 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligned Better, Listen Better for Audio-Visual Large Language Models
Apr 02, 2025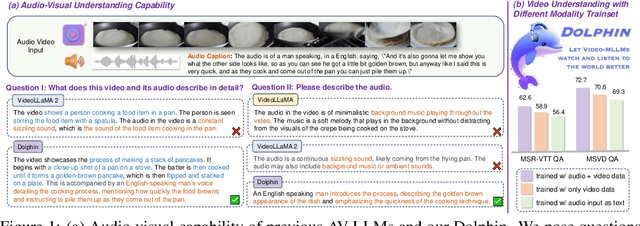

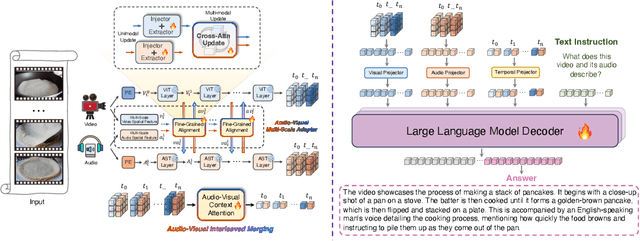
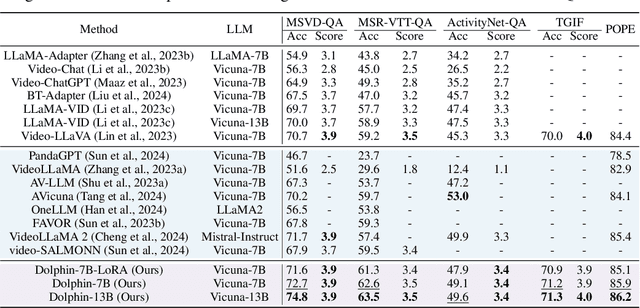
Audio is essential for multimodal video understanding. On the one hand, video inherently contains audio, which supplies complementary information to vision. Besides, video large language models (Video-LLMs) can encounter many audio-centric settings. However, existing Video-LLMs and Audio-Visual Large Language Models (AV-LLMs) exhibit deficiencies in exploiting audio information, leading to weak understanding and hallucinations. To solve the issues, we delve into the model architecture and dataset. (1) From the architectural perspective, we propose a fine-grained AV-LLM, namely Dolphin. The concurrent alignment of audio and visual modalities in both temporal and spatial dimensions ensures a comprehensive and accurate understanding of videos. Specifically, we devise an audio-visual multi-scale adapter for multi-scale information aggregation, which achieves spatial alignment. For temporal alignment, we propose audio-visual interleaved merging. (2) From the dataset perspective, we curate an audio-visual caption and instruction-tuning dataset, called AVU. It comprises 5.2 million diverse, open-ended data tuples (video, audio, question, answer) and introduces a novel data partitioning strategy. Extensive experiments show our model not only achieves remarkable performance in audio-visual understanding, but also mitigates potential hallucinations.
Wan: Open and Advanced Large-Scale Video Generative Models
Mar 26, 2025



This report presents Wan, a comprehensive and open suite of video foundation models designed to push the boundaries of video generation. Built upon the mainstream diffusion transformer paradigm, Wan achieves significant advancements in generative capabilities through a series of innovations, including our novel VAE, scalable pre-training strategies, large-scale data curation, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility. Specifically, Wan is characterized by four key features: Leading Performance: The 14B model of Wan, trained on a vast dataset comprising billions of images and videos, demonstrates the scaling laws of video generation with respect to both data and model size. It consistently outperforms the existing open-source models as well as state-of-the-art commercial solutions across multiple internal and external benchmarks, demonstrating a clear and significant performance superiority. Comprehensiveness: Wan offers two capable models, i.e., 1.3B and 14B parameters, for efficiency and effectiveness respectively. It also covers multiple downstream applications, including image-to-video, instruction-guided video editing, and personal video generation, encompassing up to eight tasks. Consumer-Grade Efficiency: The 1.3B model demonstrates exceptional resource efficiency, requiring only 8.19 GB VRAM, making it compatible with a wide range of consumer-grade GPUs. Openness: We open-source the entire series of Wan, including source code and all models, with the goal of fostering the growth of the video generation community. This openness seeks to significantly expand the creative possibilities of video production in the industry and provide academia with high-quality video foundation models. All the code and models are available at https://github.com/Wan-Video/Wan2.1.
