 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE-Image Technical Report
May 25, 2026We introduce ERNIE-Image, an open-source text-to-image generation model built upon an 8B single-stream DiT architecture. ERNIE-Image aims to bridge the gap between current open-source models and leading closed-source systems through more effective mining of large-scale pre-training data and improved supervision quality throughout training. During pre-training, we adopt a bottom-up data construction pipeline that combines fine-grained image categorization, rich caption annotation, aesthetic assessment, and hierarchical sampling. This strategy reduces data noise while preserving long-tail concepts and detailed real-world knowledge, providing a stronger foundation for complex generation tasks. In the post-training stage, we use a top-down data construction pipeline for high-demand scenarios, diversify prompt annotations to better match real user inputs, and apply a stabilized DPO strategy to align the model with human aesthetic preferences. We further train ERNIE-Image-Turbo for efficient 8-NFE generation and propose MT-DMD to mitigate capability drift during distillation. To make the model easier to use in practical scenarios, we equip it with a lightweight Prompt Enhancer that expands concise user intents into structured visual descriptions. In addition, we develop ERNIE-Image-Aes, an industrial-grade aesthetic model, together with ERNIE-Image-Aes-1K, a human-annotated benchmark for realistic aesthetic evaluation. Extensive qualitative and quantitative experiments show that ERNIE-Image achieves leading performance among open-source models and approaches top-tier commercial models in instruction following, text rendering, and aesthetic quality. We release the trained models and aesthetic resources to facilitate further academic research and technical progress in the AIGC community.
Aligned Better, Listen Better for Audio-Visual Large Language Models
Apr 02, 2025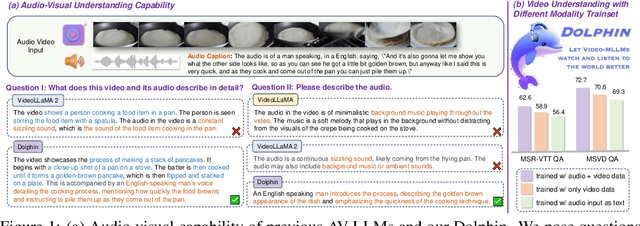

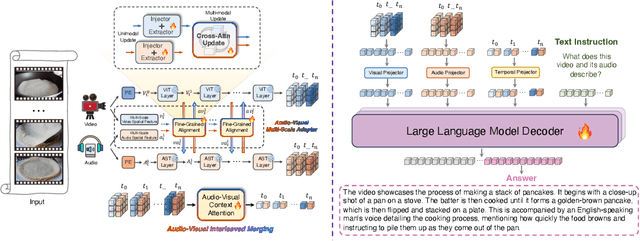
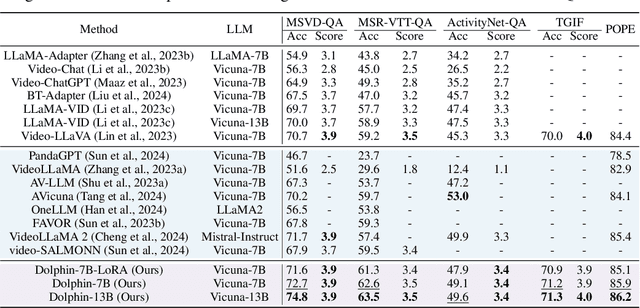
Audio is essential for multimodal video understanding. On the one hand, video inherently contains audio, which supplies complementary information to vision. Besides, video large language models (Video-LLMs) can encounter many audio-centric settings. However, existing Video-LLMs and Audio-Visual Large Language Models (AV-LLMs) exhibit deficiencies in exploiting audio information, leading to weak understanding and hallucinations. To solve the issues, we delve into the model architecture and dataset. (1) From the architectural perspective, we propose a fine-grained AV-LLM, namely Dolphin. The concurrent alignment of audio and visual modalities in both temporal and spatial dimensions ensures a comprehensive and accurate understanding of videos. Specifically, we devise an audio-visual multi-scale adapter for multi-scale information aggregation, which achieves spatial alignment. For temporal alignment, we propose audio-visual interleaved merging. (2) From the dataset perspective, we curate an audio-visual caption and instruction-tuning dataset, called AVU. It comprises 5.2 million diverse, open-ended data tuples (video, audio, question, answer) and introduces a novel data partitioning strategy. Extensive experiments show our model not only achieves remarkable performance in audio-visual understanding, but also mitigates potential hallucinations.
