 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate synthesis of Dysarthric Speech for ASR data augmentation
Aug 16, 2023Dysarthria is a motor speech disorder often characterized by reduced speech intelligibility through slow, uncoordinated control of speech production muscles. Automatic Speech recognition (ASR) systems can help dysarthric talkers communicate more effectively. However, robust dysarthria-specific ASR requires a significant amount of training speech, which is not readily available for dysarthric talkers. This paper presents a new dysarthric speech synthesis method for the purpose of ASR training data augmentation. Differences in prosodic and acoustic characteristics of dysarthric spontaneous speech at varying severity levels are important components for dysarthric speech modeling, synthesis, and augmentation. For dysarthric speech synthesis, a modified neural multi-talker TTS is implemented by adding a dysarthria severity level coefficient and a pause insertion model to synthesize dysarthric speech for varying severity levels. To evaluate the effectiveness for synthesis of training data for ASR, dysarthria-specific speech recognition was used. Results show that a DNN-HMM model trained on additional synthetic dysarthric speech achieves WER improvement of 12.2% compared to the baseline, and that the addition of the severity level and pause insertion controls decrease WER by 6.5%, showing the effectiveness of adding these parameters. Overall results on the TORGO database demonstrate that using dysarthric synthetic speech to increase the amount of dysarthric-patterned speech for training has significant impact on the dysarthric ASR systems. In addition, we have conducted a subjective evaluation to evaluate the dysarthric-ness and similarity of synthesized speech. Our subjective evaluation shows that the perceived dysartrhic-ness of synthesized speech is similar to that of true dysarthric speech, especially for higher levels of dysarthria
