 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemanticAudio: Audio Generation and Editing in Semantic Space
Jan 29, 2026In recent years, Text-to-Audio Generation has achieved remarkable progress, offering sound creators powerful tools to transform textual inspirations into vivid audio. However, existing models predominantly operate directly in the acoustic latent space of a Variational Autoencoder (VAE), often leading to suboptimal alignment between generated audio and textual descriptions. In this paper, we introduce SemanticAudio, a novel framework that conducts both audio generation and editing directly in a high-level semantic space. We define this semantic space as a compact representation capturing the global identity and temporal sequence of sound events, distinct from fine-grained acoustic details. SemanticAudio employs a two-stage Flow Matching architecture: the Semantic Planner first generates these compact semantic features to sketch the global semantic layout, and the Acoustic Synthesizer subsequently produces high-fidelity acoustic latents conditioned on this semantic plan. Leveraging this decoupled design, we further introduce a training-free text-guided editing mechanism that enables precise attribute-level modifications on general audio without retraining. Specifically, this is achieved by steering the semantic generation trajectory via the difference of velocity fields derived from source and target text prompts. Extensive experiments demonstrate that SemanticAudio surpasses existing mainstream approaches in semantic alignment. Demo available at: https://semanticaudio1.github.io/
MSR-Codec: A Low-Bitrate Multi-Stream Residual Codec for High-Fidelity Speech Generation with Information Disentanglement
Sep 16, 2025Audio codecs are a critical component of modern speech generation systems. This paper introduces a low-bitrate, multi-scale residual codec that encodes speech into four distinct streams: semantic, timbre, prosody, and residual. This architecture achieves high-fidelity speech reconstruction at competitive low bitrates while demonstrating an inherent ability for information disentanglement. We construct a two-stage language model for text-to-speech (TTS) synthesis using this codec, which, despite its lightweight design and minimal data requirements, achieves a state-of-the-art Word Error Rate (WER) and superior speaker similarity compared to several larger models. Furthermore, the codec's design proves highly effective for voice conversion, enabling independent manipulation of speaker timbre and prosody.
Emotion Omni: Enabling Empathetic Speech Response Generation through Large Language Models
Aug 26, 2025With the development of speech large language models (speech LLMs), users can now interact directly with assistants via speech. However, most existing models simply convert the response content into speech without fully understanding the rich emotional and paralinguistic cues embedded in the user's query. In many cases, the same sentence can have different meanings depending on the emotional expression. Furthermore, emotional understanding is essential for improving user experience in human-machine interaction. Currently, most speech LLMs with empathetic capabilities are trained on massive datasets. This approach requires vast amounts of data and significant computational resources. Therefore, a key challenge lies in how to develop a speech LLM capable of generating empathetic responses with limited data and without the need for large-scale training. To address this challenge, we propose Emotion Omni, a novel model architecture designed to understand the emotional content of user speech input and generate empathetic speech responses. Additionally, we developed a data generation pipeline based on an open-source TTS framework to construct a 200k emotional dialogue dataset, which supports the construction of an empathetic speech assistant. The demos are available at https://w311411.github.io/omni_demo/
Enhancing Expressive Voice Conversion with Discrete Pitch-Conditioned Flow Matching Model
Feb 08, 2025



This paper introduces PFlow-VC, a conditional flow matching voice conversion model that leverages fine-grained discrete pitch tokens and target speaker prompt information for expressive voice conversion (VC). Previous VC works primarily focus on speaker conversion, with further exploration needed in enhancing expressiveness (such as prosody and emotion) for timbre conversion. Unlike previous methods, we adopt a simple and efficient approach to enhance the style expressiveness of voice conversion models. Specifically, we pretrain a self-supervised pitch VQVAE model to discretize speaker-irrelevant pitch information and leverage a masked pitch-conditioned flow matching model for Mel-spectrogram synthesis, which provides in-context pitch modeling capabilities for the speaker conversion model, effectively improving the voice style transfer capacity. Additionally, we improve timbre similarity by combining global timbre embeddings with time-varying timbre tokens. Experiments on unseen LibriTTS test-clean and emotional speech dataset ESD show the superiority of the PFlow-VC model in both timbre conversion and style transfer. Audio samples are available on the demo page https://speechai-demo.github.io/PFlow-VC/.
