Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFull Attention Bidirectional Deep Learning Structure for Single Channel Speech Enhancement
Paper and Code
Aug 27, 2021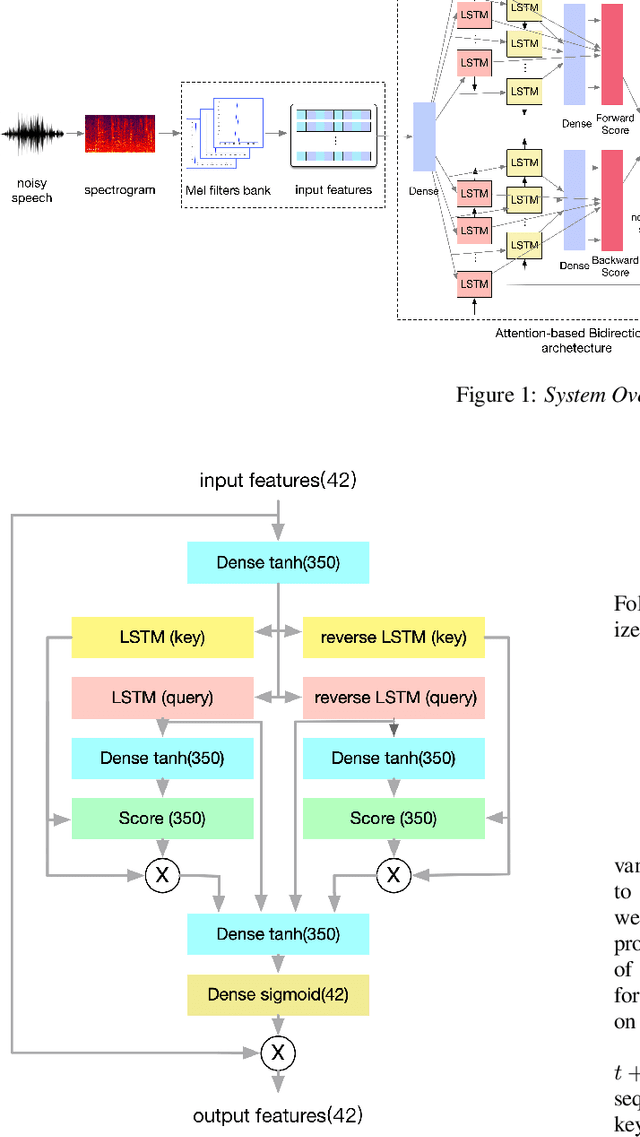

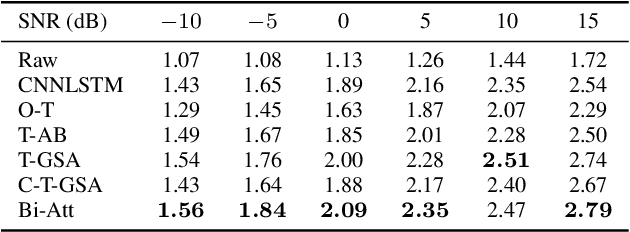

As the cornerstone of other important technologies, such as speech recognition and speech synthesis, speech enhancement is a critical area in audio signal processing. In this paper, a new deep learning structure for speech enhancement is demonstrated. The model introduces a "full" attention mechanism to a bidirectional sequence-to-sequence method to make use of latent information after each focal frame. This is an extension of the previous attention-based RNN method. The proposed bidirectional attention-based architecture achieves better performance in terms of speech quality (PESQ), compared with OM-LSA, CNN-LSTM, T-GSA and the unidirectional attention-based LSTM baseline.
* 4 pages
View paper on