 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Physical Directions in Weight Space: Composing Neural PDE Experts
May 14, 2026Recent advances in neural operators have made partial differential equation (PDE) surrogate modeling increasingly scalable and transferable through large-scale pretraining and in-context adaptation. However, after a shared operator is fine-tuned to multiple regimes within a continuous physical family, it remains unclear whether the resulting weight-space updates merely form isolated regime experts or reveal reusable physical structure. Starting from a shared family anchor, we fine-tune low- and high-regime endpoint experts and show that their updates can be separated into a family-shared adaptation and a direction aligned with the underlying physical parameter. This separation reinterprets endpoint experts as finite-difference probes of a local physical direction in weight space, explaining why static averaging can interpolate between regimes but attenuates endpoint-specific physics. Building on this perspective, we propose Calibration-Conditioned Merge (CCM), a post-hoc coordinate readout method for composing neural PDE experts along this physical direction. Given physical metadata, a calibrated coordinate mapping, or a short observed rollout prefix, CCM infers the target composition coordinate and deploys a single merged checkpoint for the remaining rollout. We evaluate CCM on the reaction--diffusion system, viscosity-parameterized two-dimensional Navier--Stokes equations, and radial dam-break dynamics. Across these benchmarks, CCM achieves its strongest gains in extrapolative regimes, reducing out-of-distribution rollout error relative to the family anchor by 54.2%, 42.8%, and 13.8%, respectively. Further experiments across FNO scales, a DPOT-style backbone, and ablations confirm that endpoint fine-tuning is not arbitrary checkpoint drift, but reveals a calibratable physical direction for training-free transfer across PDE regimes.
Helix: Evolutionary Reinforcement Learning for Open-Ended Scientific Problem Solving
Mar 08, 2026Large language models (LLMs) with reasoning abilities have demonstrated growing promise for tackling complex scientific problems. Yet such tasks are inherently domain-specific, unbounded and open-ended, demanding exploration across vast and flexible solution spaces. Existing approaches, whether purely learning-based or reliant on carefully designed workflows, often suffer from limited exploration efficiency and poor generalization. To overcome these challenges, we present HELIX -- a Hierarchical Evolutionary reinforcement Learning framework with In-context eXperiences. HELIX introduces two key novelties: (i) a diverse yet high-quality pool of candidate solutions that broadens exploration through in-context learning, and (ii) reinforcement learning for iterative policy refinement that progressively elevates solution quality. This synergy enables the discovery of more advanced solutions. On the circle packing task, HELIX achieves state-of-the-art result with a sum of radii of 2.63598308 using only a 14B model. Across standard machine learning benchmarks, HELIX further surpasses GPT-4o with a carefully engineered pipeline, delivering an average F1 improvement of 5.95 points on the Adult and Bank Marketing datasets.
A$^2$Search: Ambiguity-Aware Question Answering with Reinforcement Learning
Oct 09, 2025



Recent advances in Large Language Models (LLMs) and Reinforcement Learning (RL) have led to strong performance in open-domain question answering (QA). However, existing models still struggle with questions that admit multiple valid answers. Standard QA benchmarks, which typically assume a single gold answer, overlook this reality and thus produce inappropriate training signals. Existing attempts to handle ambiguity often rely on costly manual annotation, which is difficult to scale to multi-hop datasets such as HotpotQA and MuSiQue. In this paper, we present A$^2$Search, an annotation-free, end-to-end training framework to recognize and handle ambiguity. At its core is an automated pipeline that detects ambiguous questions and gathers alternative answers via trajectory sampling and evidence verification. The model is then optimized with RL using a carefully designed $\mathrm{AnsF1}$ reward, which naturally accommodates multiple answers. Experiments on eight open-domain QA benchmarks demonstrate that A$^2$Search achieves new state-of-the-art performance. With only a single rollout, A$^2$Search-7B yields an average $\mathrm{AnsF1}@1$ score of $48.4\%$ across four multi-hop benchmarks, outperforming all strong baselines, including the substantially larger ReSearch-32B ($46.2\%$). Extensive analyses further show that A$^2$Search resolves ambiguity and generalizes across benchmarks, highlighting that embracing ambiguity is essential for building more reliable QA systems. Our code, data, and model weights can be found at https://github.com/zfj1998/A2Search
Accelerating PDE-Constrained Optimization by the Derivative of Neural Operators
Jun 16, 2025PDE-Constrained Optimization (PDECO) problems can be accelerated significantly by employing gradient-based methods with surrogate models like neural operators compared to traditional numerical solvers. However, this approach faces two key challenges: (1) **Data inefficiency**: Lack of efficient data sampling and effective training for neural operators, particularly for optimization purpose. (2) **Instability**: High risk of optimization derailment due to inaccurate neural operator predictions and gradients. To address these challenges, we propose a novel framework: (1) **Optimization-oriented training**: we leverage data from full steps of traditional optimization algorithms and employ a specialized training method for neural operators. (2) **Enhanced derivative learning**: We introduce a *Virtual-Fourier* layer to enhance derivative learning within the neural operator, a crucial aspect for gradient-based optimization. (3) **Hybrid optimization**: We implement a hybrid approach that integrates neural operators with numerical solvers, providing robust regularization for the optimization process. Our extensive experimental results demonstrate the effectiveness of our model in accurately learning operators and their derivatives. Furthermore, our hybrid optimization approach exhibits robust convergence.
