 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Full Waveform Inversion Assisted by Rytov Approximation for Musculoskeletal Ultrasound Computed Tomography
May 24, 2026Ultrasound computed tomography is emerging as a promising safe and accessible modality for soft-tissue medical imaging, with full waveform inversion playing a key role in unlocking its full potential for high-resolution, quantitative reconstructions. Frequency domain full waveform inversion (FDFWI) for reconstructing spatial maps of acoustic properties in the musculoskeletal system is highly sensitive to the quality of low-frequency signals, making the final imaging outcome vulnerable to issues such as inappropriate initial models and strong scatterings related to bones. To address these challenges, we propose a hybrid full waveform inversion (HFWI) algorithm that incorporates a traveltime inversion algorithm based on the generalized Rytov approximation into the FDFWI framework. This hybrid strategy enhances early-stage inversion quality and substantially reduces sensitivity to the initial model, all while maintaining computational efficiency. Importantly, HFWI achieves results comparable to those obtained using well-constructed initial models, without incurring extra computational cost, thus enabling accurate imaging under realistic, bandwidth-limited conditions. In addition, we introduce a near real-time strategy to update first-arrival traveltimes based on forward-scattered phase variations without requiring extra wavefield simulations. Numerical simulations, as well as \textit{in vitro} and \textit{in vivo} experiments confirm the robustness and efficiency of the proposed approach. HFWI also shows promise to extend to more complex scenarios of musculoskeletal parametric reconstruction.
Evaluation-driven Scaling for Scientific Discovery
Apr 21, 2026Language models are increasingly used in scientific discovery to generate hypotheses, propose candidate solutions, implement systems, and iteratively refine them. At the core of these trial-and-error loops lies evaluation: the process of obtaining feedback on candidate solutions via verifiers, simulators, or task-specific scoring functions. While prior work has highlighted the importance of evaluation, it has not explicitly formulated the problem of how evaluation-driven discovery loops can be scaled up in a principled and effective manner to push the boundaries of scientific discovery, a problem this paper seeks to address. We introduce Simple Test-time Evaluation-driven Scaling (SimpleTES), a general framework that strategically combines parallel exploration, feedback-driven refinement, and local selection, revealing substantial gains unlocked by scaling evaluation-driven discovery loops along the right dimensions. Across 21 scientific problems spanning six domains, SimpleTES discovers state-of-the-art solutions using gpt-oss models, consistently outperforming both frontier-model baselines and sophisticated optimization pipelines. Particularly, we sped up the widely used LASSO algorithm by over 2x, designed quantum circuit routing policies that reduce gate overhead by 24.5%, and discovered new Erdos minimum overlap constructions that surpass the best-known results. Beyond novel discoveries, SimpleTES produces trajectory-level histories that naturally supervise feedback-driven learning. When post-trained on successful trajectories, models not only improve efficiency on seen problems but also generalize to unseen problems, discovering solutions that base models fail to uncover. Together, our results establish effective evaluation-driven loop scaling as a central axis for advancing LLM-driven scientific discovery, and provide a simple yet practical framework for realizing these gains.
Helix: Evolutionary Reinforcement Learning for Open-Ended Scientific Problem Solving
Mar 08, 2026Large language models (LLMs) with reasoning abilities have demonstrated growing promise for tackling complex scientific problems. Yet such tasks are inherently domain-specific, unbounded and open-ended, demanding exploration across vast and flexible solution spaces. Existing approaches, whether purely learning-based or reliant on carefully designed workflows, often suffer from limited exploration efficiency and poor generalization. To overcome these challenges, we present HELIX -- a Hierarchical Evolutionary reinforcement Learning framework with In-context eXperiences. HELIX introduces two key novelties: (i) a diverse yet high-quality pool of candidate solutions that broadens exploration through in-context learning, and (ii) reinforcement learning for iterative policy refinement that progressively elevates solution quality. This synergy enables the discovery of more advanced solutions. On the circle packing task, HELIX achieves state-of-the-art result with a sum of radii of 2.63598308 using only a 14B model. Across standard machine learning benchmarks, HELIX further surpasses GPT-4o with a carefully engineered pipeline, delivering an average F1 improvement of 5.95 points on the Adult and Bank Marketing datasets.
