 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Accurate Single-Image Depth Estimation on Mobile Devices, Mobile AI 2021 Challenge: Report
May 17, 2021


Depth estimation is an important computer vision problem with many practical applications to mobile devices. While many solutions have been proposed for this task, they are usually very computationally expensive and thus are not applicable for on-device inference. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based depth estimation solutions that can demonstrate a nearly real-time performance on smartphones and IoT platforms. For this, the participants were provided with a new large-scale dataset containing RGB-depth image pairs obtained with a dedicated stereo ZED camera producing high-resolution depth maps for objects located at up to 50 meters. The runtime of all models was evaluated on the popular Raspberry Pi 4 platform with a mobile ARM-based Broadcom chipset. The proposed solutions can generate VGA resolution depth maps at up to 10 FPS on the Raspberry Pi 4 while achieving high fidelity results, and are compatible with any Android or Linux-based mobile devices. A detailed description of all models developed in the challenge is provided in this paper.
The Field-of-View Constraint of Markers for Mobile Robot with Pan-Tilt Camera
Sep 24, 2019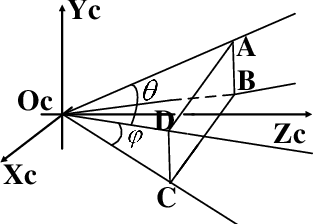
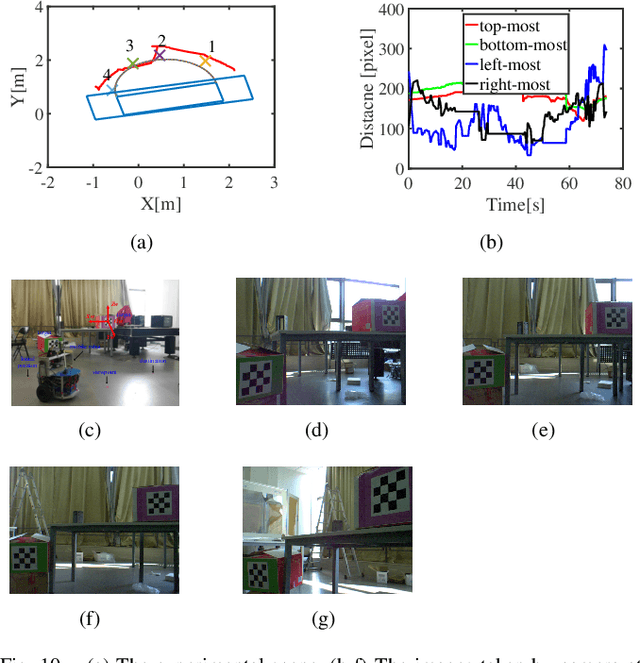
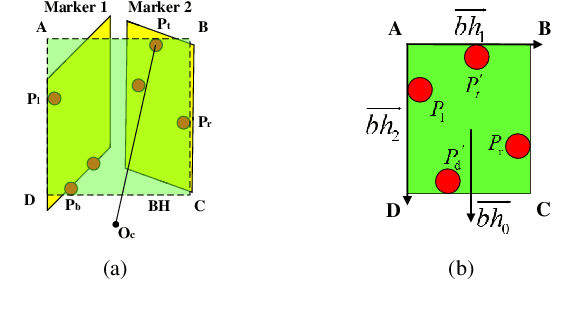
In the field of navigation and visual servo, it is common to calculate relative pose by feature points on markers, so keeping markers in camera's view is an important problem. In this paper, we propose a novel approach to calculate field-of-view (FOV) constraint of markers for camera. Our method can make the camera maintain the visibility of all feature points during the motion of mobile robot. According to the angular aperture of camera, the mobile robot can obtain the FOV constraint region where the camera cannot keep all feature points in an image. Based on the FOV constraint region, the mobile robot can be guided to move from the initial position to destination. Finally simulations and experiments are conducted based on a mobile robot equipped with a pan-tilt camera, which validates the effectiveness of the method to obtain the FOV constraints.