Exploratory Diffusion Policy for Unsupervised Reinforcement Learning
Feb 11, 2025



Unsupervised reinforcement learning (RL) aims to pre-train agents by exploring states or skills in reward-free environments, facilitating the adaptation to downstream tasks. However, existing methods often overlook the fitting ability of pre-trained policies and struggle to handle the heterogeneous pre-training data, which are crucial for achieving efficient exploration and fast fine-tuning. To address this gap, we propose Exploratory Diffusion Policy (EDP), which leverages the strong expressive ability of diffusion models to fit the explored data, both boosting exploration and obtaining an efficient initialization for downstream tasks. Specifically, we estimate the distribution of collected data in the replay buffer with the diffusion policy and propose a score intrinsic reward, encouraging the agent to explore unseen states. For fine-tuning the pre-trained diffusion policy on downstream tasks, we provide both theoretical analyses and practical algorithms, including an alternating method of Q function optimization and diffusion policy distillation. Extensive experiments demonstrate the effectiveness of EDP in efficient exploration during pre-training and fast adaptation during fine-tuning.
PAPM: A Physics-aware Proxy Model for Process Systems
Jul 07, 2024



In the context of proxy modeling for process systems, traditional data-driven deep learning approaches frequently encounter significant challenges, such as substantial training costs induced by large amounts of data, and limited generalization capabilities. As a promising alternative, physics-aware models incorporate partial physics knowledge to ameliorate these challenges. Although demonstrating efficacy, they fall short in terms of exploration depth and universality. To address these shortcomings, we introduce a physics-aware proxy model (PAPM) that fully incorporates partial prior physics of process systems, which includes multiple input conditions and the general form of conservation relations, resulting in better out-of-sample generalization. Additionally, PAPM contains a holistic temporal-spatial stepping module for flexible adaptation across various process systems. Through systematic comparisons with state-of-the-art pure data-driven and physics-aware models across five two-dimensional benchmarks in nine generalization tasks, PAPM notably achieves an average performance improvement of 6.7%, while requiring fewer FLOPs, and just 1% of the parameters compared to the prior leading method. The code is available at https://github.com/pengwei07/PAPM.
Reference Neural Operators: Learning the Smooth Dependence of Solutions of PDEs on Geometric Deformations
May 27, 2024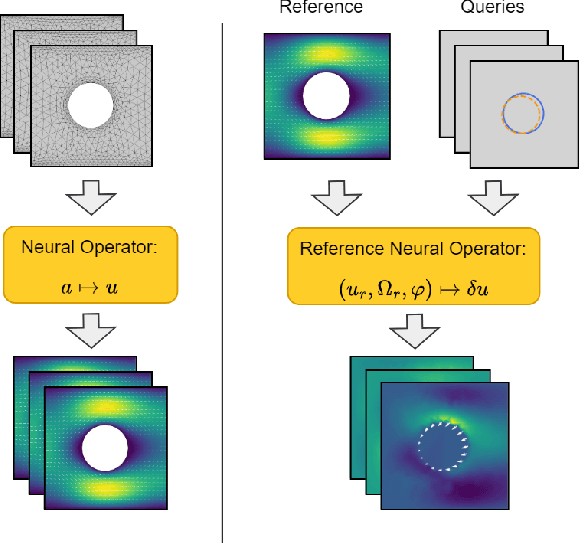
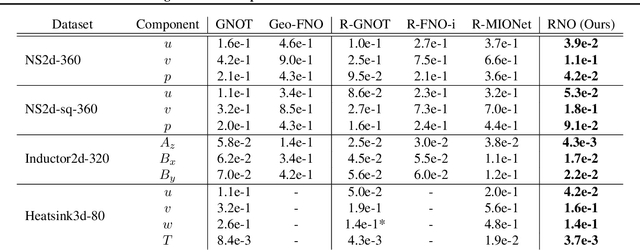
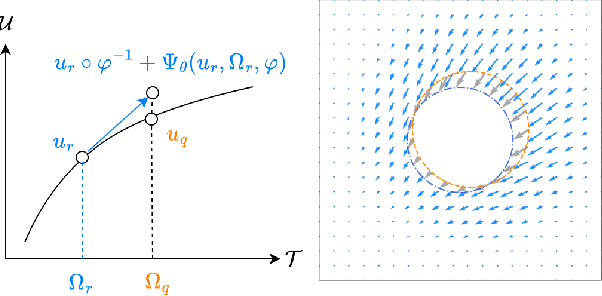