Recent Advances in Speech Language Models: A Survey
Oct 01, 2024



Large Language Models (LLMs) have recently garnered significant attention, primarily for their capabilities in text-based interactions. However, natural human interaction often relies on speech, necessitating a shift towards voice-based models. A straightforward approach to achieve this involves a pipeline of ``Automatic Speech Recognition (ASR) + LLM + Text-to-Speech (TTS)", where input speech is transcribed to text, processed by an LLM, and then converted back to speech. Despite being straightforward, this method suffers from inherent limitations, such as information loss during modality conversion and error accumulation across the three stages. To address these issues, Speech Language Models (SpeechLMs) -- end-to-end models that generate speech without converting from text -- have emerged as a promising alternative. This survey paper provides the first comprehensive overview of recent methodologies for constructing SpeechLMs, detailing the key components of their architecture and the various training recipes integral to their development. Additionally, we systematically survey the various capabilities of SpeechLMs, categorize the evaluation metrics for SpeechLMs, and discuss the challenges and future research directions in this rapidly evolving field.
Enabling Beam Search for Language Model-Based Text-to-Speech Synthesis
Aug 29, 2024



Tokenising continuous speech into sequences of discrete tokens and modelling them with language models (LMs) has led to significant success in text-to-speech (TTS) synthesis. Although these models can generate speech with high quality and naturalness, their synthesised samples can still suffer from artefacts, mispronunciation, word repeating, etc. In this paper, we argue these undesirable properties could partly be caused by the randomness of sampling-based strategies during the autoregressive decoding of LMs. Therefore, we look at maximisation-based decoding approaches and propose Temporal Repetition Aware Diverse Beam Search (TRAD-BS) to find the most probable sequences of the generated speech tokens. Experiments with two state-of-the-art LM-based TTS models demonstrate that our proposed maximisation-based decoding strategy generates speech with fewer mispronunciations and improved speaker consistency.
Comparing normalizing flows and diffusion models for prosody and acoustic modelling in text-to-speech
Jul 31, 2023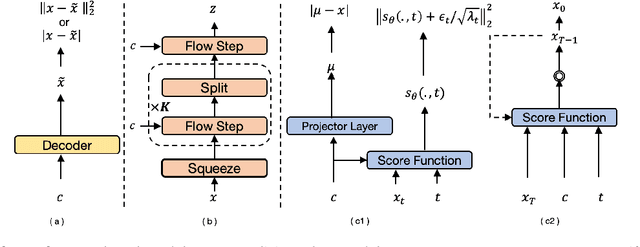
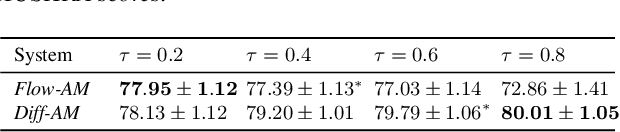
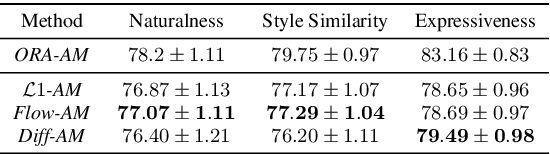
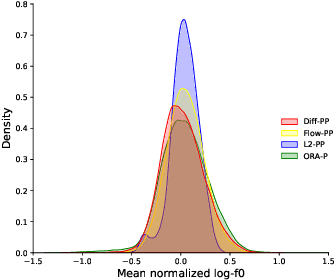
Neural text-to-speech systems are often optimized on L1/L2 losses, which make strong assumptions about the distributions of the target data space. Aiming to improve those assumptions, Normalizing Flows and Diffusion Probabilistic Models were recently proposed as alternatives. In this paper, we compare traditional L1/L2-based approaches to diffusion and flow-based approaches for the tasks of prosody and mel-spectrogram prediction for text-to-speech synthesis. We use a prosody model to generate log-f0 and duration features, which are used to condition an acoustic model that generates mel-spectrograms. Experimental results demonstrate that the flow-based model achieves the best performance for spectrogram prediction, improving over equivalent diffusion and L1 models. Meanwhile, both diffusion and flow-based prosody predictors result in significant improvements over a typical L2-trained prosody models.
