 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
EGAM: Extended Graph Attention Model for Solving Routing Problems
Jan 29, 2026Neural combinatorial optimization (NCO) solvers, implemented with graph neural networks (GNNs), have introduced new approaches for solving routing problems. Trained with reinforcement learning (RL), the state-of-the-art graph attention model (GAM) achieves near-optimal solutions without requiring expert knowledge or labeled data. In this work, we generalize the existing graph attention mechanism and propose the extended graph attention model (EGAM). Our model utilizes multi-head dot-product attention to update both node and edge embeddings, addressing the limitations of the conventional GAM, which considers only node features. We employ an autoregressive encoder-decoder architecture and train it with policy gradient algorithms that incorporate a specially designed baseline. Experiments show that EGAM matches or outperforms existing methods across various routing problems. Notably, the proposed model demonstrates exceptional performance on highly constrained problems, highlighting its efficiency in handling complex graph structures.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
Kimi-VL Technical Report
Apr 10, 2025



We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities - all while activating only 2.8B parameters in its language decoder (Kimi-VL-A3B). Kimi-VL demonstrates strong performance across challenging domains: as a general-purpose VLM, Kimi-VL excels in multi-turn agent tasks (e.g., OSWorld), matching flagship models. Furthermore, it exhibits remarkable capabilities across diverse challenging vision language tasks, including college-level image and video comprehension, OCR, mathematical reasoning, and multi-image understanding. In comparative evaluations, it effectively competes with cutting-edge efficient VLMs such as GPT-4o-mini, Qwen2.5-VL-7B, and Gemma-3-12B-IT, while surpassing GPT-4o in several key domains. Kimi-VL also advances in processing long contexts and perceiving clearly. With a 128K extended context window, Kimi-VL can process diverse long inputs, achieving impressive scores of 64.5 on LongVideoBench and 35.1 on MMLongBench-Doc. Its native-resolution vision encoder, MoonViT, further allows it to see and understand ultra-high-resolution visual inputs, achieving 83.2 on InfoVQA and 34.5 on ScreenSpot-Pro, while maintaining lower computational cost for common tasks. Building upon Kimi-VL, we introduce an advanced long-thinking variant: Kimi-VL-Thinking. Developed through long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL), this model exhibits strong long-horizon reasoning capabilities. It achieves scores of 61.7 on MMMU, 36.8 on MathVision, and 71.3 on MathVista while maintaining the compact 2.8B activated LLM parameters, setting a new standard for efficient multimodal thinking models. Code and models are publicly accessible at https://github.com/MoonshotAI/Kimi-VL.
Boosting Deductive Reasoning with Step Signals In RLHF
Oct 12, 2024
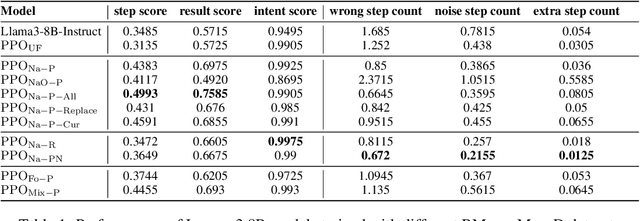


