 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploratory Diffusion Policy for Unsupervised Reinforcement Learning
Feb 11, 2025



Unsupervised reinforcement learning (RL) aims to pre-train agents by exploring states or skills in reward-free environments, facilitating the adaptation to downstream tasks. However, existing methods often overlook the fitting ability of pre-trained policies and struggle to handle the heterogeneous pre-training data, which are crucial for achieving efficient exploration and fast fine-tuning. To address this gap, we propose Exploratory Diffusion Policy (EDP), which leverages the strong expressive ability of diffusion models to fit the explored data, both boosting exploration and obtaining an efficient initialization for downstream tasks. Specifically, we estimate the distribution of collected data in the replay buffer with the diffusion policy and propose a score intrinsic reward, encouraging the agent to explore unseen states. For fine-tuning the pre-trained diffusion policy on downstream tasks, we provide both theoretical analyses and practical algorithms, including an alternating method of Q function optimization and diffusion policy distillation. Extensive experiments demonstrate the effectiveness of EDP in efficient exploration during pre-training and fast adaptation during fine-tuning.
PEAC: Unsupervised Pre-training for Cross-Embodiment Reinforcement Learning
May 23, 2024Designing generalizable agents capable of adapting to diverse embodiments has achieved significant attention in Reinforcement Learning (RL), which is critical for deploying RL agents in various real-world applications. Previous Cross-Embodiment RL approaches have focused on transferring knowledge across embodiments within specific tasks. These methods often result in knowledge tightly coupled with those tasks and fail to adequately capture the distinct characteristics of different embodiments. To address this limitation, we introduce the notion of Cross-Embodiment Unsupervised RL (CEURL), which leverages unsupervised learning to enable agents to acquire embodiment-aware and task-agnostic knowledge through online interactions within reward-free environments. We formulate CEURL as a novel Controlled Embodiment Markov Decision Process (CE-MDP) and systematically analyze CEURL's pre-training objectives under CE-MDP. Based on these analyses, we develop a novel algorithm Pre-trained Embodiment-Aware Control (PEAC) for handling CEURL, incorporating an intrinsic reward function specifically designed for cross-embodiment pre-training. PEAC not only provides an intuitive optimization strategy for cross-embodiment pre-training but also can integrate flexibly with existing unsupervised RL methods, facilitating cross-embodiment exploration and skill discovery. Extensive experiments in both simulated (e.g., DMC and Robosuite) and real-world environments (e.g., legged locomotion) demonstrate that PEAC significantly improves adaptation performance and cross-embodiment generalization, demonstrating its effectiveness in overcoming the unique challenges of CEURL.
The RoboDrive Challenge: Drive Anytime Anywhere in Any Condition
May 14, 2024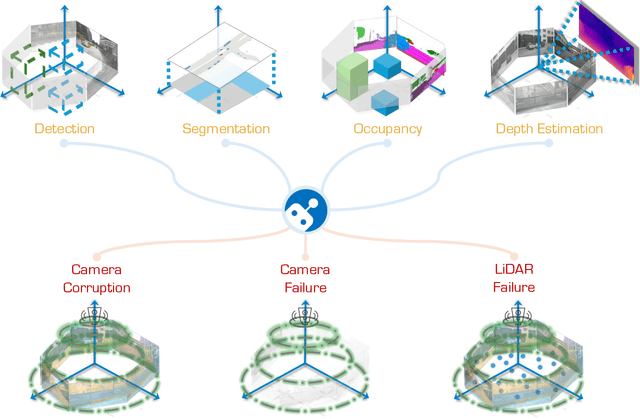


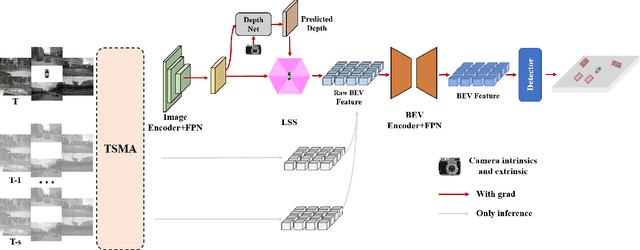
In the realm of autonomous driving, robust perception under out-of-distribution conditions is paramount for the safe deployment of vehicles. Challenges such as adverse weather, sensor malfunctions, and environmental unpredictability can severely impact the performance of autonomous systems. The 2024 RoboDrive Challenge was crafted to propel the development of driving perception technologies that can withstand and adapt to these real-world variabilities. Focusing on four pivotal tasks -- BEV detection, map segmentation, semantic occupancy prediction, and multi-view depth estimation -- the competition laid down a gauntlet to innovate and enhance system resilience against typical and atypical disturbances. This year's challenge consisted of five distinct tracks and attracted 140 registered teams from 93 institutes across 11 countries, resulting in nearly one thousand submissions evaluated through our servers. The competition culminated in 15 top-performing solutions, which introduced a range of innovative approaches including advanced data augmentation, multi-sensor fusion, self-supervised learning for error correction, and new algorithmic strategies to enhance sensor robustness. These contributions significantly advanced the state of the art, particularly in handling sensor inconsistencies and environmental variability. Participants, through collaborative efforts, pushed the boundaries of current technologies, showcasing their potential in real-world scenarios. Extensive evaluations and analyses provided insights into the effectiveness of these solutions, highlighting key trends and successful strategies for improving the resilience of driving perception systems. This challenge has set a new benchmark in the field, providing a rich repository of techniques expected to guide future research in this field.