Synthesizing Dysarthric Speech Using Multi-talker TTS for Dysarthric Speech Recognition
Jan 27, 2022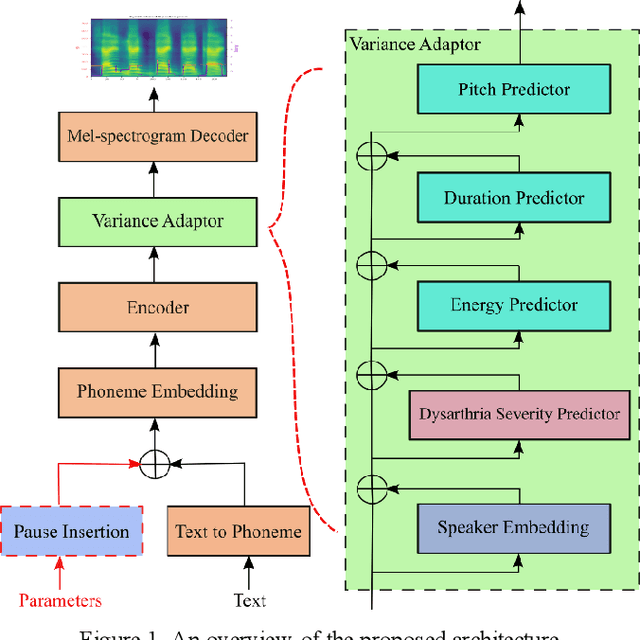
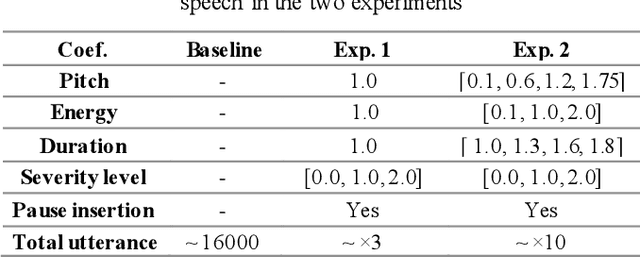
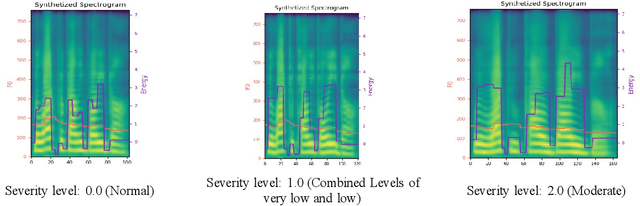
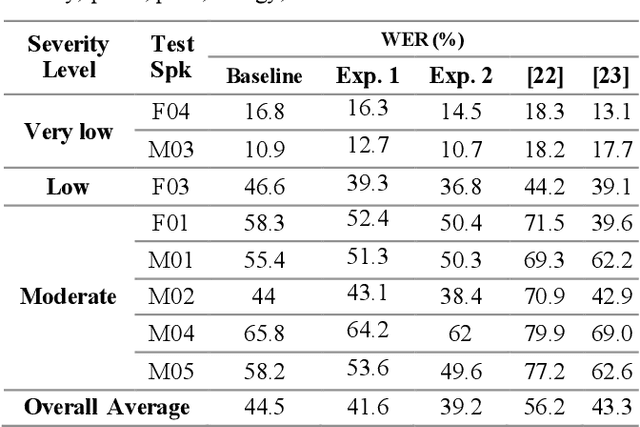
Dysarthria is a motor speech disorder often characterized by reduced speech intelligibility through slow, uncoordinated control of speech production muscles. Automatic Speech recognition (ASR) systems may help dysarthric talkers communicate more effectively. To have robust dysarthria-specific ASR, sufficient training speech is required, which is not readily available. Recent advances in Text-To-Speech (TTS) synthesis multi-speaker end-to-end TTS systems suggest the possibility of using synthesis for data augmentation. In this paper, we aim to improve multi-speaker end-to-end TTS systems to synthesize dysarthric speech for improved training of a dysarthria-specific DNN-HMM ASR. In the synthesized speech, we add dysarthria severity level and pause insertion mechanisms to other control parameters such as pitch, energy, and duration. Results show that a DNN-HMM model trained on additional synthetic dysarthric speech achieves WER improvement of 12.2% compared to the baseline, the addition of the severity level and pause insertion controls decrease WER by 6.5%, showing the effectiveness of adding these parameters. Audio samples are available at
Full Attention Bidirectional Deep Learning Structure for Single Channel Speech Enhancement
Aug 27, 2021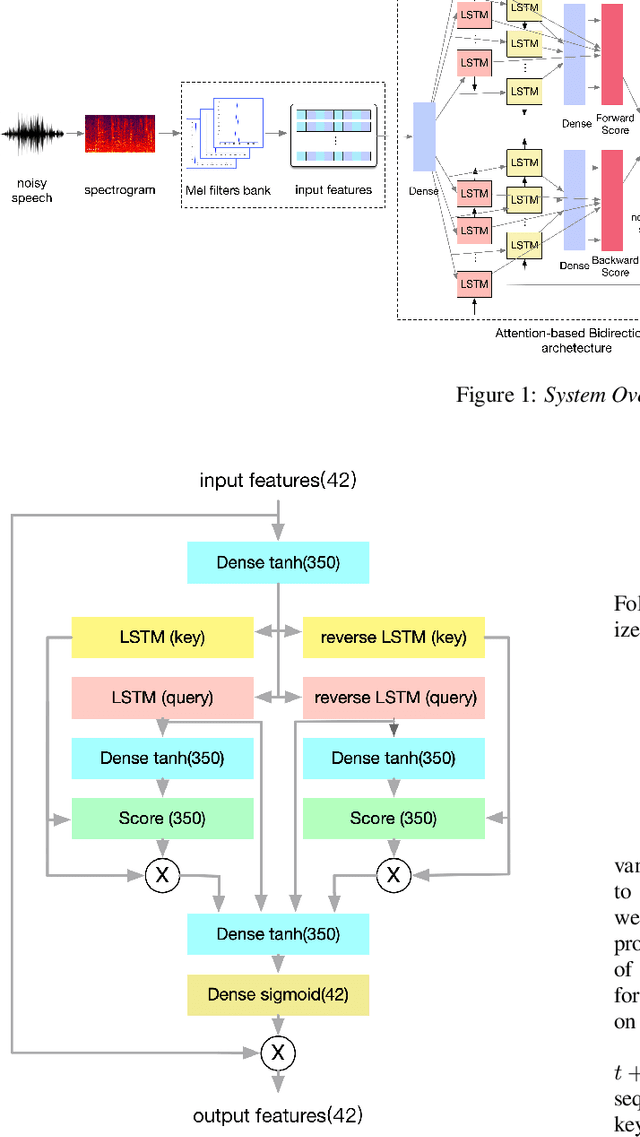

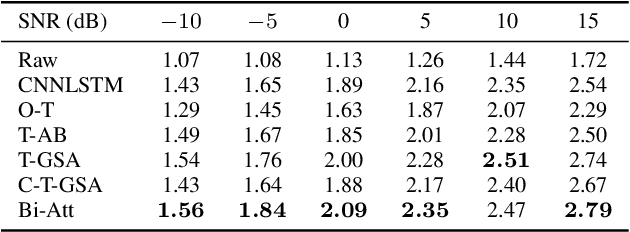