Logical reasoning is a crucial task for Large Language Models (LLMs), enabling them to tackle complex problems. Among reasoning tasks, multi-step reasoning poses a particular challenge. Grounded in the theory of formal logic, we have developed an automated method, Multi-step Deduction (MuseD), for deductive reasoning data. MuseD has allowed us to create training and testing datasets for multi-step reasoning. Our generation method enables control over the complexity of the generated instructions, facilitating training and evaluation of models across different difficulty levels. Through RLHF training, our training data has demonstrated significant improvements in logical capabilities for both in-domain of out-of-domain reasoning tasks. Additionally, we have conducted tests to assess the multi-step reasoning abilities of various models.
Uncertainty-aware Reward Model: Teaching Reward Models to Know What is Unknown
Oct 01, 2024Reward models (RM) play a critical role in aligning generations of large language models (LLM) to human expectations. However, prevailing RMs fail to capture the stochasticity within human preferences and cannot effectively evaluate the reliability of reward predictions. To address these issues, we propose Uncertain-aware RM (URM) and Uncertain-aware RM Ensemble (URME) to incorporate and manage uncertainty in reward modeling. URM can model the distribution of disentangled attributes within human preferences, while URME quantifies uncertainty through discrepancies in the ensemble, thereby identifying potential lack of knowledge during reward evaluation. Experiment results indicate that the proposed URM achieves state-of-the-art performance compared to models with the same size, demonstrating the effectiveness of modeling uncertainty within human preferences. Furthermore, empirical results show that through uncertainty quantification, URM and URME can identify unreliable predictions to improve the quality of reward evaluations.
3D-Properties: Identifying Challenges in DPO and Charting a Path Forward
Jun 11, 2024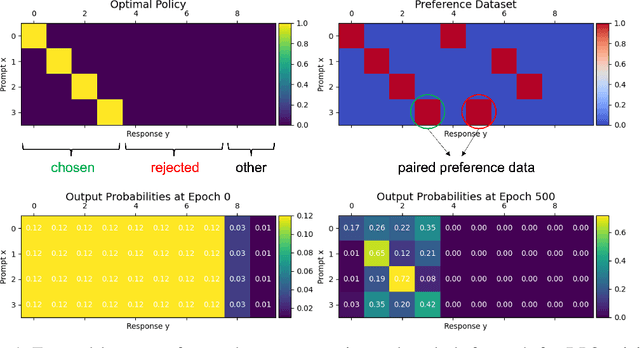
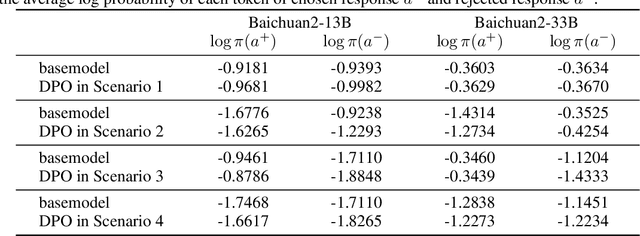
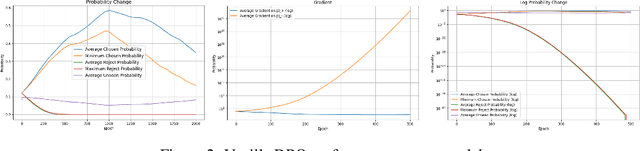
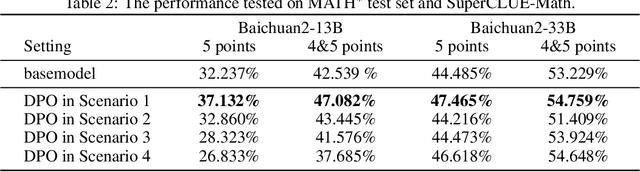
Aligning large language models (LLMs) with human preference has recently gained tremendous attention, with the canonical yet costly RLHF-PPO and the simple and straightforward Direct Preference Optimization (DPO) as two examples. Despite the efficiency, DPO has rarely be used in the state-of-the-art production-level LLMs, implying its potential pathologies. In this work, we revisit DPO with a comprehensive examination of its empirical efficacy and a systematic comparison with RLHF-PPO. We identify the \textbf{3D}-properties of DPO's learning outcomes: the \textbf{D}rastic drop in the likelihood of rejected responses, the \textbf{D}egradation into LLM unlearning, and the \textbf{D}ispersion effect on unseen responses through experiments with both a carefully designed toy model and practical LLMs on tasks including mathematical problem-solving and instruction following. These findings inherently connect to some observations made by related works and we additionally contribute a plausible theoretical explanation for them. Accordingly, we propose easy regularization methods to mitigate the issues caused by \textbf{3D}-properties, improving the training stability and final performance of DPO. Our contributions also include an investigation into how the distribution of the paired preference data impacts the effectiveness of DPO. We hope this work could offer research directions to narrow the gap between reward-free preference learning methods and reward-based ones.
Exploring the LLM Journey from Cognition to Expression with Linear Representations
May 27, 2024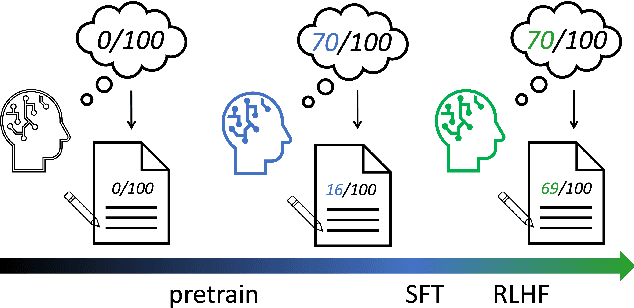