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
In vivo 3D ultrasound computed tomography of musculoskeletal tissues with generative neural physics
Aug 17, 2025Ultrasound computed tomography (USCT) is a radiation-free, high-resolution modality but remains limited for musculoskeletal imaging due to conventional ray-based reconstructions that neglect strong scattering. We propose a generative neural physics framework that couples generative networks with physics-informed neural simulation for fast, high-fidelity 3D USCT. By learning a compact surrogate of ultrasonic wave propagation from only dozens of cross-modality images, our method merges the accuracy of wave modeling with the efficiency and stability of deep learning. This enables accurate quantitative imaging of in vivo musculoskeletal tissues, producing spatial maps of acoustic properties beyond reflection-mode images. On synthetic and in vivo data (breast, arm, leg), we reconstruct 3D maps of tissue parameters in under ten minutes, with sensitivity to biomechanical properties in muscle and bone and resolution comparable to MRI. By overcoming computational bottlenecks in strongly scattering regimes, this approach advances USCT toward routine clinical assessment of musculoskeletal disease.
X-MoGen: Unified Motion Generation across Humans and Animals
Aug 07, 2025Text-driven motion generation has attracted increasing attention due to its broad applications in virtual reality, animation, and robotics. While existing methods typically model human and animal motion separately, a joint cross-species approach offers key advantages, such as a unified representation and improved generalization. However, morphological differences across species remain a key challenge, often compromising motion plausibility. To address this, we propose \textbf{X-MoGen}, the first unified framework for cross-species text-driven motion generation covering both humans and animals. X-MoGen adopts a two-stage architecture. First, a conditional graph variational autoencoder learns canonical T-pose priors, while an autoencoder encodes motion into a shared latent space regularized by morphological loss. In the second stage, we perform masked motion modeling to generate motion embeddings conditioned on textual descriptions. During training, a morphological consistency module is employed to promote skeletal plausibility across species. To support unified modeling, we construct \textbf{UniMo4D}, a large-scale dataset of 115 species and 119k motion sequences, which integrates human and animal motions under a shared skeletal topology for joint training. Extensive experiments on UniMo4D demonstrate that X-MoGen outperforms state-of-the-art methods on both seen and unseen species.
ELSPR: Evaluator LLM Training Data Self-Purification on Non-Transitive Preferences via Tournament Graph Reconstruction
May 23, 2025Large language models (LLMs) are widely used as evaluators for open-ended tasks, while previous research has emphasized biases in LLM evaluations, the issue of non-transitivity in pairwise comparisons remains unresolved: non-transitive preferences for pairwise comparisons, where evaluators prefer A over B, B over C, but C over A. Our results suggest that low-quality training data may reduce the transitivity of preferences generated by the Evaluator LLM. To address this, We propose a graph-theoretic framework to analyze and mitigate this problem by modeling pairwise preferences as tournament graphs. We quantify non-transitivity and introduce directed graph structural entropy to measure the overall clarity of preferences. Our analysis reveals significant non-transitivity in advanced Evaluator LLMs (with Qwen2.5-Max exhibiting 67.96%), as well as high entropy values (0.8095 for Qwen2.5-Max), reflecting low overall clarity of preferences. To address this issue, we designed a filtering strategy, ELSPR, to eliminate preference data that induces non-transitivity, retaining only consistent and transitive preference data for model fine-tuning. Experiments demonstrate that models fine-tuned with filtered data reduce non-transitivity by 13.78% (from 64.28% to 50.50%), decrease structural entropy by 0.0879 (from 0.8113 to 0.7234), and align more closely with human evaluators (human agreement rate improves by 0.6% and Spearman correlation increases by 0.01).
