 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEngagement Process: Rethinking the Temporal Interface of Action and Observation
May 12, 2026Task completion in digital and physical environments increasingly involves complex temporal interaction, where actions and observations unfold over different time scales rather than align with fixed observation--action steps. To model such interactions, we propose \emph{Engagement Process} (EP), an interaction formalism that inherits the decision-theoretic structure of POMDPs while making time explicit in the action--observation interface. EP represents actions and observations as decoupled event streams along time, rather than updates paired at fixed decision steps. This interface captures single-agent timing issues such as deliberation latency, delayed feedback, and persistent actions, while supporting richer agent-side organization, multi-rate coordination, and compositional interaction among subsystems. Across toy, LLM-agent, and learning experiments, EP exposes temporal behaviors hidden by step-based interfaces and enables policies to adapt under explicit time costs.
Reasoning as State Transition: A Representational Analysis of Reasoning Evolution in Large Language Models
Jan 31, 2026Large Language Models have achieved remarkable performance on reasoning tasks, motivating research into how this ability evolves during training. Prior work has primarily analyzed this evolution via explicit generation outcomes, treating the reasoning process as a black box and obscuring internal changes. To address this opacity, we introduce a representational perspective to investigate the dynamics of the model's internal states. Through comprehensive experiments across models at various training stages, we discover that post-training yields only limited improvement in static initial representation quality. Furthermore, we reveal that, distinct from non-reasoning tasks, reasoning involves a significant continuous distributional shift in representations during generation. Comparative analysis indicates that post-training empowers models to drive this transition toward a better distribution for task solving. To clarify the relationship between internal states and external outputs, statistical analysis confirms a high correlation between generation correctness and the final representations; while counterfactual experiments identify the semantics of the generated tokens, rather than additional computation during inference or intrinsic parameter differences, as the dominant driver of the transition. Collectively, we offer a novel understanding of the reasoning process and the effect of training on reasoning enhancement, providing valuable insights for future model analysis and optimization.
Boosting Deductive Reasoning with Step Signals In RLHF
Oct 12, 2024
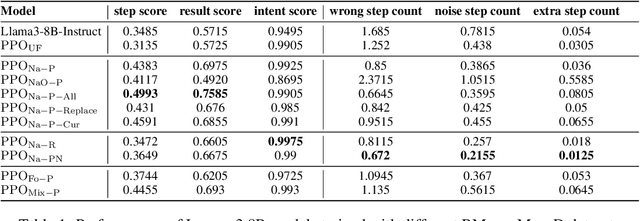


Logical reasoning is a crucial task for Large Language Models (LLMs), enabling them to tackle complex problems. Among reasoning tasks, multi-step reasoning poses a particular challenge. Grounded in the theory of formal logic, we have developed an automated method, Multi-step Deduction (MuseD), for deductive reasoning data. MuseD has allowed us to create training and testing datasets for multi-step reasoning. Our generation method enables control over the complexity of the generated instructions, facilitating training and evaluation of models across different difficulty levels. Through RLHF training, our training data has demonstrated significant improvements in logical capabilities for both in-domain of out-of-domain reasoning tasks. Additionally, we have conducted tests to assess the multi-step reasoning abilities of various models.