Wan: Open and Advanced Large-Scale Video Generative Models
Mar 26, 2025



This report presents Wan, a comprehensive and open suite of video foundation models designed to push the boundaries of video generation. Built upon the mainstream diffusion transformer paradigm, Wan achieves significant advancements in generative capabilities through a series of innovations, including our novel VAE, scalable pre-training strategies, large-scale data curation, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility. Specifically, Wan is characterized by four key features: Leading Performance: The 14B model of Wan, trained on a vast dataset comprising billions of images and videos, demonstrates the scaling laws of video generation with respect to both data and model size. It consistently outperforms the existing open-source models as well as state-of-the-art commercial solutions across multiple internal and external benchmarks, demonstrating a clear and significant performance superiority. Comprehensiveness: Wan offers two capable models, i.e., 1.3B and 14B parameters, for efficiency and effectiveness respectively. It also covers multiple downstream applications, including image-to-video, instruction-guided video editing, and personal video generation, encompassing up to eight tasks. Consumer-Grade Efficiency: The 1.3B model demonstrates exceptional resource efficiency, requiring only 8.19 GB VRAM, making it compatible with a wide range of consumer-grade GPUs. Openness: We open-source the entire series of Wan, including source code and all models, with the goal of fostering the growth of the video generation community. This openness seeks to significantly expand the creative possibilities of video production in the industry and provide academia with high-quality video foundation models. All the code and models are available at https://github.com/Wan-Video/Wan2.1.
CoReS: Orchestrating the Dance of Reasoning and Segmentation
Apr 08, 2024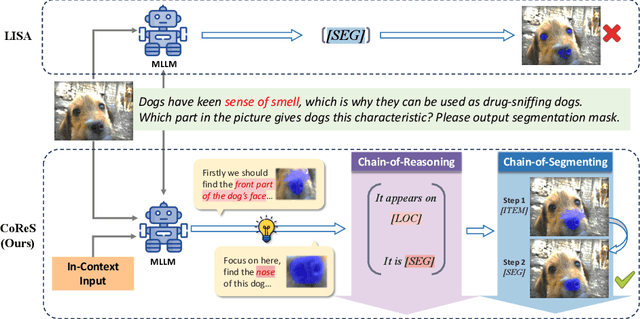
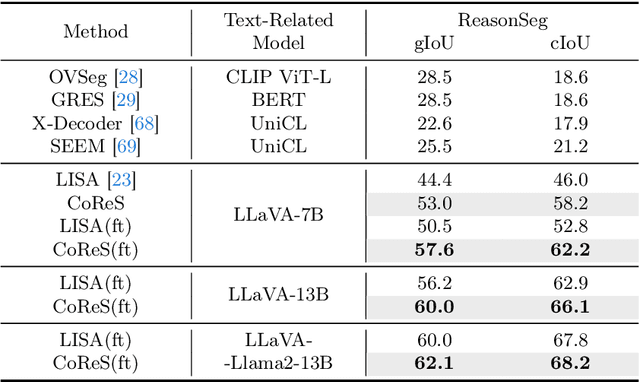
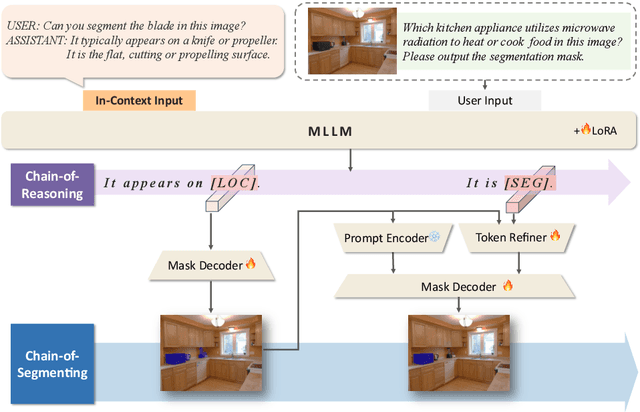
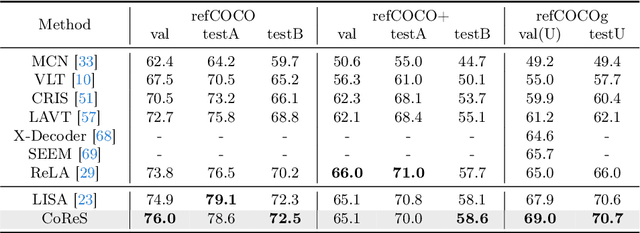