As the cornerstone of other important technologies, such as speech recognition and speech synthesis, speech enhancement is a critical area in audio signal processing. In this paper, a new deep learning structure for speech enhancement is demonstrated. The model introduces a "full" attention mechanism to a bidirectional sequence-to-sequence method to make use of latent information after each focal frame. This is an extension of the previous attention-based RNN method. The proposed bidirectional attention-based architecture achieves better performance in terms of speech quality (PESQ), compared with OM-LSA, CNN-LSTM, T-GSA and the unidirectional attention-based LSTM baseline.
Articulatory-WaveNet: Autoregressive Model For Acoustic-to-Articulatory Inversion
Jun 22, 2020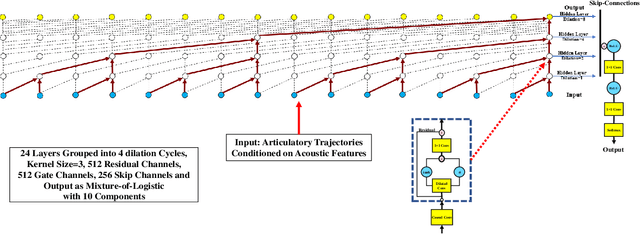
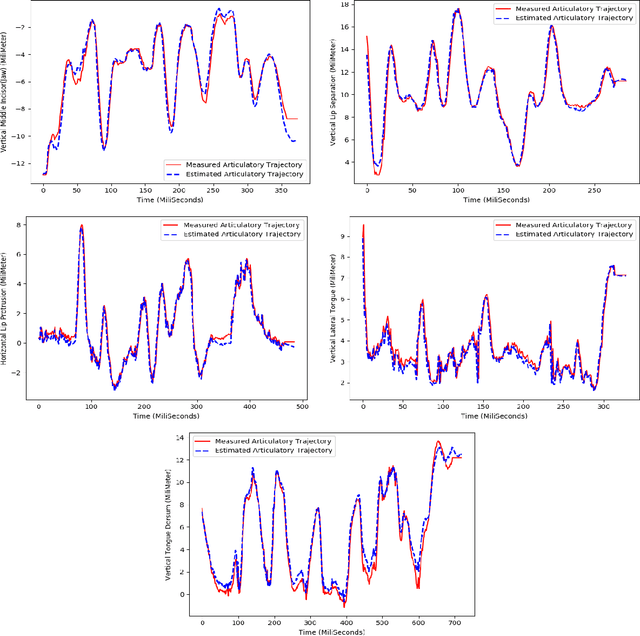
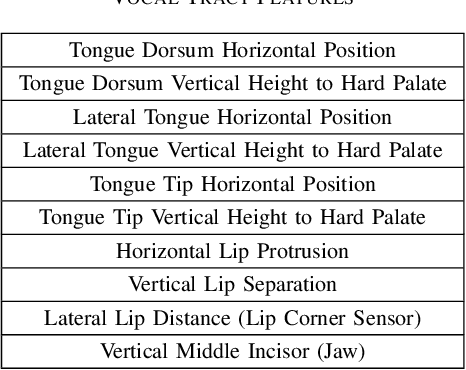
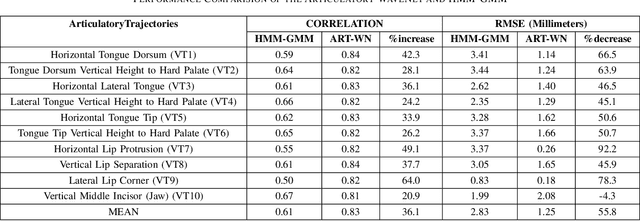
This paper presents Articulatory-WaveNet, a new approach for acoustic-to-articulator inversion. The proposed system uses the WaveNet speech synthesis architecture, with dilated causal convolutional layers using previous values of the predicted articulatory trajectories conditioned on acoustic features. The system was trained and evaluated on the ElectroMagnetic Articulography corpus of Mandarin Accented English (EMA-MAE),consisting of 39 speakers including both native English speakers and native Mandarin speakers speaking English. Results show significant improvement in both correlation and RMSE between the generated and true articulatory trajectories for the new method, with an average correlation of 0.83, representing a 36% relative improvement over the 0.61 correlation obtained with a baseline Hidden Markov Model (HMM)-Gaussian Mixture Model (GMM) inversion framework. To the best of our