 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPOT: Auto-Regressive Denoising Operator Transformer for Large-Scale PDE Pre-Training
Paper and Code
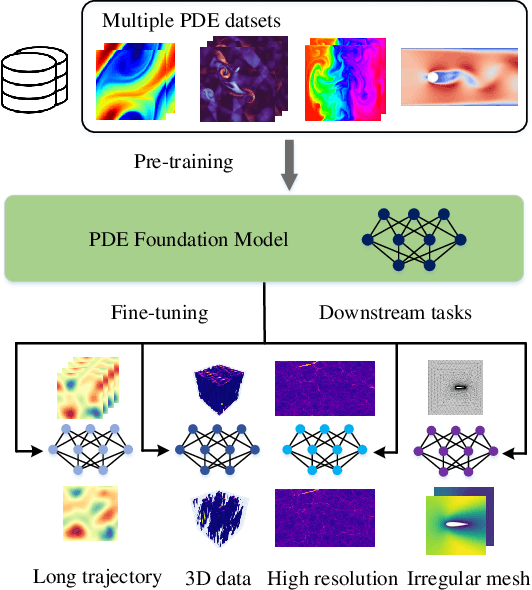
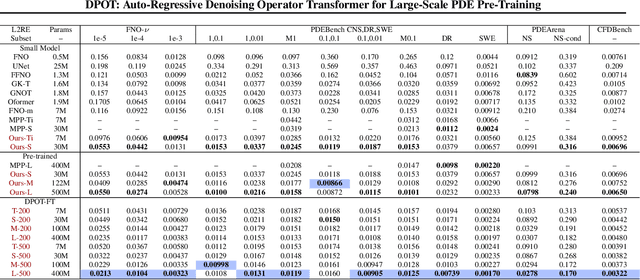
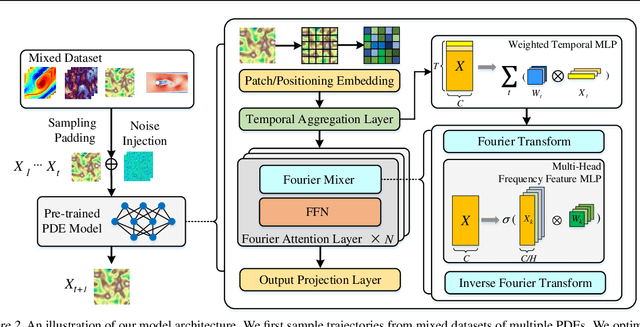
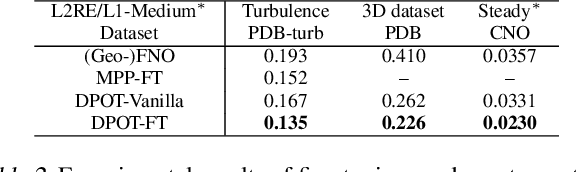
Pre-training has been investigated to improve the efficiency and performance of training neural operators in data-scarce settings. However, it is largely in its infancy due to the inherent complexity and diversity, such as long trajectories, multiple scales and varying dimensions of partial differential equations (PDEs) data. In this paper, we present a new auto-regressive denoising pre-training strategy, which allows for more stable and efficient pre-training on PDE data and generalizes to various downstream tasks. Moreover, by designing a flexible and scalable model architecture based on Fourier attention, we can easily scale up the model for large-scale pre-training. We train our PDE foundation model with up to 0.5B parameters on 10+ PDE datasets with more than 100k trajectories. Extensive experiments show that we achieve SOTA on these benchmarks and validate the strong generalizability of our model to significantly enhance performance on diverse downstream PDE tasks like 3D data. Code is available at \url{https://github.com/thu-ml/DPOT}.