 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoison Once, Exploit Forever: Environment-Injected Memory Poisoning Attacks on Web Agents
Apr 03, 2026Memory makes LLM-based web agents personalized, powerful, yet exploitable. By storing past interactions to personalize future tasks, agents inadvertently create a persistent attack surface that spans websites and sessions. While existing security research on memory assumes attackers can directly inject into memory storage or exploit shared memory across users, we present a more realistic threat model: contamination through environmental observation alone. We introduce Environment-injected Trajectory-based Agent Memory Poisoning (eTAMP), the first attack to achieve cross-session, cross-site compromise without requiring direct memory access. A single contaminated observation (e.g., viewing a manipulated product page) silently poisons an agent's memory and activates during future tasks on different websites, bypassing permission-based defenses. Our experiments on (Visual)WebArena reveal two key findings. First, eTAMP achieves substantial attack success rates: up to 32.5% on GPT-5-mini, 23.4% on GPT-5.2, and 19.5% on GPT-OSS-120B. Second, we discover Frustration Exploitation: agents under environmental stress become dramatically more susceptible, with ASR increasing up to 8 times when agents struggle with dropped clicks or garbled text. Notably, more capable models are not more secure. GPT-5.2 shows substantial vulnerability despite superior task performance. With the rise of AI browsers like OpenClaw, ChatGPT Atlas, and Perplexity Comet, our findings underscore the urgent need for defenses against environment-injected memory poisoning.
MGPC: Multimodal Network for Generalizable Point Cloud Completion With Modality Dropout and Progressive Decoding
Jan 07, 2026Point cloud completion aims to recover complete 3D geometry from partial observations caused by limited viewpoints and occlusions. Existing learning-based works, including 3D Convolutional Neural Network (CNN)-based, point-based, and Transformer-based methods, have achieved strong performance on synthetic benchmarks. However, due to the limitations of modality, scalability, and generative capacity, their generalization to novel objects and real-world scenarios remains challenging. In this paper, we propose MGPC, a generalizable multimodal point cloud completion framework that integrates point clouds, RGB images, and text within a unified architecture. MGPC introduces an innovative modality dropout strategy, a Transformer-based fusion module, and a novel progressive generator to improve robustness, scalability, and geometric modeling capability. We further develop an automatic data generation pipeline and construct MGPC-1M, a large-scale benchmark with over 1,000 categories and one million training pairs. Extensive experiments on MGPC-1M and in-the-wild data demonstrate that the proposed method consistently outperforms prior baselines and exhibits strong generalization under real-world conditions.
AudioStory: Generating Long-Form Narrative Audio with Large Language Models
Aug 27, 2025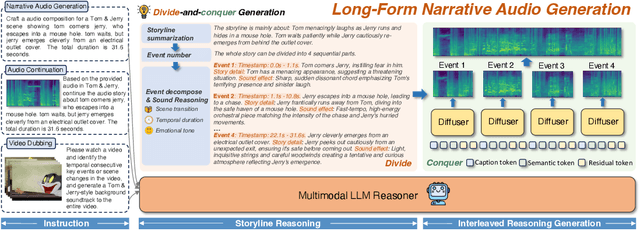
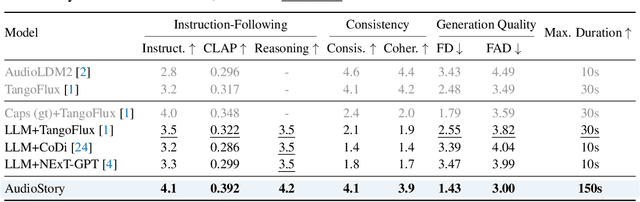
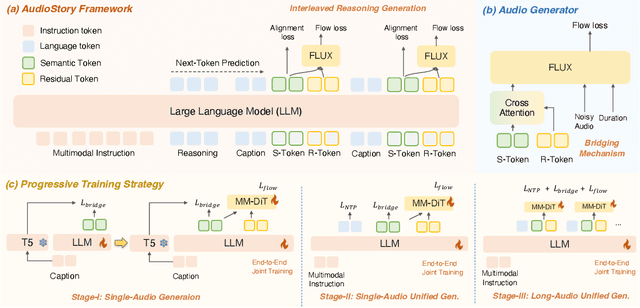

Recent advances in text-to-audio (TTA) generation excel at synthesizing short audio clips but struggle with long-form narrative audio, which requires temporal coherence and compositional reasoning. To address this gap, we propose AudioStory, a unified framework that integrates large language models (LLMs) with TTA systems to generate structured, long-form audio narratives. AudioStory possesses strong instruction-following reasoning generation capabilities. It employs LLMs to decompose complex narrative queries into temporally ordered sub-tasks with contextual cues, enabling coherent scene transitions and emotional tone consistency. AudioStory has two appealing features: (1) Decoupled bridging mechanism: AudioStory disentangles LLM-diffuser collaboration into two specialized components, i.e., a bridging query for