Reward Informed Dreamer for Task Generalization in Reinforcement Learning
Mar 09, 2023
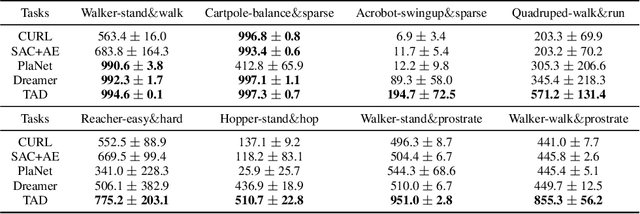
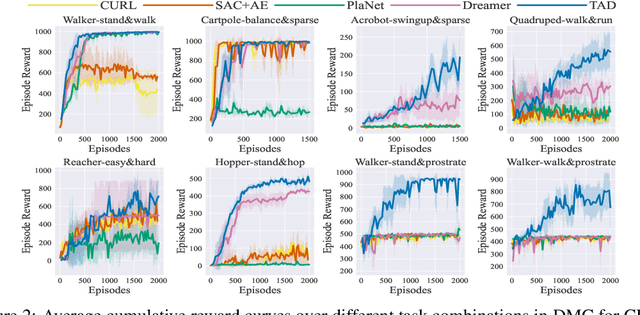
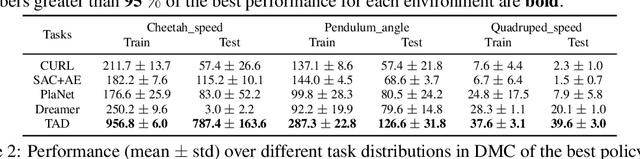
A long-standing goal of reinforcement learning is that algorithms can learn on training tasks and generalize well on unseen tasks like humans, where different tasks share similar dynamic with different reward functions. A general challenge is that it is nontrivial to quantitatively measure the similarities between these different tasks, which is vital for analyzing the task distribution and further designing algorithms with stronger generalization. To address this, we present a novel metric named Task Distribution Relevance (TDR) via optimal Q functions to capture the relevance of the task distribution quantitatively. In the case of tasks with a high TDR, i.e., the tasks differ significantly, we demonstrate that the Markovian policies cannot distinguish them, yielding poor performance accordingly. Based on this observation, we propose a framework of Reward Informed Dreamer (RID) with reward-informed world models, which captures invariant latent features over tasks and encodes reward signals into policies for distinguishing different tasks. In RID, we calculate the corresponding variational lower bound of the log-likelihood on the data, which includes a novel term to distinguish different tasks via states, based on reward-informed world models. Finally, extensive experiments in DeepMind control suite demonstrate that RID can significantly improve the performance of handling different tasks at the same time, especially for those with high TDR, and further generalize to unseen tasks effectively.