UFO: A Unified Approach to Fine-grained Visual Perception via Open-ended Language Interface
Mar 04, 2025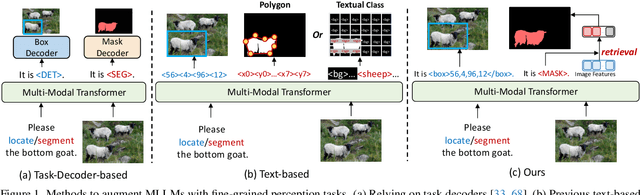
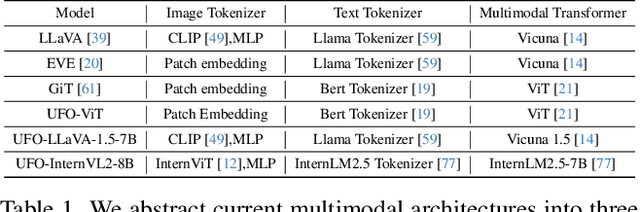
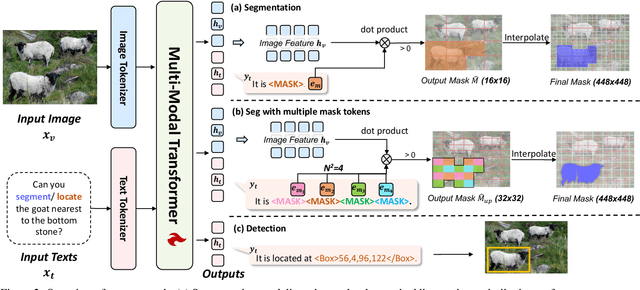
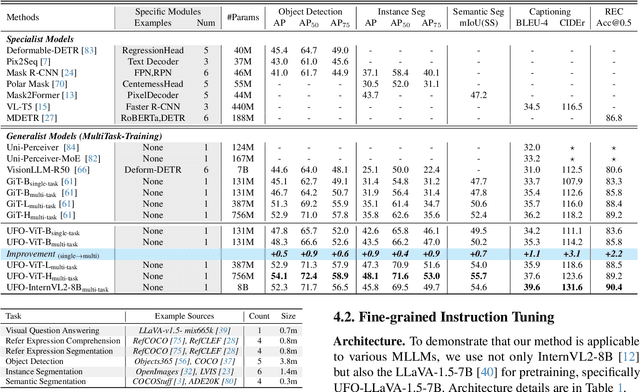
Generalist models have achieved remarkable success in both language and vision-language tasks, showcasing the potential of unified modeling. However, effectively integrating fine-grained perception tasks like detection and segmentation into these models remains a significant challenge. This is primarily because these tasks often rely heavily on task-specific designs and architectures that can complicate the modeling process. To address this challenge, we present \ours, a framework that \textbf{U}nifies \textbf{F}ine-grained visual perception tasks through an \textbf{O}pen-ended language interface. By transforming all perception targets into the language space, \ours unifies object-level detection, pixel-level segmentation, and image-level vision-language tasks into a single model. Additionally, we introduce a novel embedding retrieval approach that relies solely on the language interface to support segmentation tasks. Our framework bridges the gap between fine-grained perception and vision-language tasks, significantly simplifying architectural design and training strategies while achieving comparable or superior performance to methods with intricate task-specific designs. After multi-task training on five standard visual perception datasets, \ours outperforms the previous state-of-the-art generalist models by 12.3 mAP on COCO instance segmentation and 3.3 mIoU on ADE20K semantic segmentation. Furthermore, our method seamlessly integrates with existing MLLMs, effectively combining fine-grained perception capabilities with their advanced language abilities, thereby enabling more challenging tasks such as reasoning segmentation. Code and models are available at https://github.com/nnnth/UFO.