3D-Properties: Identifying Challenges in DPO and Charting a Path Forward
Jun 11, 2024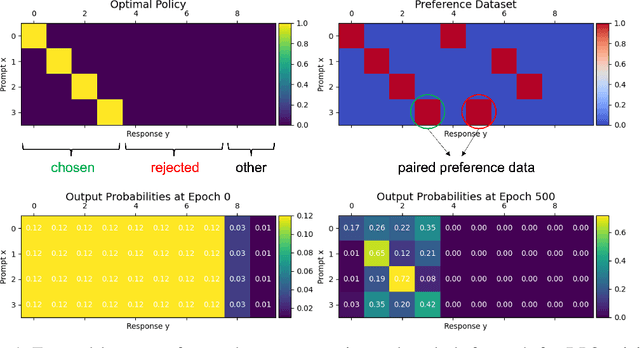
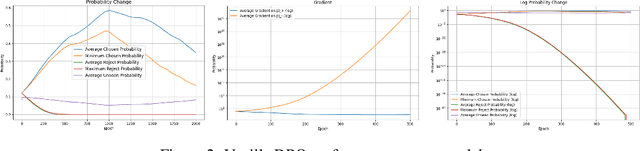
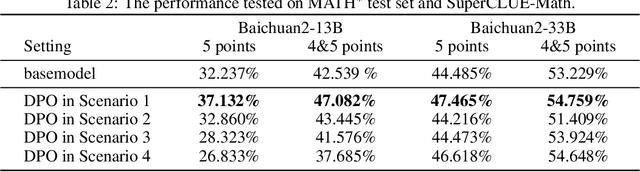
Aligning large language models (LLMs) with human preference has recently gained tremendous attention, with the canonical yet costly RLHF-PPO and the simple and straightforward Direct Preference Optimization (DPO) as two examples. Despite the efficiency, DPO has rarely be used in the state-of-the-art production-level LLMs, implying its potential pathologies. In this work, we revisit DPO with a comprehensive examination of its empirical efficacy and a systematic comparison with RLHF-PPO. We identify the \textbf{3D}-properties of DPO's learning outcomes: the \textbf{D}rastic drop in the likelihood of rejected responses, the \textbf{D}egradation into LLM unlearning, and the \textbf{D}ispersion effect on unseen responses through experiments with both a carefully designed toy model and practical LLMs on tasks including mathematical problem-solving and instruction following. These findings inherently connect to some observations made by related works and we additionally contribute a plausible theoretical explanation for them. Accordingly, we propose easy regularization methods to mitigate the issues caused by \textbf{3D}-properties, improving the training stability and final performance of DPO. Our contributions also include an investigation into how the distribution of the paired preference data impacts the effectiveness of DPO. We hope this work could offer research directions to narrow the gap between reward-free preference learning methods and reward-based ones.
Exploring the LLM Journey from Cognition to Expression with Linear Representations
May 27, 2024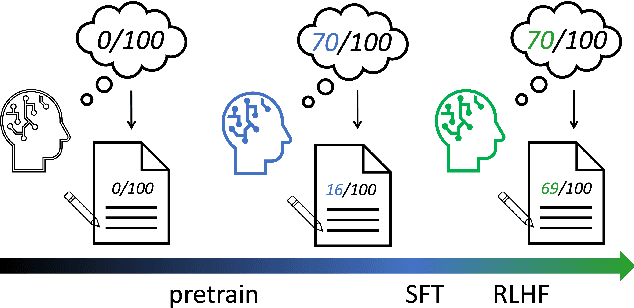

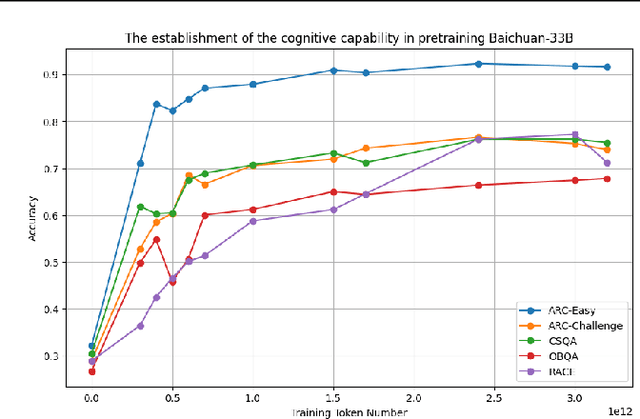

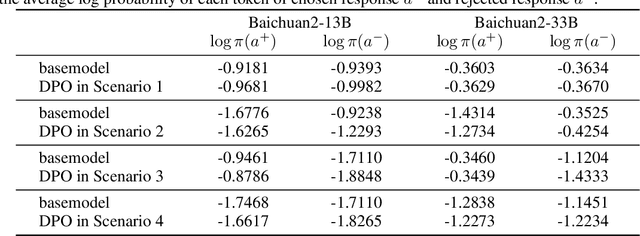
This paper presents an in-depth examination of the evolution and interplay of cognitive and expressive capabilities in large language models (LLMs), with a specific focus on Baichuan-7B and Baichuan-33B, an advanced bilingual (Chinese and English) LLM series. We define and explore the model's cognitive and expressive capabilities through linear representations across three critical phases: Pretraining, Supervised Fine-Tuning (SFT), and Reinforcement Learning from Human Feedback (RLHF). Cognitive capability is defined as the quantity and quality of information conveyed by the neuron output vectors within the network, similar to the neural signal processing in human cognition. Expressive capability is defined as the model's capability