The reasoning segmentation task, which demands a nuanced comprehension of intricate queries to accurately pinpoint object regions, is attracting increasing attention. However, Multi-modal Large Language Models (MLLM) often find it difficult to accurately localize the objects described in complex reasoning contexts. We believe that the act of reasoning segmentation should mirror the cognitive stages of human visual search, where each step is a progressive refinement of thought toward the final object. Thus we introduce the Chains of Reasoning and Segmenting (CoReS) and find this top-down visual hierarchy indeed enhances the visual search process. Specifically, we propose a dual-chain structure that generates multi-modal, chain-like outputs to aid the segmentation process. Furthermore, to steer the MLLM's outputs into this intended hierarchy, we incorporate in-context inputs as guidance. Extensive experiments demonstrate the superior performance of our CoReS, which surpasses the state-of-the-art method by 7.1\% on the ReasonSeg dataset. The code will be released at https://github.com/baoxiaoyi/CoReS.
Dual Mean-Teacher: An Unbiased Semi-Supervised Framework for Audio-Visual Source Localization
Mar 05, 2024
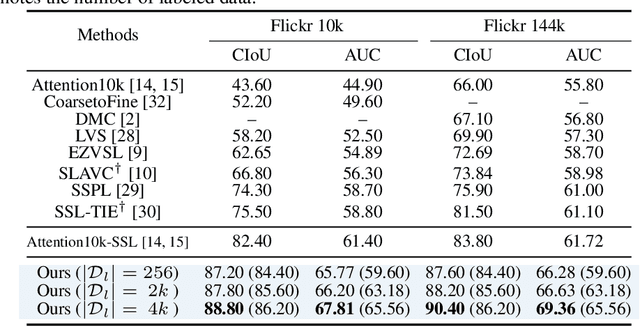
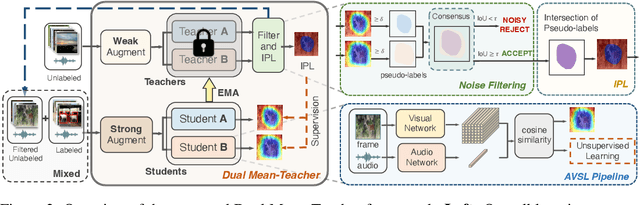
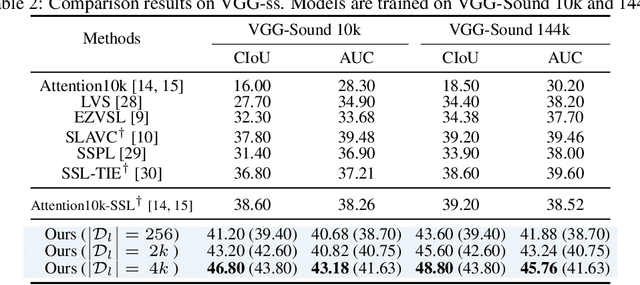
Audio-Visual Source Localization (AVSL) aims to locate sounding objects within video frames given the paired audio clips. Existing methods predominantly rely on self-supervised contrastive learning of audio-visual correspondence. Without any bounding-box annotations, they struggle to achieve precise localization, especially for small objects, and suffer from blurry boundaries and false positives. Moreover, the naive semi-supervised method is poor in fully leveraging the information of abundant unlabeled data. In this paper, we propose a novel semi-supervised learning framework for AVSL, namely Dual Mean-Teacher (DMT), comprising two teacher-student structures to circumvent the confirmation bias issue. Specifically, two teachers, pre-trained on limited labeled data, are employed to filter out noisy samples via the consensus between their predictions, and then generate high-quality pseudo-labels by intersecting their confidence maps. The sufficient utilization of both labeled and unlabeled data and the proposed unbiased framework enable DMT to outperform current state-of-the-art methods by a large margin, with CIoU of 90.4% and 48.8% on Flickr-SoundNet and VGG-Sound Source, obtaining 8.9%, 9.6% and 4.6%, 6.4% improvements over self- and semi-supervised methods respectively, given only 3% positional-annotations. We also extend our framework to some existing AVSL methods and consistently boost their performance.