MIDB: Multilingual Instruction Data Booster for Enhancing Multilingual Instruction Synthesis
May 23, 2025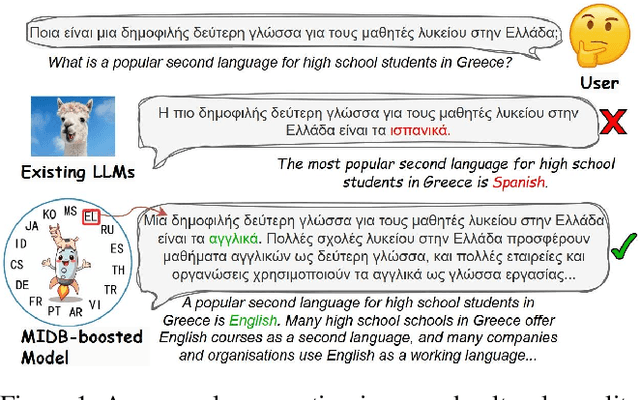
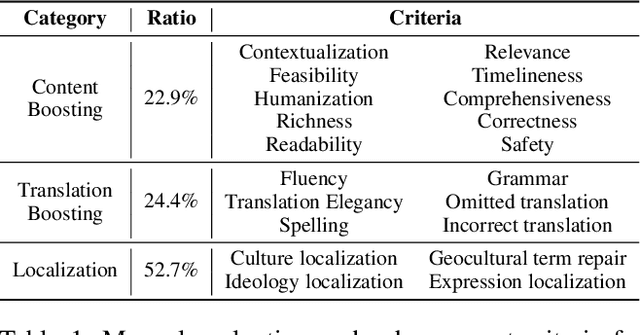
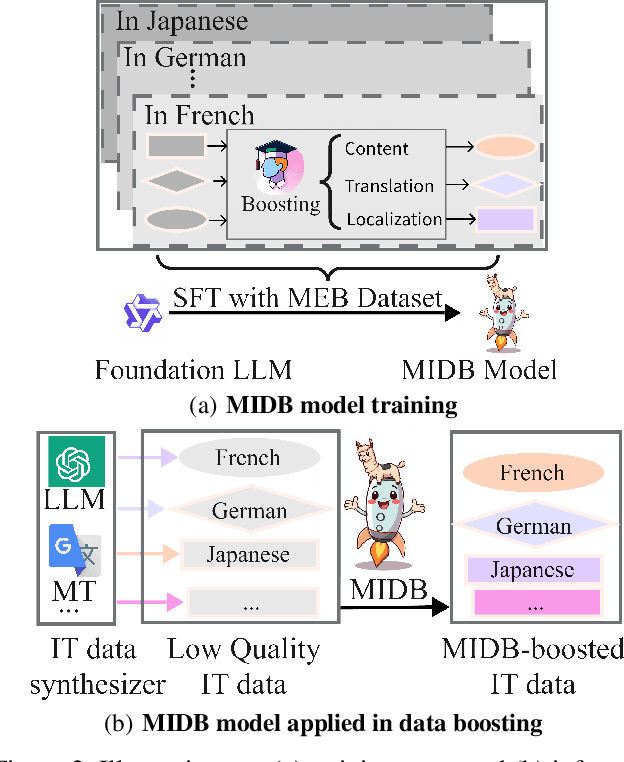
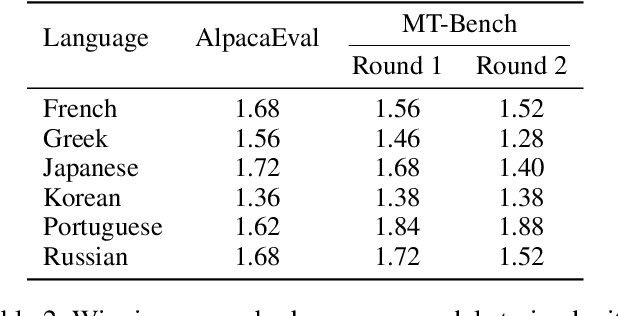
Despite doubts on data quality, instruction synthesis has been widely applied into instruction tuning (IT) of LLMs as an economic and rapid alternative. Recent endeavors focus on improving data quality for synthesized instruction pairs in English and have facilitated IT of English-centric LLMs. However, data quality issues in multilingual synthesized instruction pairs are even more severe, since the common synthesizing practice is to translate English synthesized data into other languages using machine translation (MT). Besides the known content errors in these English synthesized data, multilingual synthesized instruction data are further exposed to defects introduced by MT and face insufficient localization of the target languages. In this paper, we propose MIDB, a Multilingual Instruction Data Booster to automatically address the quality issues in multilingual synthesized data. MIDB is trained on around 36.8k revision examples across 16 languages by human linguistic experts, thereby can boost the low-quality data by addressing content errors and MT defects, and improving localization in these synthesized data. Both automatic and human evaluation indicate that not only MIDB steadily improved instruction data quality in 16 languages, but also the instruction-following and cultural-understanding abilities of multilingual LLMs fine-tuned on MIDB-boosted data were significantly enhanced.
Under-Sampled High-Dimensional Data Recovery via Symbiotic Multi-Prior Tensor Reconstruction
Apr 08, 2025The advancement of sensing technology has driven the widespread application of high-dimensional data. However, issues such as missing entries during acquisition and transmission negatively impact the accuracy of subsequent tasks. Tensor reconstruction aims to recover the underlying complete data from under-sampled observed data by exploring prior information in high-dimensional data. However, due to insufficient exploration, reconstruction methods still face challenges when sampling rate is extremely low. This work proposes a tensor reconstruction method integrating multiple priors to comprehensively exploit the inherent structure of the data. Specifically, the method combines learnable tensor decomposition to enforce low-rank constraints of the reconstructed data, a pre-trained convolutional neural network for smoothing and denoising, and block-matching and 3D filtering regularization to enhance the non-local similarity in the reconstructed data. An alternating direction method of the multipliers algorithm is designed to decompose the resulting optimization problem into three subproblems for efficient resolution. Extensive experiments on color images, hyperspectral images, and grayscale videos datasets demonstrate the superiority of our method in extreme cases as compared with state-of-the-art methods.