On the Reuse Bias in Off-Policy Reinforcement Learning
Sep 15, 2022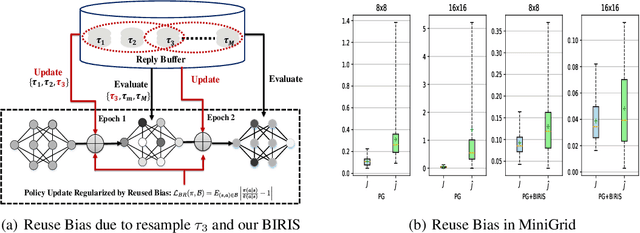
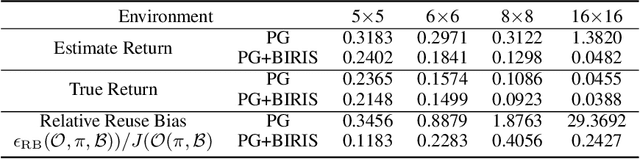

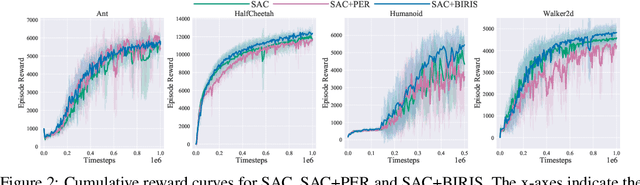
Importance sampling (IS) is a popular technique in off-policy evaluation, which re-weights the return of trajectories in the replay buffer to boost sample efficiency. However, training with IS can be unstable and previous attempts to address this issue mainly focus on analyzing the variance of IS. In this paper, we reveal that the instability is also related to a new notion of Reuse Bias of IS -- the bias in off-policy evaluation caused by the reuse of the replay buffer for evaluation and optimization. We theoretically show that the off-policy evaluation and optimization of the current policy with the data from the replay buffer result in an overestimation of the objective, which may cause an erroneous gradient update and degenerate the performance. We further provide a high-probability upper bound of the Reuse Bias, and show that controlling one term of the upper bound can control the Reuse Bias by introducing the concept of stability for off-policy algorithms. Based on these analyses, we finally present a novel Bias-Regularized Importance Sampling (BIRIS) framework along with practical algorithms, which can alleviate the negative impact of the Reuse Bias. Experimental results show that our BIRIS-based methods can significantly improve the sample efficiency on a series of continuous control tasks in MuJoCo.
Consistent Attack: Universal Adversarial Perturbation on Embodied Vision Navigation
Jun 12, 2022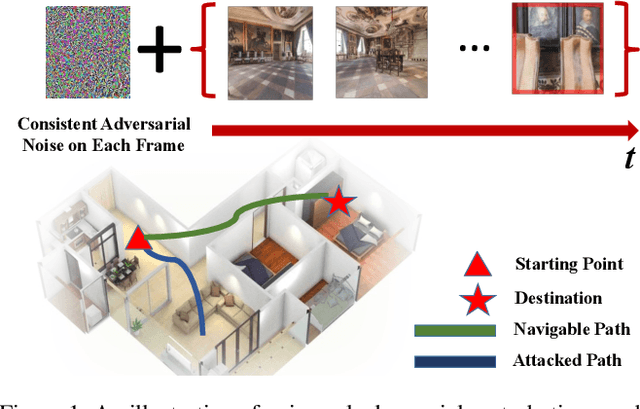
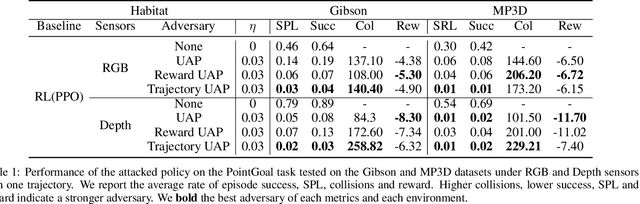

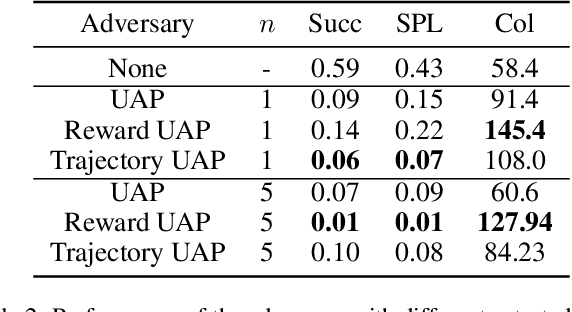
Embodied agents in vision navigation coupled with deep neural networks have attracted increasing attention. However, deep neural networks are vulnerable to malicious adversarial noises, which may potentially cause catastrophic failures in Embodied Vision Navigation. Among these adversarial noises, universal adversarial perturbations (UAP), i.e., the image-agnostic perturbation applied on each frame received by the agent, are more critical for Embodied Vision Navigation since they are computation-efficient and application-practical during the attack. However, existing UAP methods do not consider the system dynamics of Embodied Vision Navigation. For extending UAP in the sequential decision setting, we formulate the disturbed environment under the universal noise $\delta$, as a $\delta$-disturbed Markov Decision Process ($\delta$-MDP). Based on the formulation, we analyze the properties of $\delta$-MDP and propose two novel Consistent Attack methods for attacking Embodied agents, which first consider the dynamic of the MDP by estimating the disturbed Q function and the disturbed distribution. In spite of victim models, our Consistent Attack can cause a significant drop in the performance for the Goalpoint task in habitat. Extensive experimental results indicate that there exist potential risks for applying Embodied Vision Navigation methods to the real world.