Understanding the Multi-modal Prompts of the Pre-trained Vision-Language Model
Dec 18, 2023



Prompt learning has emerged as an efficient alternative for fine-tuning foundational models, such as CLIP, for various downstream tasks. However, there is no work that provides a comprehensive explanation for the working mechanism of the multi-modal prompts. In this paper, we conduct a direct analysis of the multi-modal prompts by asking the following questions: $(i)$ How do the learned multi-modal prompts improve the recognition performance? $(ii)$ What do the multi-modal prompts learn? To answer these questions, we begin by isolating the component of the formula where the prompt influences the calculation of self-attention at each layer in two distinct ways, \ie, $(1)$ introducing prompt embeddings makes the $[cls]$ token focus on foreground objects. $(2)$ the prompts learn a bias term during the update of token embeddings, allowing the model to adapt to the target domain. Subsequently, we conduct extensive visualization and statistical experiments on the eleven diverse downstream recognition datasets. From the experiments, we reveal that the learned prompts improve the performance mainly through the second way, which acts as the dataset bias to improve the recognition performance of the pre-trained model on the corresponding dataset. Based on this finding, we propose the bias tuning way and demonstrate that directly incorporating the learnable bias outperforms the learnable prompts in the same parameter settings. In datasets with limited category information, \ie, EuroSAT, bias tuning surpasses prompt tuning by a large margin. With a deeper understanding of the multi-modal prompt, we hope our work can inspire new and solid research in this direction.
Relevant Intrinsic Feature Enhancement Network for Few-Shot Semantic Segmentation
Dec 11, 2023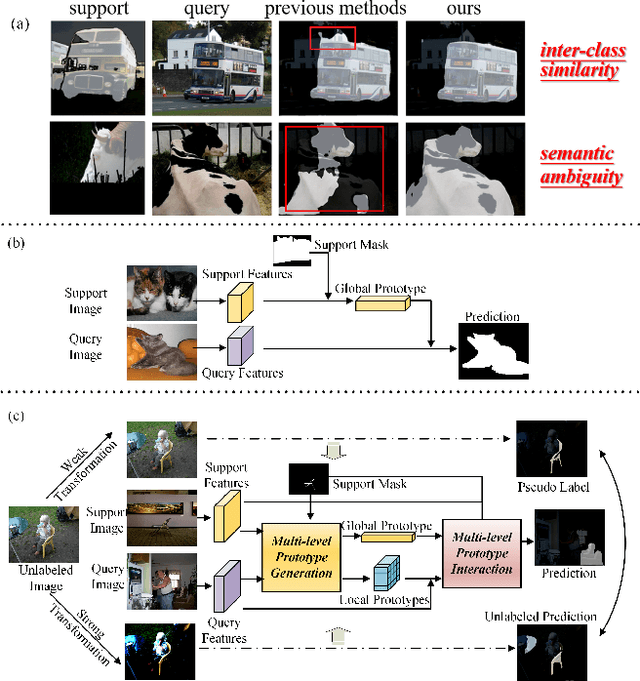
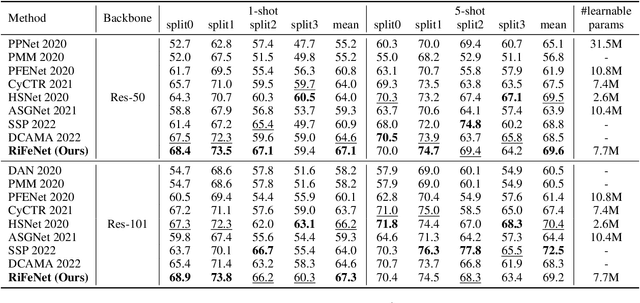
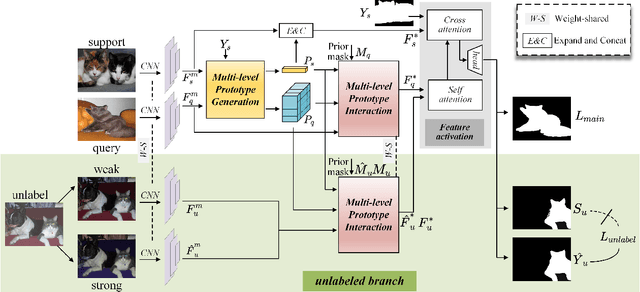
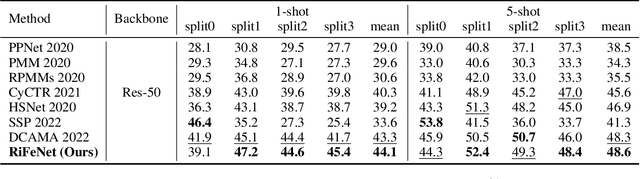