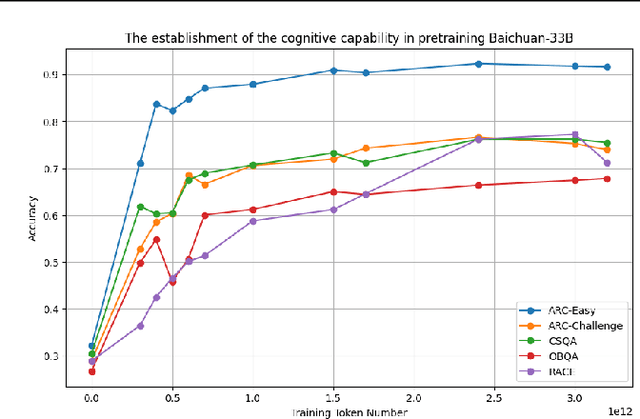

This paper presents an in-depth examination of the evolution and interplay of cognitive and expressive capabilities in large language models (LLMs), with a specific focus on Baichuan-7B and Baichuan-33B, an advanced bilingual (Chinese and English) LLM series. We define and explore the model's cognitive and expressive capabilities through linear representations across three critical phases: Pretraining, Supervised Fine-Tuning (SFT), and Reinforcement Learning from Human Feedback (RLHF). Cognitive capability is defined as the quantity and quality of information conveyed by the neuron output vectors within the network, similar to the neural signal processing in human cognition. Expressive capability is defined as the model's capability to produce word-level output. Our findings unveil a sequential development pattern, where cognitive abilities are largely established during Pretraining, whereas expressive abilities predominantly advance during SFT and RLHF. Statistical analyses confirm a significant correlation between the two capabilities, suggesting that cognitive capacity may limit expressive potential. The paper also explores the theoretical underpinnings of these divergent developmental trajectories and their connection to the LLMs' architectural design. Moreover, we evaluate various optimization-independent strategies, such as few-shot learning and repeated sampling, which bridge the gap between cognitive and expressive capabilities. This research reveals the potential connection between the hidden space and the output space, contributing valuable insights into the interpretability and controllability of their training processes.
Distributed Policy Gradient for Linear Quadratic Networked Control with Limited Communication Range
Mar 05, 2024



This paper proposes a scalable distributed policy gradient method and proves its convergence to near-optimal solution in multi-agent linear quadratic networked systems. The agents engage within a specified network under local communication constraints, implying that each agent can only exchange information with a limited number of neighboring agents. On the underlying graph of the network, each agent implements its control input depending on its nearby neighbors' states in the linear quadratic control setting. We show that it is possible to approximate the exact gradient only using local information. Compared with the centralized optimal controller, the performance gap decreases to zero exponentially as the communication and control ranges increase. We also demonstrate how increasing the communication range enhances system stability in the gradient descent process, thereby elucidating a critical trade-off. The simulation results verify our theoretical findings.
Mixed-Phoneme BERT: Improving BERT with Mixed Phoneme and Sup-Phoneme Representations for Text to Speech
Mar 31, 2022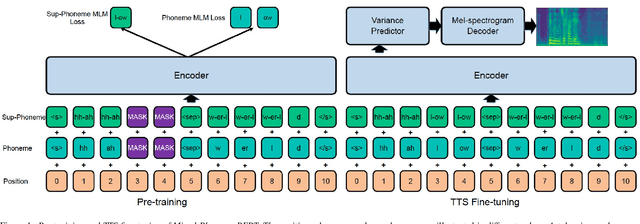
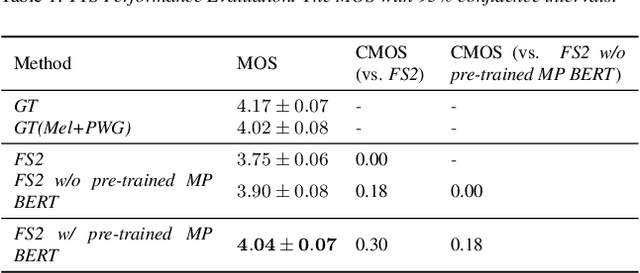

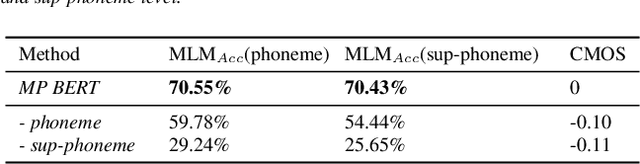
Recently, leveraging BERT pre-training to improve the phoneme encoder in text to speech (TTS) has drawn increasing attention. However, the works apply pre-training with character-based units to enhance the TTS phoneme encoder, which is inconsistent with the TTS fine-tuning that takes phonemes as input. Pre-training only with phonemes as input can alleviate the input mismatch but lack the ability to model rich representations and semantic information due to limited phoneme vocabulary. In this paper, we propose MixedPhoneme BERT, a novel variant of the BERT model that uses mixed phoneme and sup-phoneme representations to enhance the learning capability. Specifically, we merge the adjacent phonemes into sup-phonemes and combine the phoneme sequence and the merged sup-phoneme sequence as the model input, which can enhance the model capacity to learn rich contextual representations. Experiment results demonstrate that our proposed Mixed-Phoneme BERT significantly improves the TTS performance with 0.30 CMOS gain compared with the FastSpeech 2 baseline. The Mixed-Phoneme BERT achieves 3x inference speedup and similar voice quality to the previous TTS pre-trained model PnG BERT