 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Safe Reinforcement Learning via Constraining Conditional Value-at-Risk
Paper and Code
Jun 09, 2022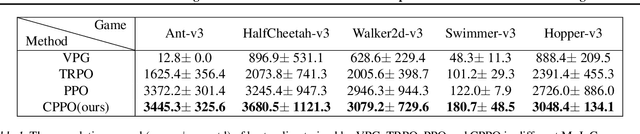
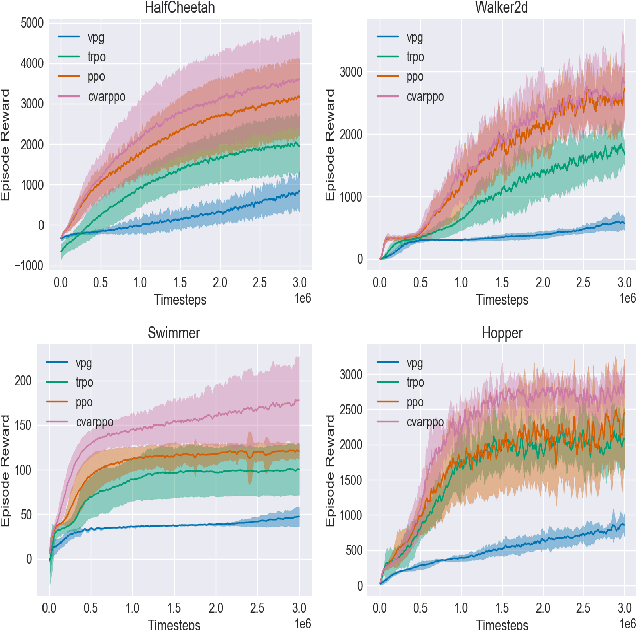
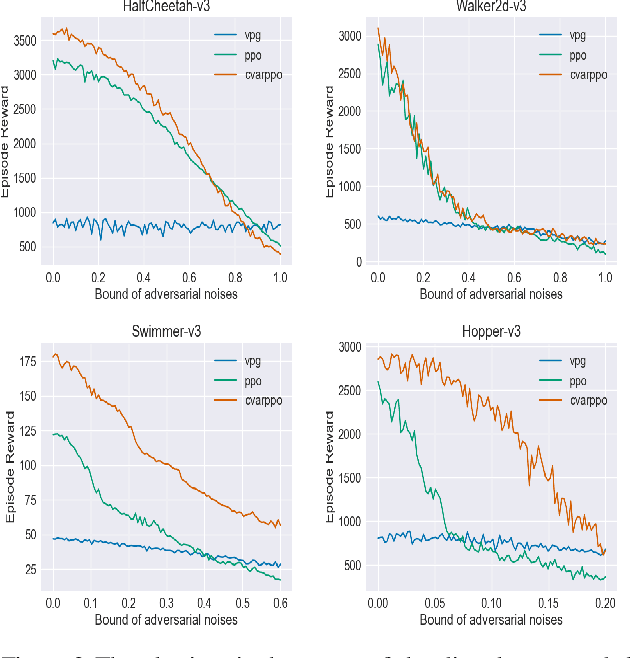
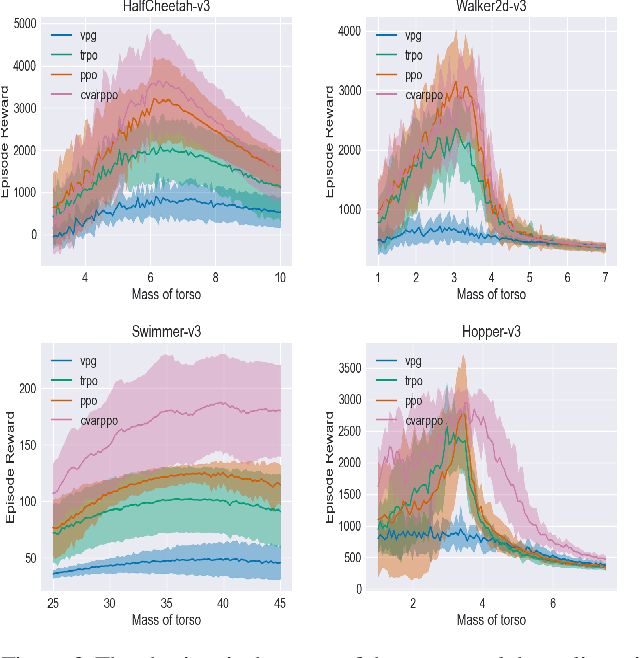
Though deep reinforcement learning (DRL) has obtained substantial success, it may encounter catastrophic failures due to the intrinsic uncertainty of both transition and observation. Most of the existing methods for safe reinforcement learning can only handle transition disturbance or observation disturbance since these two kinds of disturbance affect different parts of the agent; besides, the popular worst-case return may lead to overly pessimistic policies. To address these issues, we first theoretically prove that the performance degradation under transition disturbance and observation disturbance depends on a novel metric of Value Function Range (VFR), which corresponds to the gap in the value function between the best state and the worst state. Based on the analysis, we adopt conditional value-at-risk (CVaR) as an assessment of risk and propose a novel reinforcement learning algorithm of CVaR-Proximal-Policy-Optimization (CPPO) which formalizes the risk-sensitive constrained optimization problem by keeping its CVaR under a given threshold. Experimental results show that CPPO achieves a higher cumulative reward and is more robust against both observation and transition disturbances on a series of continuous control tasks in MuJoCo.