For partial differential equations on domains of arbitrary shapes, existing works of neural operators attempt to learn a mapping from geometries to solutions. It often requires a large dataset of geometry-solution pairs in order to obtain a sufficiently accurate neural operator. However, for many industrial applications, e.g., engineering design optimization, it can be prohibitive to satisfy the requirement since even a single simulation may take hours or days of computation. To address this issue, we propose reference neural operators (RNO), a novel way of implementing neural operators, i.e., to learn the smooth dependence of solutions on geometric deformations. Specifically, given a reference solution, RNO can predict solutions corresponding to arbitrary deformations of the referred geometry. This approach turns out to be much more data efficient. Through extensive experiments, we show that RNO can learn the dependence across various types and different numbers of geometry objects with relatively small datasets. RNO outperforms baseline models in accuracy by a large lead and achieves up to 80% error reduction.
PEAC: Unsupervised Pre-training for Cross-Embodiment Reinforcement Learning
May 23, 2024Designing generalizable agents capable of adapting to diverse embodiments has achieved significant attention in Reinforcement Learning (RL), which is critical for deploying RL agents in various real-world applications. Previous Cross-Embodiment RL approaches have focused on transferring knowledge across embodiments within specific tasks. These methods often result in knowledge tightly coupled with those tasks and fail to adequately capture the distinct characteristics of different embodiments. To address this limitation, we introduce the notion of Cross-Embodiment Unsupervised RL (CEURL), which leverages unsupervised learning to enable agents to acquire embodiment-aware and task-agnostic knowledge through online interactions within reward-free environments. We formulate CEURL as a novel Controlled Embodiment Markov Decision Process (CE-MDP) and systematically analyze CEURL's pre-training objectives under CE-MDP. Based on these analyses, we develop a novel algorithm Pre-trained Embodiment-Aware Control (PEAC) for handling CEURL, incorporating an intrinsic reward function specifically designed for cross-embodiment pre-training. PEAC not only provides an intuitive optimization strategy for cross-embodiment pre-training but also can integrate flexibly with existing unsupervised RL methods, facilitating cross-embodiment exploration and skill discovery. Extensive experiments in both simulated (e.g., DMC and Robosuite) and real-world environments (e.g., legged locomotion) demonstrate that PEAC significantly improves adaptation performance and cross-embodiment generalization, demonstrating its effectiveness in overcoming the unique challenges of CEURL.