intra-event semantic alignment and a residual query for cross-event coherence preservation. (2) End-to-end training: By unifying instruction comprehension and audio generation within a single end-to-end framework, AudioStory eliminates the need for modular training pipelines while enhancing synergy between components. Furthermore, we establish a benchmark AudioStory-10K, encompassing diverse domains such as animated soundscapes and natural sound narratives. Extensive experiments show the superiority of AudioStory on both single-audio generation and narrative audio generation, surpassing prior TTA baselines in both instruction-following ability and audio fidelity. Our code is available at https://github.com/TencentARC/AudioStory
TracLLM: A Generic Framework for Attributing Long Context LLMs
Jun 06, 2025Long context large language models (LLMs) are deployed in many real-world applications such as RAG, agent, and broad LLM-integrated applications. Given an instruction and a long context (e.g., documents, PDF files, webpages), a long context LLM can generate an output grounded in the provided context, aiming to provide more accurate, up-to-date, and verifiable outputs while reducing hallucinations and unsupported claims. This raises a research question: how to pinpoint the texts (e.g., sentences, passages, or paragraphs) in the context that contribute most to or are responsible for the generated output by an LLM? This process, which we call context traceback, has various real-world applications, such as 1) debugging LLM-based systems, 2) conducting post-attack forensic analysis for attacks (e.g., prompt injection attack, knowledge corruption attacks) to an LLM, and 3) highlighting knowledge sources to enhance the trust of users towards outputs generated by LLMs. When applied to context traceback for long context LLMs, existing feature attribution methods such as Shapley have sub-optimal performance and/or incur a large computational cost. In this work, we develop TracLLM, the first generic context traceback framework tailored to long context LLMs. Our framework can improve the effectiveness and efficiency of existing feature attribution methods. To improve the efficiency, we develop an informed search based algorithm in TracLLM. We also develop contribution score ensemble/denoising techniques to improve the accuracy of TracLLM. Our evaluation results show TracLLM can effectively identify texts in a long context that lead to the output of an LLM. Our code and data are at: https://github.com/Wang-Yanting/TracLLM.
SARI: Structured Audio Reasoning via Curriculum-Guided Reinforcement Learning
Apr 22, 2025Recent work shows that reinforcement learning(RL) can markedly sharpen the reasoning ability of large language models (LLMs) by prompting them to "think before answering." Yet whether and how these gains transfer to audio-language reasoning remains largely unexplored. We extend the Group-Relative Policy Optimization (GRPO) framework from DeepSeek-R1 to a Large Audio-Language Model (LALM), and construct a 32k sample multiple-choice corpus. Using a two-stage regimen supervised fine-tuning on structured and unstructured chains-of-thought, followed by curriculum-guided GRPO, we systematically compare implicit vs. explicit, and structured vs. free form reasoning under identical architectures. Our structured audio reasoning model, SARI (Structured Audio Reasoning via Curriculum-Guided Reinforcement Learning), achieves a 16.35% improvement in average accuracy over the base model Qwen2-Audio-7B-Instruct. Furthermore, the variant built upon Qwen2.5-Omni reaches state-of-the-art performance of 67.08% on the MMAU test-mini benchmark. Ablation experiments show that on the base model we use: (i) SFT warm-up is important for stable RL training, (ii) structured chains yield more robust generalization than unstructured ones, and (iii) easy-to-hard curricula accelerate convergence and improve final performance. These findings demonstrate that explicit, structured reasoning and curriculum learning substantially enhances audio-language understanding.