to produce word-level output. Our findings unveil a sequential development pattern, where cognitive abilities are largely established during Pretraining, whereas expressive abilities predominantly advance during SFT and RLHF. Statistical analyses confirm a significant correlation between the two capabilities, suggesting that cognitive capacity may limit expressive potential. The paper also explores the theoretical underpinnings of these divergent developmental trajectories and their connection to the LLMs' architectural design. Moreover, we evaluate various optimization-independent strategies, such as few-shot learning and repeated sampling, which bridge the gap between cognitive and expressive capabilities. This research reveals the potential connection between the hidden space and the output space, contributing valuable insights into the interpretability and controllability of their training processes.
Reward Informed Dreamer for Task Generalization in Reinforcement Learning
Mar 09, 2023
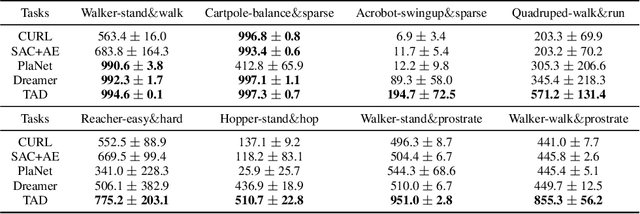
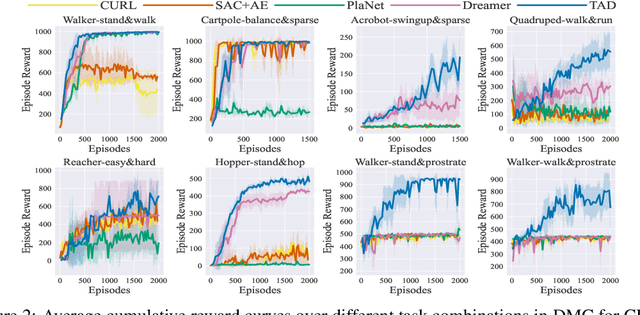
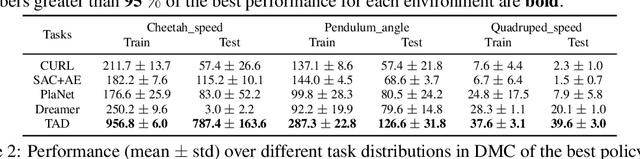
A long-standing goal of reinforcement learning is that algorithms can learn on training tasks and generalize well on unseen tasks like humans, where different tasks share similar dynamic with different reward functions. A general challenge is that it is nontrivial to quantitatively measure the similarities between these different tasks, which is vital for analyzing the task distribution and further designing algorithms with stronger generalization. To address this, we present a novel metric named Task Distribution Relevance (TDR) via optimal Q functions to capture the relevance of the task distribution quantitatively. In the case of tasks with a high TDR, i.e., the tasks differ significantly, we demonstrate that the Markovian policies cannot distinguish them, yielding poor performance accordingly. Based on this observation, we propose a framework of Reward Informed Dreamer (RID) with reward-informed world models, which captures invariant latent features over tasks and encodes reward signals into policies for distinguishing different tasks. In RID, we calculate the corresponding variational lower bound of the log-likelihood on the data, which includes a novel term to distinguish different tasks via states, based on reward-informed world models. Finally, extensive experiments in DeepMind control suite demonstrate that RID can significantly improve the performance of handling different tasks at the same time, especially for those with high TDR, and further generalize to unseen tasks effectively.