knowledge, this paper presents the first application of a point-by-point waveform synthesis approach to the problem of acoustic-to-articulatory inversion and the results show improved performance compared to previous methods for speaker dependent acoustic to articulatory inversion.
Comparison of Multiple Features and Modeling Methods for Text-dependent Speaker Verification
Sep 09, 2017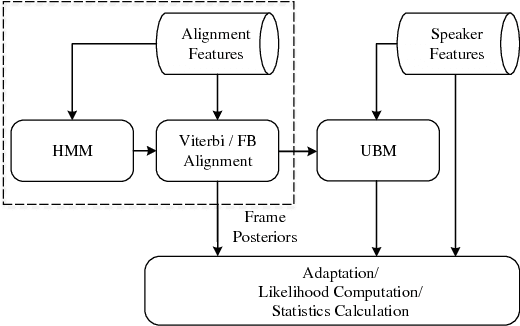
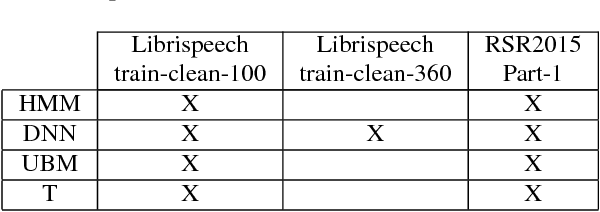
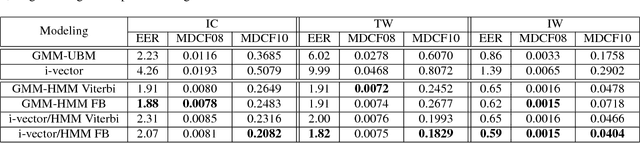
Text-dependent speaker verification is becoming popular in the speaker recognition society. However, the conventional i-vector framework which has been successful for speaker identification and other similar tasks works relatively poorly in this task. Researchers have proposed several new methods to improve performance, but it is still unclear that which model is the best choice, especially when the pass-phrases are prompted during enrollment and test. In this paper, we introduce four modeling methods and compare their performance on the newly published RedDots dataset. To further explore the influence of different frame alignments, Viterbi and forward-backward algorithms are both used in the HMM-based models. Several bottleneck features are also investigated. Our experiments show that, by explicitly modeling the lexical content, the HMM-based modeling achieves good results in the fixed-phrase condition. In the prompted-phrase condition, GMM-HMM and i-vector/HMM are not as successful. In both conditions, the forward-backward algorithm brings more benefits to the i-vector/HMM system. Additionally, we also find that even though bottleneck features perform well for text-independent speaker verification, they do not outperform MFCCs on the most challenging Imposter-Correct trials on RedDots.