Trans-Zero: Self-Play Incentivizes Large Language Models for Multilingual Translation Without Parallel Data
Apr 20, 2025The rise of Large Language Models (LLMs) has reshaped machine translation (MT), but multilingual MT still relies heavily on parallel data for supervised fine-tuning (SFT), facing challenges like data scarcity for low-resource languages and catastrophic forgetting. To address these issues, we propose TRANS-ZERO, a self-play framework that leverages only monolingual data and the intrinsic multilingual knowledge of LLM. TRANS-ZERO combines Genetic Monte-Carlo Tree Search (G-MCTS) with preference optimization, achieving strong translation performance that rivals supervised methods. Experiments demonstrate that this approach not only matches the performance of models trained on large-scale parallel data but also excels in non-English translation directions. Further analysis reveals that G-MCTS itself significantly enhances translation quality by exploring semantically consistent candidates through iterative translations, providing a robust foundation for the framework's succuss.
Aligned Better, Listen Better for Audio-Visual Large Language Models
Apr 02, 2025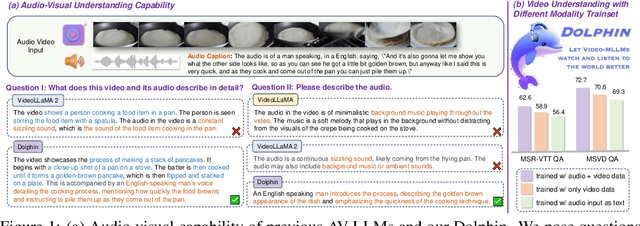

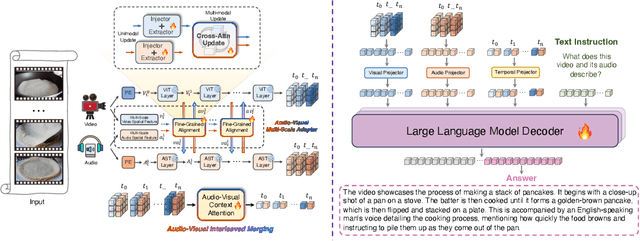
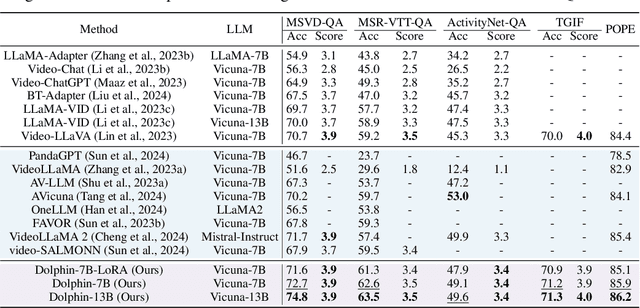
Audio is essential for multimodal video understanding. On the one hand, video inherently contains audio, which supplies complementary information to vision. Besides, video large language models (Video-LLMs) can encounter many audio-centric settings. However, existing Video-LLMs and Audio-Visual Large Language Models (AV-LLMs) exhibit deficiencies in exploiting audio information, leading to weak understanding and hallucinations. To solve the issues, we delve into the model architecture and dataset. (1) From the architectural perspective, we propose a fine-grained AV-LLM, namely Dolphin. The concurrent alignment of audio and visual modalities in both temporal and spatial dimensions ensures a comprehensive and accurate understanding of videos. Specifically, we devise an audio-visual multi-scale adapter for multi-scale information aggregation, which achieves spatial alignment. For temporal alignment, we propose audio-visual interleaved merging. (2) From the dataset perspective, we curate an audio-visual caption and instruction-tuning dataset, called AVU. It comprises 5.2 million diverse, open-ended data tuples (video, audio, question, answer) and introduces a novel data partitioning strategy. Extensive experiments show our model not only achieves remarkable performance in audio-visual understanding, but also mitigates potential hallucinations.