LiDARCap: Long-range Marker-less 3D Human Motion Capture with LiDAR Point Clouds
Mar 28, 2022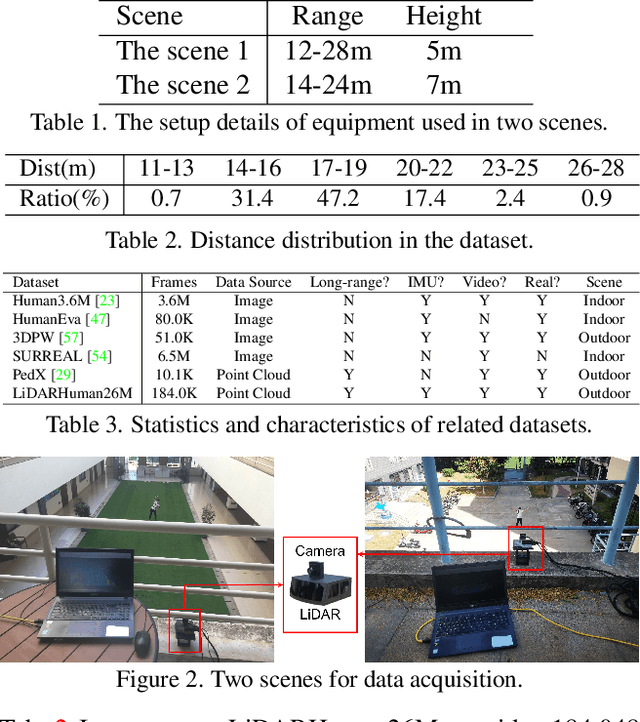
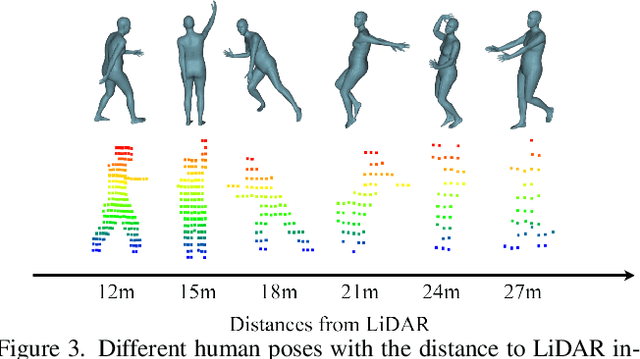
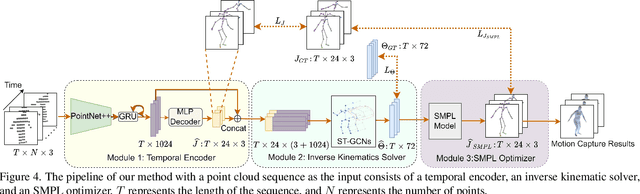
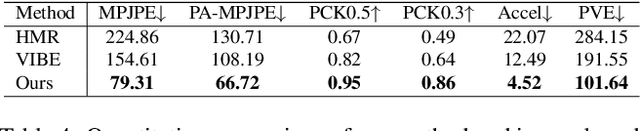
Existing motion capture datasets are largely short-range and cannot yet fit the need of long-range applications. We propose LiDARHuman26M, a new human motion capture dataset captured by LiDAR at a much longer range to overcome this limitation. Our dataset also includes the ground truth human motions acquired by the IMU system and the synchronous RGB images. We further present a strong baseline method, LiDARCap, for LiDAR point cloud human motion capture. Specifically, we first utilize PointNet++ to encode features of points and then employ the inverse kinematics solver and SMPL optimizer to regress the pose through aggregating the temporally encoded features hierarchically. Quantitative and qualitative experiments show that our method outperforms the techniques based only on RGB images. Ablation experiments demonstrate that our dataset is challenging and worthy of further research. Finally, the experiments on the KITTI Dataset and the Waymo Open Dataset show that our method can be generalized to different LiDAR sensor settings.
