 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Informed Dreamer for Task Generalization in Reinforcement Learning
Paper and Code
Mar 09, 2023
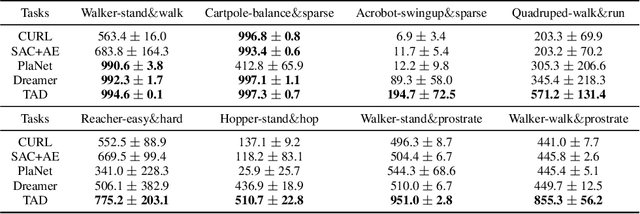
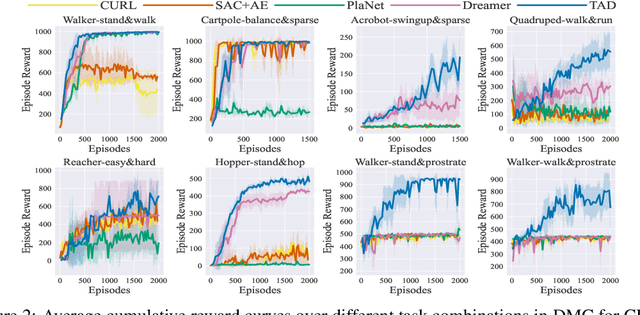
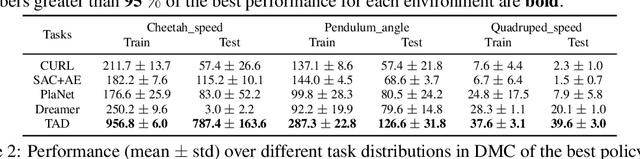
A long-standing goal of reinforcement learning is that algorithms can learn on training tasks and generalize well on unseen tasks like humans, where different tasks share similar dynamic with different reward functions. A general challenge is that it is nontrivial to quantitatively measure the similarities between these different tasks, which is vital for analyzing the task distribution and further designing algorithms with stronger generalization. To address this, we present a novel metric named Task Distribution Relevance (TDR) via optimal Q functions to capture the relevance of the task distribution quantitatively. In the case of tasks with a high TDR, i.e., the tasks differ significantly, we demonstrate that the Markovian policies cannot distinguish them, yielding poor performance accordingly. Based on this observation, we propose a framework of Reward Informed Dreamer (RID) with reward-informed world models, which captures invariant latent features over tasks and encodes reward signals into policies for distinguishing different tasks. In RID, we calculate the corresponding variational lower bound of the log-likelihood on the data, which includes a novel term to distinguish different tasks via states, based on reward-informed world models. Finally, extensive experiments in DeepMind control suite demonstrate that RID can significantly improve the performance of handling different tasks at the same time, especially for those with high TDR, and further generalize to unseen tasks effectively.