For few-shot semantic segmentation, the primary task is to extract class-specific intrinsic information from limited labeled data. However, the semantic ambiguity and inter-class similarity of previous methods limit the accuracy of pixel-level foreground-background classification. To alleviate these issues, we propose the Relevant Intrinsic Feature Enhancement Network (RiFeNet). To improve the semantic consistency of foreground instances, we propose an unlabeled branch as an efficient data utilization method, which teaches the model how to extract intrinsic features robust to intra-class differences. Notably, during testing, the proposed unlabeled branch is excluded without extra unlabeled data and computation. Furthermore, we extend the inter-class variability between foreground and background by proposing a novel multi-level prototype generation and interaction module. The different-grained complementarity between global and local prototypes allows for better distinction between similar categories. The qualitative and quantitative performance of RiFeNet surpasses the state-of-the-art methods on PASCAL-5i and COCO benchmarks.
Fashion Focus: Multi-modal Retrieval System for Video Commodity Localization in E-commerce
Feb 09, 2021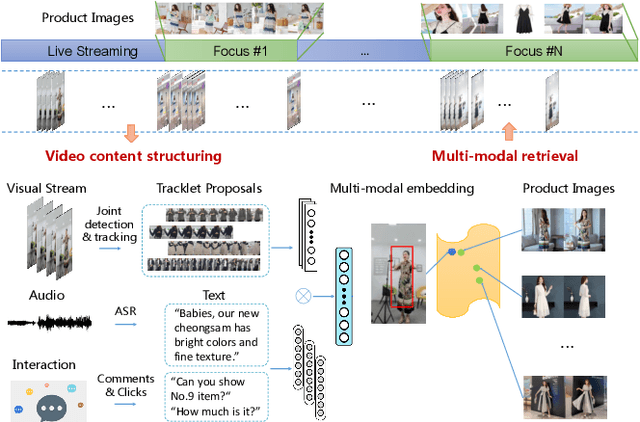

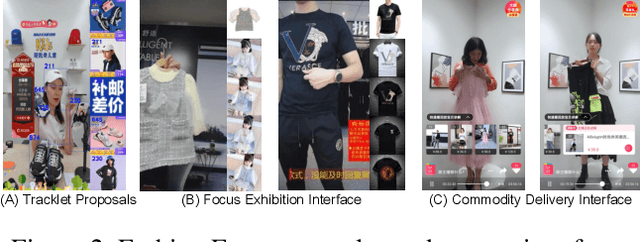
Nowadays, live-stream and short video shopping in E-commerce have grown exponentially. However, the sellers are required to manually match images of the selling products to the timestamp of exhibition in the untrimmed video, resulting in a complicated process. To solve the problem, we present an innovative demonstration of multi-modal retrieval system called "Fashion Focus", which enables to exactly localize the product images in the online video as the focuses. Different modality contributes to the community localization, including visual content, linguistic features and interaction context are jointly investigated via presented multi-modal learning. Our system employs two procedures for analysis, including video content structuring and multi-modal retrieval, to automatically achieve accurate video-to-shop matching. Fashion Focus presents a unified framework that can orientate the consumers towards relevant product exhibitions during watching videos and help the sellers to effectively deliver the products over search and recommendation.