Creating Personalized Synthetic Voices from Post-Glossectomy Speech with Guided Diffusion Models
May 27, 2023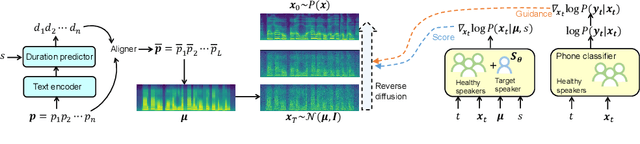
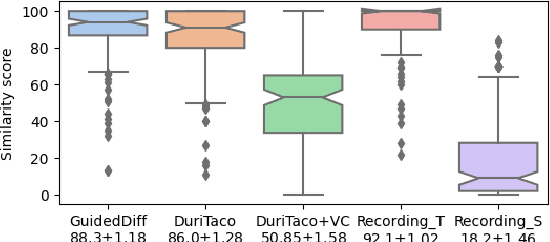
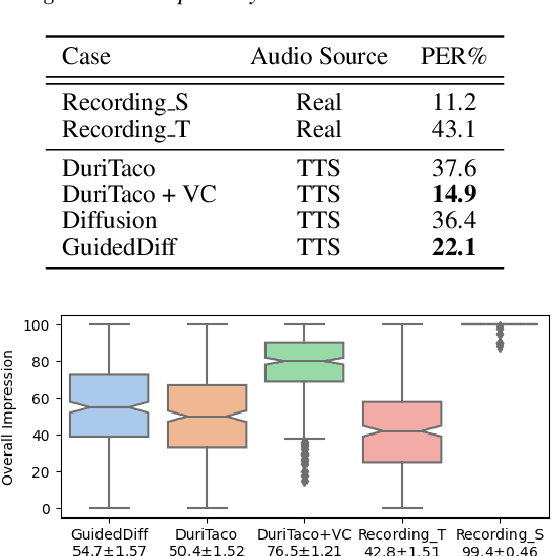
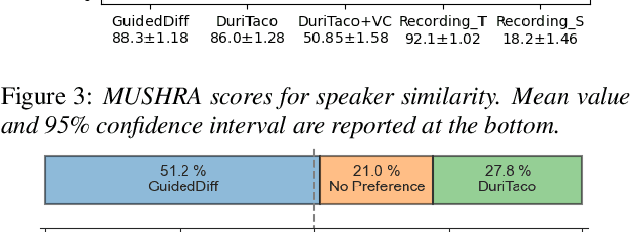
This paper is about developing personalized speech synthesis systems with recordings of mildly impaired speech. In particular, we consider consonant and vowel alterations resulted from partial glossectomy, the surgical removal of part of the tongue. The aim is to restore articulation in the synthesized speech and maximally preserve the target speaker's individuality. We propose to tackle the problem with guided diffusion models. Specifically, a diffusion-based speech synthesis model is trained on original recordings, to capture and preserve the target speaker's original articulation style. When using the model for inference, a separately trained phone classifier will guide the synthesis process towards proper articulation. Objective and subjective evaluation results show that the proposed method substantially improves articulation in the synthesized speech over original recordings, and preserves more of the target speaker's individuality than a voice conversion baseline.
iEmoTTS: Toward Robust Cross-Speaker Emotion Transfer and Control for Speech Synthesis based on Disentanglement between Prosody and Timbre
Jun 29, 2022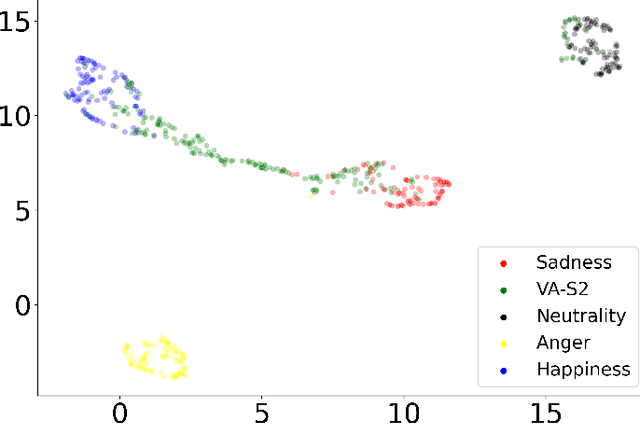
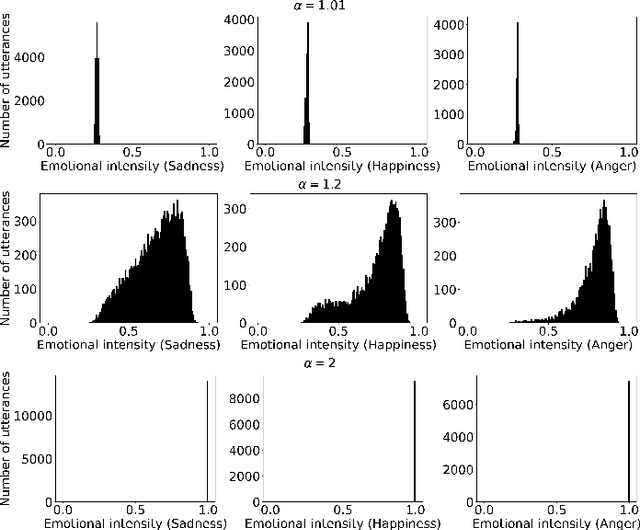
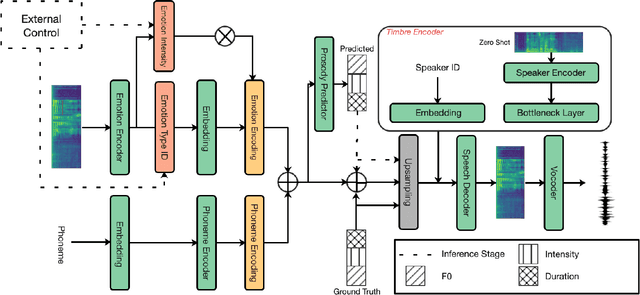
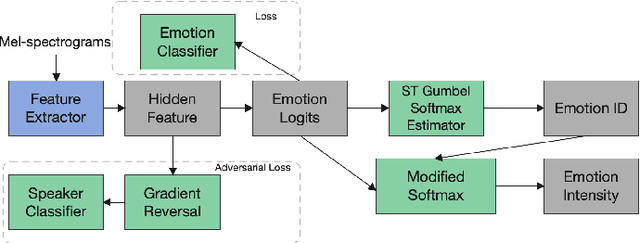
The capability of generating speech with specific type of emotion is desired for many applications of human-computer interaction. Cross-speaker emotion transfer is a common approach to generating emotional speech when speech with emotion labels from target speakers is not available for model training. This paper presents a novel cross-speaker emotion transfer system, named iEmoTTS. The system is composed of an emotion encoder, a prosody predictor, and a timbre encoder. The emotion encoder extracts the identity of emotion type as well as the respective emotion intensity from the mel-spectrogram of input speech. The emotion intensity is measured by the posterior probability that the input utterance carries that emotion. The prosody predictor is used to provide prosodic features for emotion transfer. The timber encoder provides timbre-related information for the system. Unlike