Towards Safe Reinforcement Learning via Constraining Conditional Value-at-Risk
Jun 09, 2022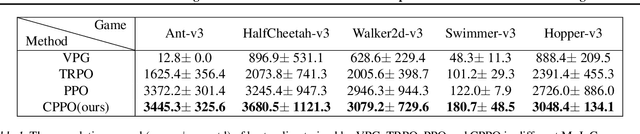
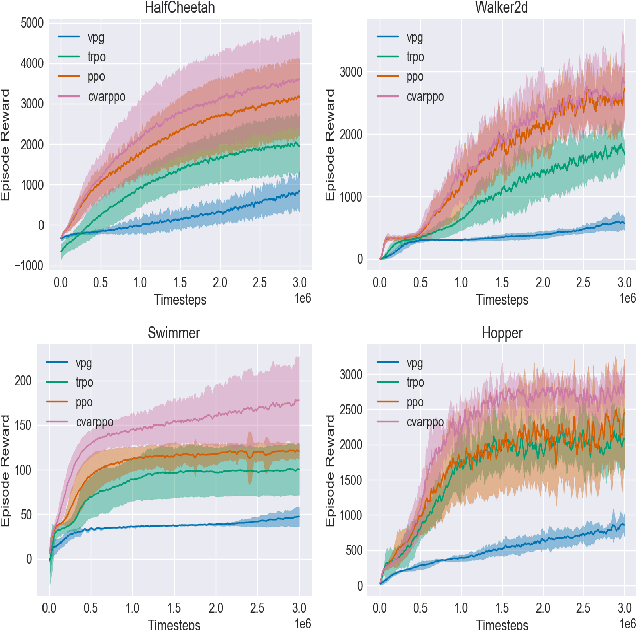
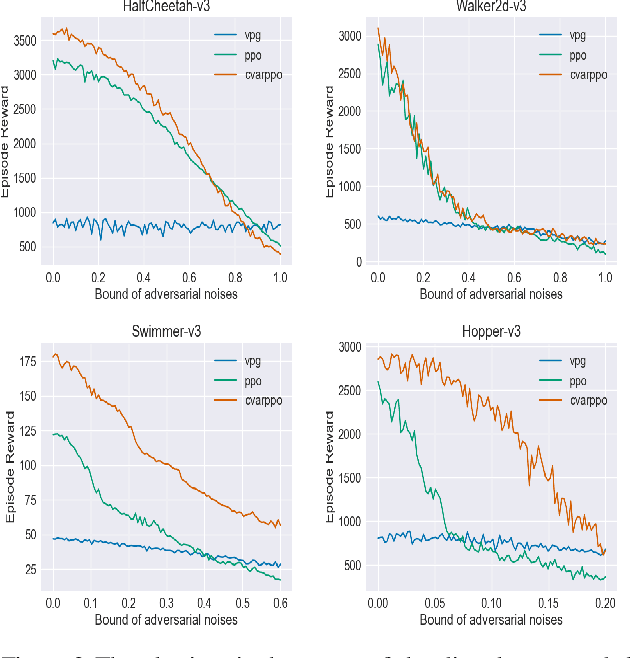
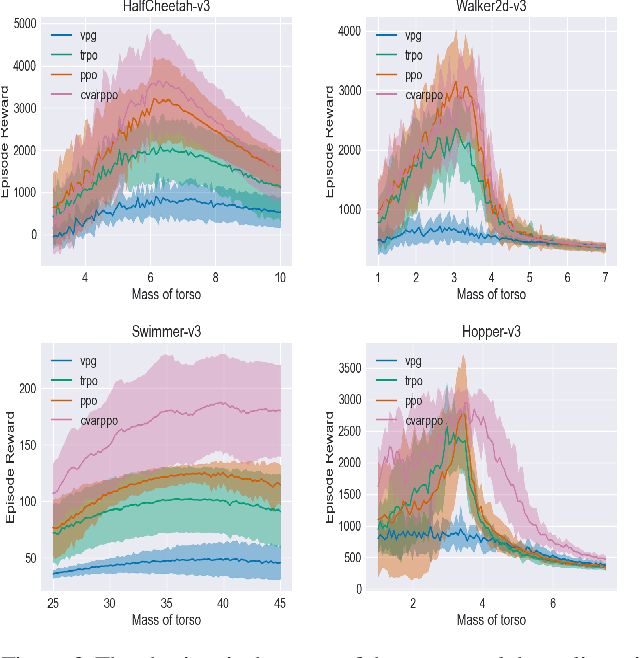
Though deep reinforcement learning (DRL) has obtained substantial success, it may encounter catastrophic failures due to the intrinsic uncertainty of both transition and observation. Most of the existing methods for safe reinforcement learning can only handle transition disturbance or observation disturbance since these two kinds of disturbance affect different parts of the agent; besides, the popular worst-case return may lead to overly pessimistic policies. To address these issues, we first theoretically prove that the performance degradation under transition disturbance and observation disturbance depends on a novel metric of Value Function Range (VFR), which corresponds to the gap in the value function between the best state and the worst state. Based on the analysis, we adopt conditional value-at-risk (CVaR) as an assessment of risk and propose a novel reinforcement learning algorithm of CVaR-Proximal-Policy-Optimization (CPPO) which formalizes the risk-sensitive constrained optimization problem by keeping its CVaR under a given threshold. Experimental results show that CPPO achieves a higher cumulative reward and is more robust against both observation and transition disturbances on a series of continuous control tasks in MuJoCo.