The Field-of-View Constraint of Markers for Mobile Robot with Pan-Tilt Camera
Sep 24, 2019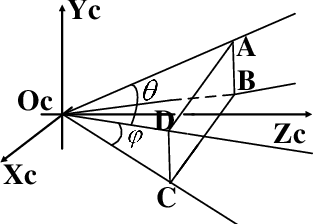
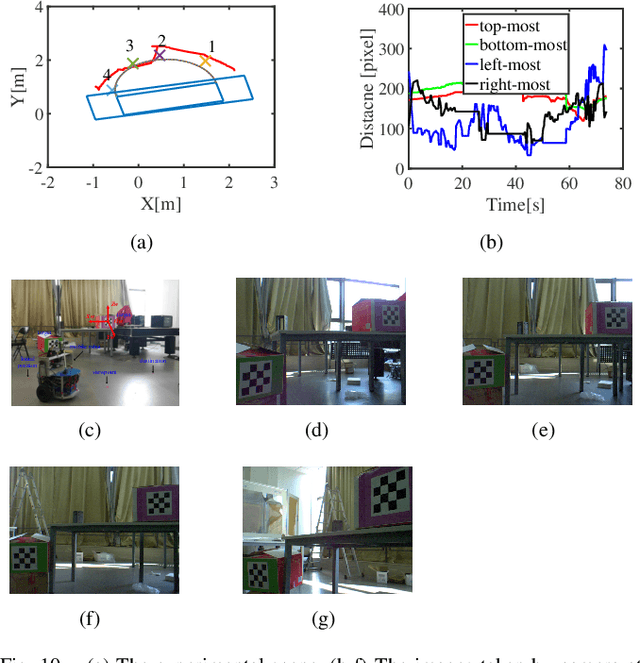
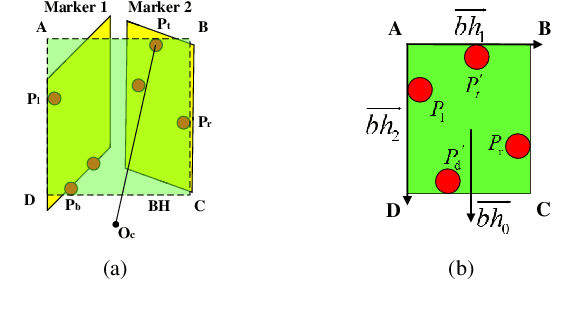
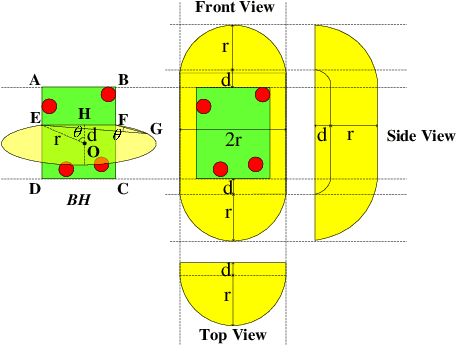
In the field of navigation and visual servo, it is common to calculate relative pose by feature points on markers, so keeping markers in camera's view is an important problem. In this paper, we propose a novel approach to calculate field-of-view (FOV) constraint of markers for camera. Our method can make the camera maintain the visibility of all feature points during the motion of mobile robot. According to the angular aperture of camera, the mobile robot can obtain the FOV constraint region where the camera cannot keep all feature points in an image. Based on the FOV constraint region, the mobile robot can be guided to move from the initial position to destination. Finally simulations and experiments are conducted based on a mobile robot equipped with a pan-tilt camera, which validates the effectiveness of the method to obtain the FOV constraints.