SCOPE-DTI: Semi-Inductive Dataset Construction and Framework Optimization for Practical Usability Enhancement in Deep Learning-Based Drug Target Interaction Prediction
Mar 12, 2025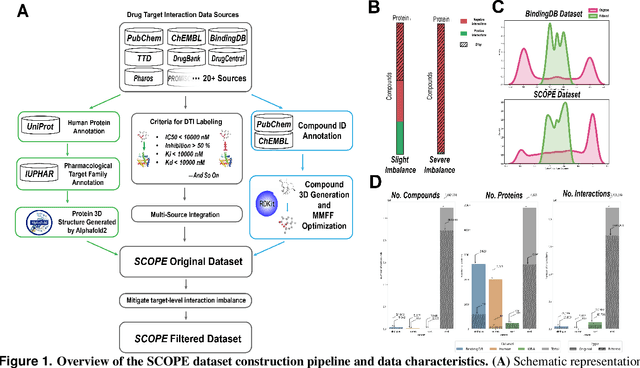
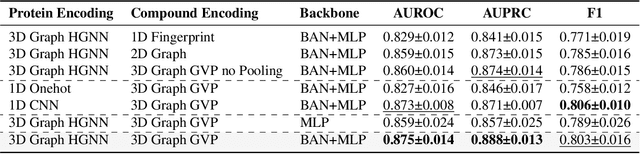
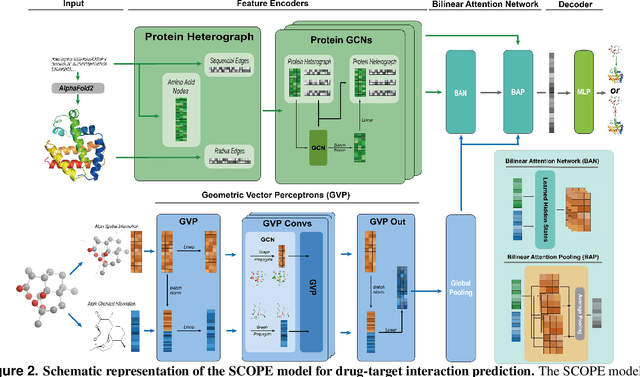
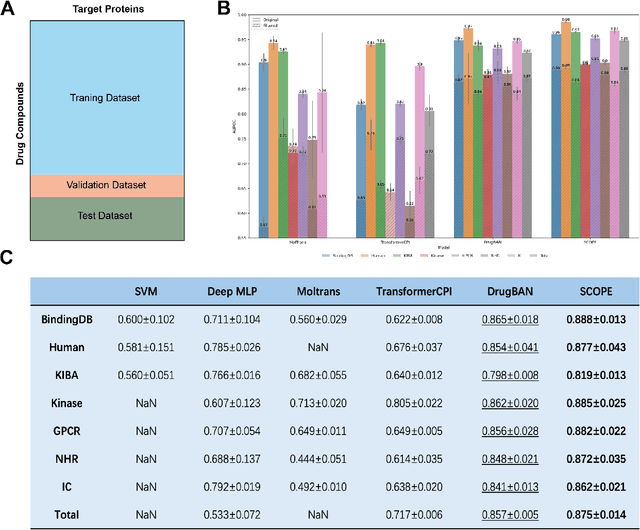
Deep learning-based drug-target interaction (DTI) prediction methods have demonstrated strong performance; however, real-world applicability remains constrained by limited data diversity and modeling complexity. To address these challenges, we propose SCOPE-DTI, a unified framework combining a large-scale, balanced semi-inductive human DTI dataset with advanced deep learning modeling. Constructed from 13 public repositories, the SCOPE dataset expands data volume by up to 100-fold compared to common benchmarks such as the Human dataset. The SCOPE model integrates three-dimensional protein and compound representations, graph neural networks, and bilinear attention mechanisms to effectively capture cross domain interaction patterns, significantly outperforming state-of-the-art methods across various DTI prediction tasks. Additionally, SCOPE-DTI provides a user-friendly interface and database. We further validate its effectiveness by experimentally identifying anticancer targets of Ginsenoside Rh1. By offering comprehensive data, advanced modeling, and accessible tools, SCOPE-DTI accelerates drug discovery research.