Monocular Depth Estimation and Segmentation for Transparent Object with Iterative Semantic and Geometric Fusion
Feb 20, 2025Transparent object perception is indispensable for numerous robotic tasks. However, accurately segmenting and estimating the depth of transparent objects remain challenging due to complex optical properties. Existing methods primarily delve into only one task using extra inputs or specialized sensors, neglecting the valuable interactions among tasks and the subsequent refinement process, leading to suboptimal and blurry predictions. To address these issues, we propose a monocular framework, which is the first to excel in both segmentation and depth estimation of transparent objects, with only a single-image input. Specifically, we devise a novel semantic and geometric fusion module, effectively integrating the multi-scale information between tasks. In addition, drawing inspiration from human perception of objects, we further incorporate an iterative strategy, which progressively refines initial features for clearer results. Experiments on two challenging synthetic and real-world datasets demonstrate that our model surpasses state-of-the-art monocular, stereo, and multi-view methods by a large margin of about 38.8%-46.2% with only a single RGB input. Codes and models are publicly available at https://github.com/L-J-Yuan/MODEST.
Extend Adversarial Policy Against Neural Machine Translation via Unknown Token
Jan 21, 2025
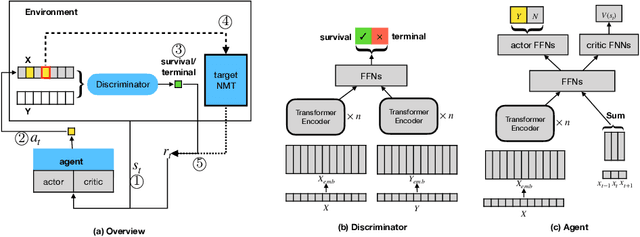

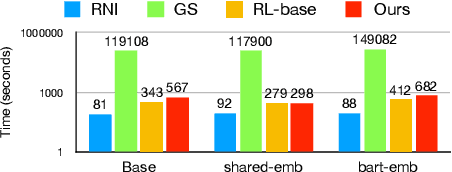
Generating adversarial examples contributes to mainstream neural machine translation~(NMT) robustness. However, popular adversarial policies are apt for fixed tokenization, hindering its efficacy for common character perturbations involving versatile tokenization. Based on existing adversarial generation via reinforcement learning~(RL), we propose the `DexChar policy' that introduces character perturbations for the existing mainstream adversarial policy based on token substitution. Furthermore, we improve the self-supervised matching that provides feedback in RL to cater to the semantic constraints required during training adversaries. Experiments show that our method is compatible with the scenario where baseline adversaries fail, and can generate high-efficiency adversarial examples for analysis and optimization of the system.
* accepted by CCMT 2024()
C3oT: Generating Shorter Chain-of-Thought without Compromising Effectiveness
Dec 16, 2024



Generating Chain-of-Thought (CoT) before deriving the answer can effectively improve the reasoning capabilities of large language models (LLMs) and significantly improve the accuracy of the generated answer. However, in most cases, the length of the generated CoT is much longer than the desired final answer, which results in additional decoding costs. Furthermore, existing research has discovered that shortening the reasoning steps in CoT, even while preserving the key information, diminishes LLMs' abilities. These phenomena make it difficult to use LLMs and CoT in many real-world applications that only require the final answer and are sensitive to latency, such as search and recommendation. To reduce the costs of model decoding and shorten the length of the generated CoT, this paper presents $\textbf{C}$onditioned $\textbf{C}$ompressed $\textbf{C}$hain-of-$\textbf{T}$hought (C3oT), a CoT compression framework that involves a compressor to compress an original longer CoT into a shorter CoT while maintaining key information and interpretability, a conditioned training method to train LLMs with both longer CoT and shorter CoT simultaneously to learn the corresponding relationships between them, and a conditioned inference method to gain the reasoning ability learned from longer CoT by generating shorter CoT. We conduct experiments over four datasets from arithmetic and commonsense scenarios, showing that the proposed method is capable of compressing the length of generated CoT by up to more than 50% without compromising its effectiveness.