Multiple receptive fields and small-object-focusing weakly-supervised segmentation network for fast object detection
May 22, 2019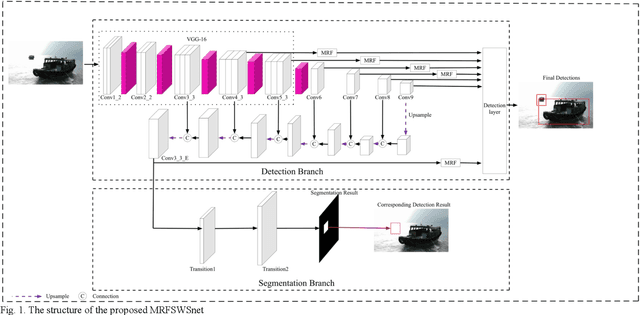
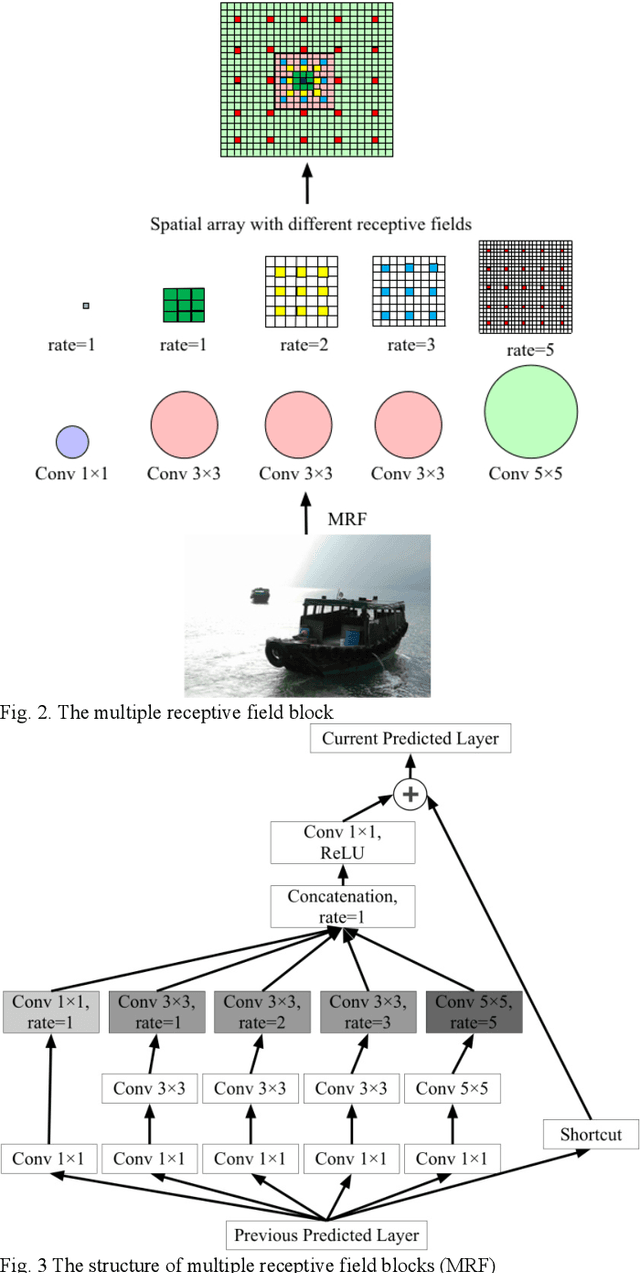
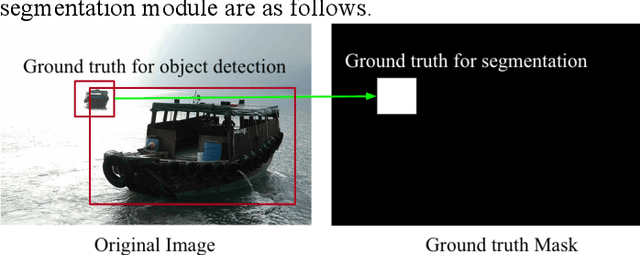

Object detection plays an important role in various visual applications. However, the precision and speed of detector are usually contradictory. One main reason for fast detectors' precision reduction is that small objects are hard to be detected. To address this problem, we propose a multiple receptive field and small-object-focusing weakly-supervised segmentation network (MRFSWSnet) to achieve fast object detection. In MRFSWSnet, multiple receptive fields block (MRF) is used to pay attention to the object and its adjacent background's different spatial location with different weights to enhance the feature's discriminability. In addition, in order to improve the accuracy of small object detection, a small-object-focusing weakly-supervised segmentation module which only focuses on small object instead of all objects is integrated into the detection network for auxiliary training to improve the precision of small object detection. Extensive experiments show the effectiveness of our method on both PASCAL VOC and MS COCO detection datasets. In particular, with a lower resolution version of 300x300, MRFSWSnet achieves 80.9% mAP on VOC2007 test with an inference speed of 15 milliseconds per frame, which is the state-of-the-art detector among real-time detectors.