification, as a result of "decision shortcuts" that hinders their generalization capabilities. In this work, we find that the CLIP model possesses a rich set of features, encompassing both \textit{desired invariant causal features} and \textit{undesired decision shortcuts}. Moreover, the underperformance of CLIP on downstream tasks originates from its inability to effectively utilize pre-trained features in accordance with specific task requirements. To address this challenge, this paper introduces a test-time prompt tuning paradigm that optimizes a learnable prompt, thereby compelling the model to exploit genuine causal invariant features while disregarding decision shortcuts during the inference phase. The proposed method effectively alleviates excessive dependence on potentially misleading, task-irrelevant contextual information, while concurrently emphasizing critical, task-related visual cues. We conduct comparative analysis of the proposed method against various approaches which validates its effectiveness.