Policy Learning for Robust Markov Decision Process with a Mismatched Generative Model
Mar 15, 2022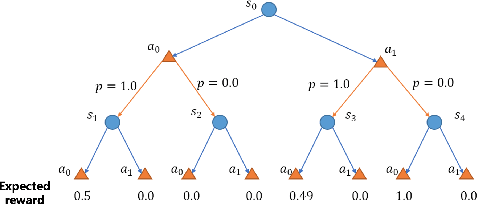
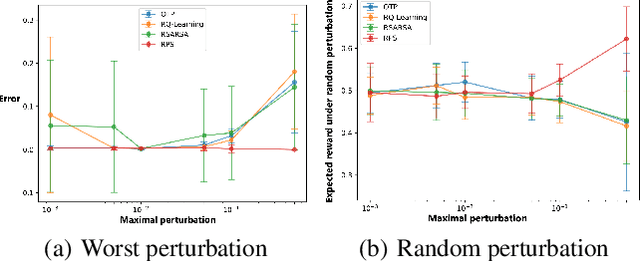
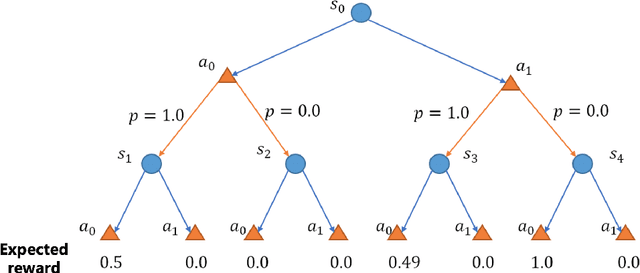
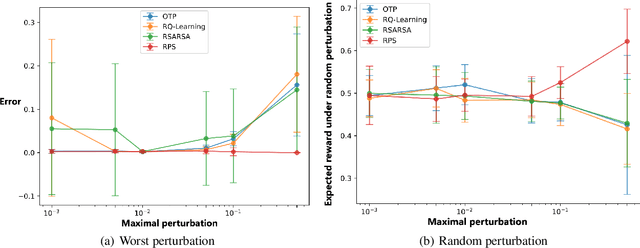
In high-stake scenarios like medical treatment and auto-piloting, it's risky or even infeasible to collect online experimental data to train the agent. Simulation-based training can alleviate this issue, but may suffer from its inherent mismatches from the simulator and real environment. It is therefore imperative to utilize the simulator to learn a robust policy for the real-world deployment. In this work, we consider policy learning for Robust Markov Decision Processes (RMDP), where the agent tries to seek a robust policy with respect to unexpected perturbations on the environments. Specifically, we focus on the setting where the training environment can be characterized as a generative model and a constrained perturbation can be added to the model during testing. Our goal is to identify a near-optimal robust policy for the perturbed testing environment, which introduces additional technical difficulties as we need to simultaneously estimate the training environment uncertainty from samples and find the worst-case perturbation for testing. To solve this issue, we propose a generic method which formalizes the perturbation as an opponent to obtain a two-player zero-sum game, and further show that the Nash Equilibrium corresponds to the robust policy. We prove that, with a polynomial number of samples from the generative model, our algorithm can find a near-optimal robust policy with a high probability. Our method is able to deal with general perturbations under some mild assumptions and can also be extended to more complex problems like robust partial observable Markov decision process, thanks to the game-theoretical formulation.