Understanding Adversarial Attacks on Observations in Deep Reinforcement Learning
Jun 30, 2021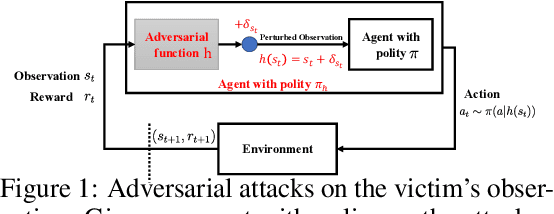
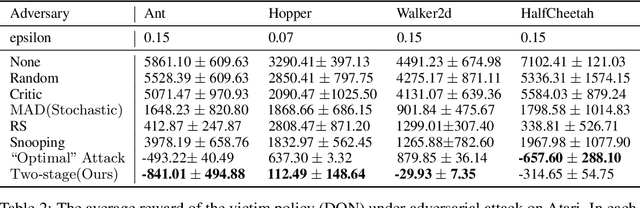
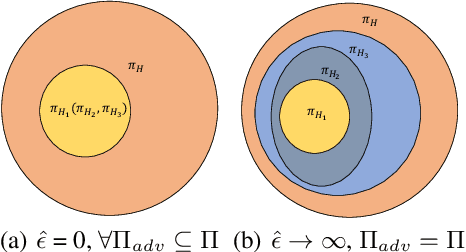
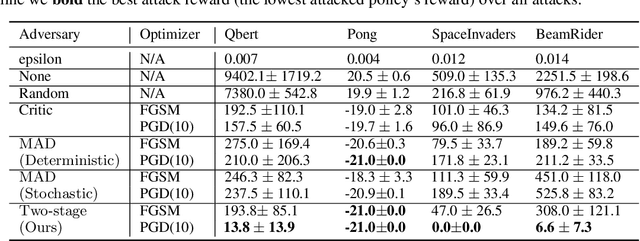
Recent works demonstrate that deep reinforcement learning (DRL) models are vulnerable to adversarial attacks which can decrease the victim's total reward by manipulating the observations. Compared with adversarial attacks in supervised learning, it is much more challenging to deceive a DRL model since the adversary has to infer the environmental dynamics. To address this issue, we reformulate the problem of adversarial attacks in function space and separate the previous gradient based attacks into several subspace. Following the analysis of the function space, we design a generic two-stage framework in the subspace where the adversary lures the agent to a target trajectory or a deceptive policy. In the first stage, we train a deceptive policy by hacking the environment, and discover a set of trajectories routing to the lowest reward. The adversary then misleads the victim to imitate the deceptive policy by perturbing the observations. Our method provides a tighter theoretical upper bound for the attacked agent's performance than the existing approaches. Extensive experiments demonstrate the superiority of our method and we achieve the state-of-the-art performance on both Atari and MuJoCo environments.