DPOT: Auto-Regressive Denoising Operator Transformer for Large-Scale PDE Pre-Training
Mar 08, 2024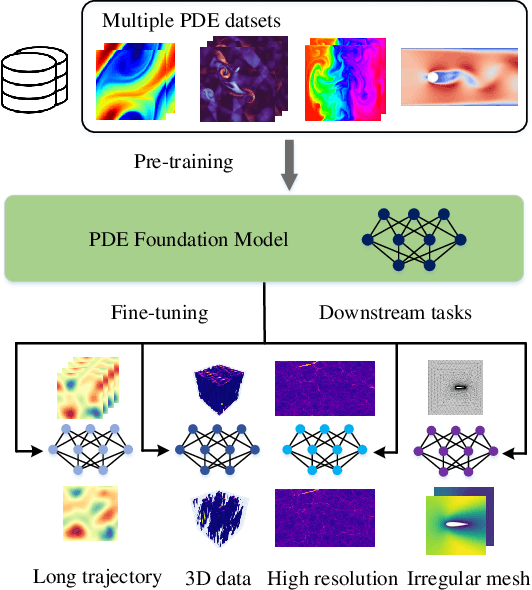
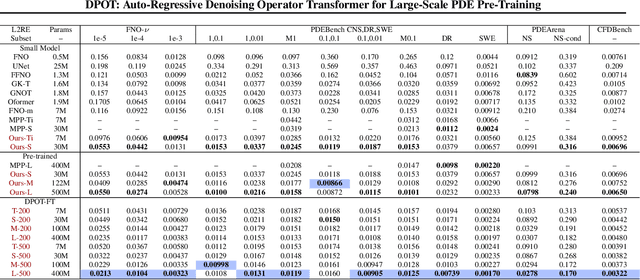
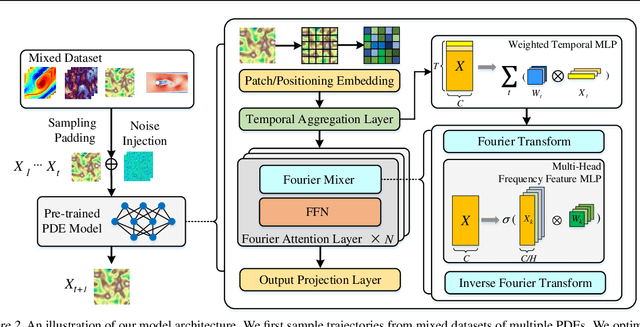
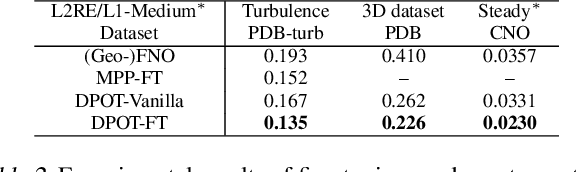
Pre-training has been investigated to improve the efficiency and performance of training neural operators in data-scarce settings. However, it is largely in its infancy due to the inherent complexity and diversity, such as long trajectories, multiple scales and varying dimensions of partial differential equations (PDEs) data. In this paper, we present a new auto-regressive denoising pre-training strategy, which allows for more stable and efficient pre-training on PDE data and generalizes to various downstream tasks. Moreover, by designing a flexible and scalable model architecture based on Fourier attention, we can easily scale up the model for large-scale pre-training. We train our PDE foundation model with up to 0.5B parameters on 10+ PDE datasets with more than 100k trajectories. Extensive experiments show that we achieve SOTA on these benchmarks and validate the strong generalizability of our model to significantly enhance performance on diverse downstream PDE tasks like 3D data. Code is available at \url{https://github.com/thu-ml/DPOT}.
Your Diffusion Model is Secretly a Certifiably Robust Classifier
Feb 13, 2024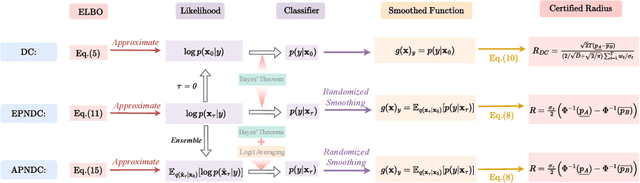


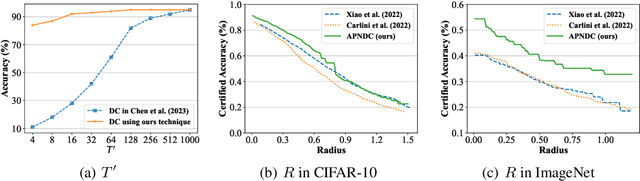
Diffusion models are recently employed as generative classifiers for robust classification. However, a comprehensive theoretical understanding of the robustness of diffusion classifiers is still lacking, leading us to question whether they will be vulnerable to future stronger attacks. In this study, we propose a new family of diffusion classifiers, named Noised Diffusion Classifiers~(NDCs), that possess state-of-the-art certified robustness. Specifically, we generalize the diffusion classifiers to classify Gaussian-corrupted data by deriving the evidence lower bounds (ELBOs) for these distributions, approximating the likelihood using the ELBO, and calculating classification probabilities via Bayes' theorem. We integrate these generalized diffusion classifiers with randomized smoothing to construct smoothed classifiers possessing non-constant Lipschitzness. Experimental results demonstrate the superior certified robustness of our proposed NDCs. Notably, we are the first to achieve 80\%+ and 70\%+ certified robustness on CIFAR-10 under adversarial perturbations with $\ell_2$ norm less than 0.25 and 0.5, respectively, using a single off-the-shelf diffusion model without any additional data.