Nearly Horizon-Free Offline Reinforcement Learning
Mar 25, 2021
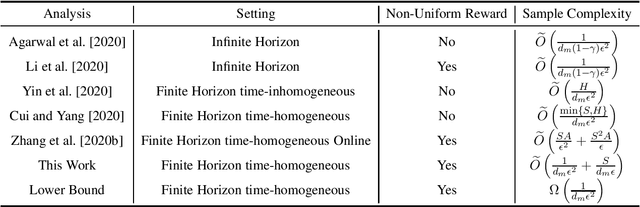
We revisit offline reinforcement learning on episodic time-homogeneous tabular Markov Decision Processes with $S$ states, $A$ actions and planning horizon $H$. Given the collected $N$ episodes data with minimum cumulative reaching probability $d_m$, we obtain the first set of nearly $H$-free sample complexity bounds for evaluation and planning using the empirical MDPs: 1.For the offline evaluation, we obtain an $\tilde{O}\left(\sqrt{\frac{1}{Nd_m}} \right)$ error rate, which matches the lower bound and does not have additional dependency on $\poly\left(S,A\right)$ in higher-order term, that is different from previous works~\citep{yin2020near,yin2020asymptotically}. 2.For the offline policy optimization, we obtain an $\tilde{O}\left(\sqrt{\frac{1}{Nd_m}} + \frac{S}{Nd_m}\right)$ error rate, improving upon the best known result by \cite{cui2020plug}, which has additional $H$ and $S$ factors in the main term. Furthermore, this bound approaches the $\Omega\left(\sqrt{\frac{1}{Nd_m}}\right)$ lower bound up to logarithmic factors and a high-order term. To the best of our knowledge, these are the first set of nearly horizon-free bounds in offline reinforcement learning.
Fast Regularity-Constrained Plane Reconstruction
May 20, 2019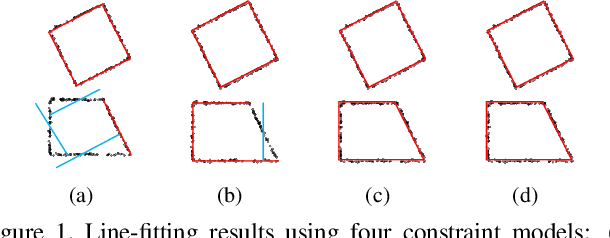
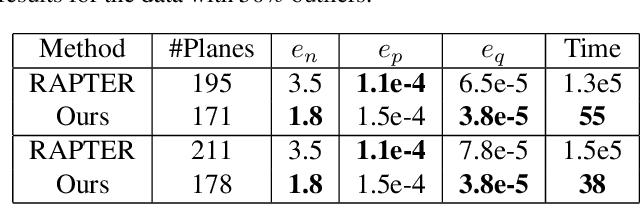
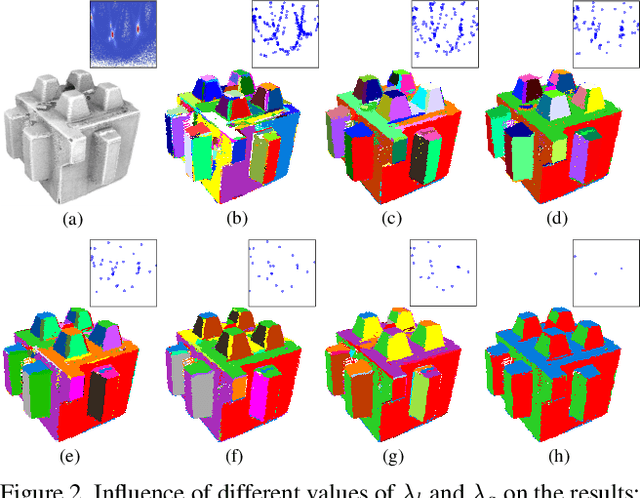
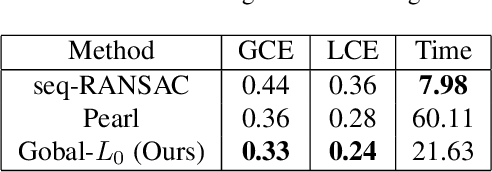
Man-made environments typically comprise planar structures that exhibit numerous geometric relationships, such as parallelism, coplanarity, and orthogonality. Making full use of these relationships can considerably improve the robustness of algorithmic plane reconstruction of complex scenes. This research leverages a constraint model requiring minimal prior knowledge to implicitly establish relationships among planes. We introduce a method based on energy minimization to reconstruct the planes consistent with our constraint model. The proposed algorithm is efficient, easily to understand, and simple to implement. The experimental results show that our algorithm successfully reconstructs planes under high percentages of noise and outliers. This is superior to other state-of-the-art regularity-constrained plane reconstruction methods in terms of speed and robustness.