many other studies which focus on disentangling speaker and style factors of speech, the iEmoTTS is designed to achieve cross-speaker emotion transfer via disentanglement between prosody and timbre. Prosody is considered as the main carrier of emotion-related speech characteristics and timbre accounts for the essential characteristics for speaker identification. Zero-shot emotion transfer, meaning that speech of target speakers are not seen in model training, is also realized with iEmoTTS. Extensive experiments of subjective evaluation have been carried out. The results demonstrate the effectiveness of iEmoTTS as compared with other recently proposed systems of cross-speaker emotion transfer. It is shown that iEmoTTS can produce speech with designated emotion type and controllable emotion intensity. With appropriate information bottleneck capacity, iEmoTTS is able to effectively transfer emotion information to a new speaker. Audio samples are publicly available\footnote{https://patrick-g-zhang.github.io/iemotts/}.
Mixed-Phoneme BERT: Improving BERT with Mixed Phoneme and Sup-Phoneme Representations for Text to Speech
Mar 31, 2022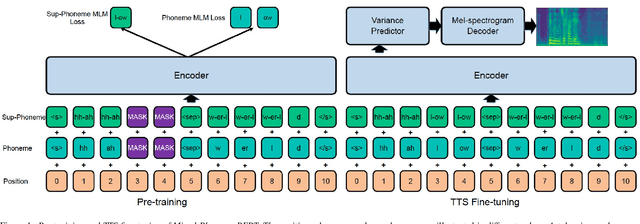
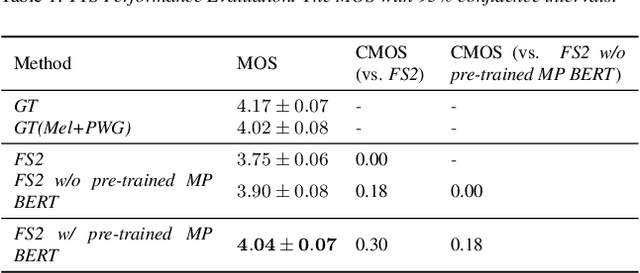

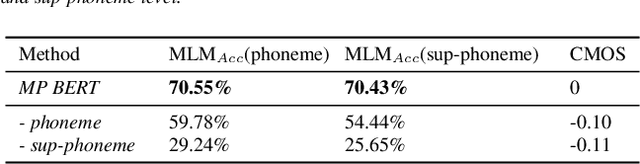
Recently, leveraging BERT pre-training to improve the phoneme encoder in text to speech (TTS) has drawn increasing attention. However, the works apply pre-training with character-based units to enhance the TTS phoneme encoder, which is inconsistent with the TTS fine-tuning that takes phonemes as input. Pre-training only with phonemes as input can alleviate the input mismatch but lack the ability to model rich representations and semantic information due to limited phoneme vocabulary. In this paper, we propose MixedPhoneme BERT, a novel variant of the BERT model that uses mixed phoneme and sup-phoneme representations to enhance the learning capability. Specifically, we merge the adjacent phonemes into sup-phonemes and combine the phoneme sequence and the merged sup-phoneme sequence as the model input, which can enhance the model capacity to learn rich contextual representations. Experiment results demonstrate that our proposed Mixed-Phoneme BERT significantly improves the TTS performance with 0.30 CMOS gain compared with the FastSpeech 2 baseline. The Mixed-Phoneme BERT achieves 3x inference speedup and similar voice quality to the previous TTS pre-trained model PnG BERT