 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArticulatory-WaveNet: Autoregressive Model For Acoustic-to-Articulatory Inversion
Paper and Code
Jun 22, 2020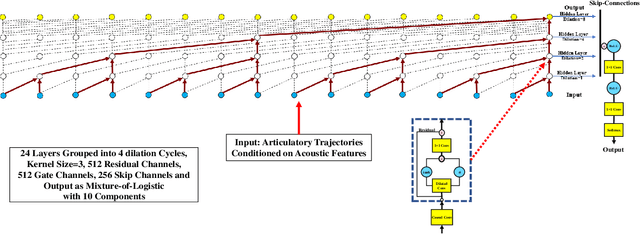
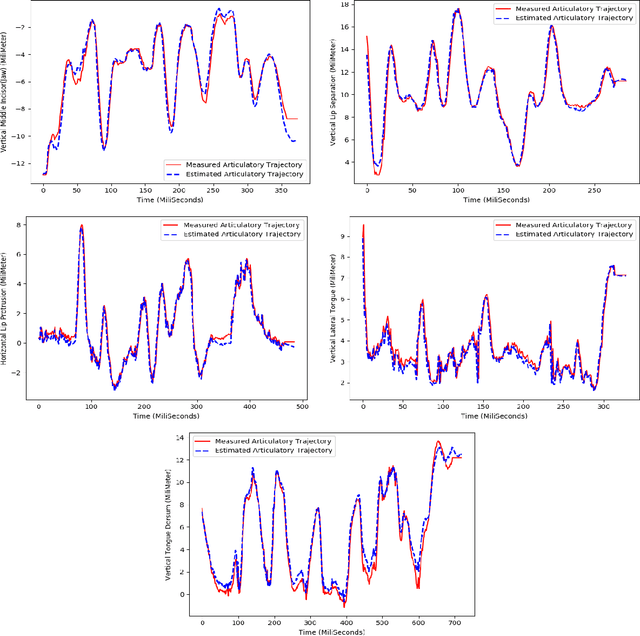
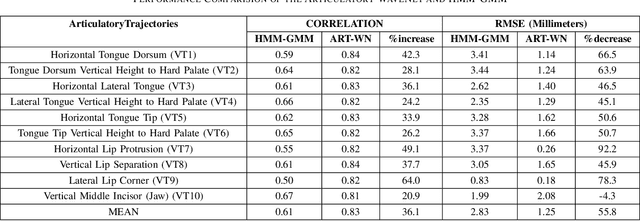
This paper presents Articulatory-WaveNet, a new approach for acoustic-to-articulator inversion. The proposed system uses the WaveNet speech synthesis architecture, with dilated causal convolutional layers using previous values of the predicted articulatory trajectories conditioned on acoustic features. The system was trained and evaluated on the ElectroMagnetic Articulography corpus of Mandarin Accented English (EMA-MAE),consisting of 39 speakers including both native English speakers and native Mandarin speakers speaking English. Results show significant improvement in both correlation and RMSE between the generated and true articulatory trajectories for the new method, with an average correlation of 0.83, representing a 36% relative improvement over the 0.61 correlation obtained with a baseline Hidden Markov Model (HMM)-Gaussian Mixture Model (GMM) inversion framework. To the best of our knowledge, this paper presents the first application of a point-by-point waveform synthesis approach to the problem of acoustic-to-articulatory inversion and the results show improved performance compared to previous methods for speaker dependent acoustic to articulatory inversion.