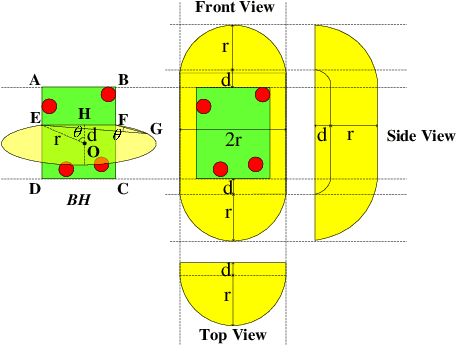
EPOSIT: An Absolute Pose Estimation Method for Pinhole and Fish-Eye Cameras
Sep 19, 2019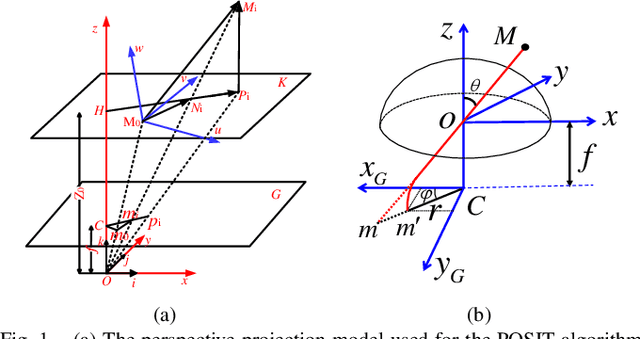
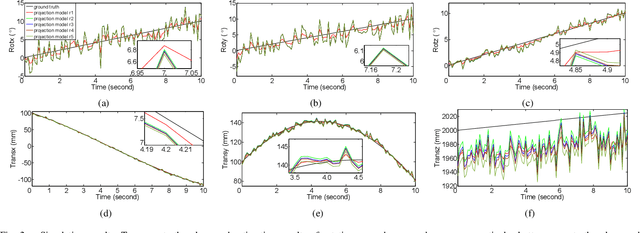
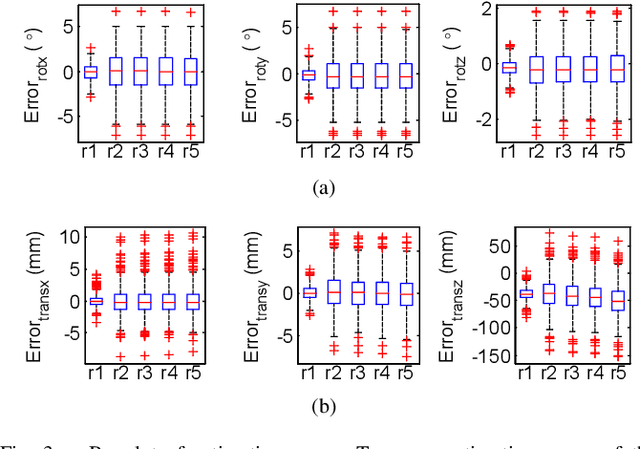
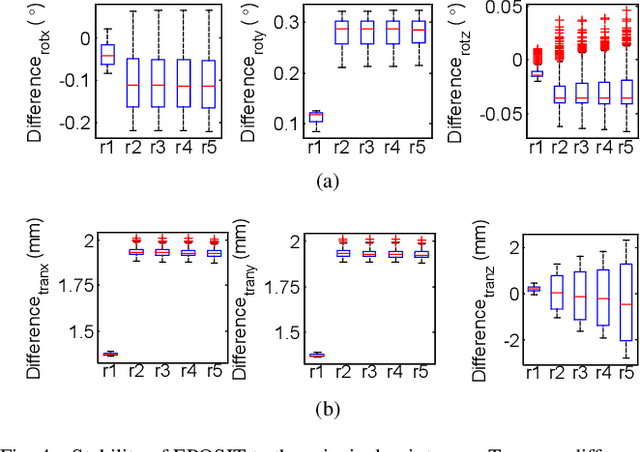
This paper presents a generic 6DOF camera pose estimation method, which can be used for both the pinhole camera and the fish-eye camera. Different from existing methods, relative positions of 3D points rather than absolute coordinates in the world coordinate system are employed in our method, and it has a unique solution. The application scope of POSIT (Pose from Orthography and Scaling with Iteration) algorithm is generalized to fish-eye cameras by combining with the radially symmetric projection model. The image point relationship between the pinhole camera and the fish-eye camera is derived based on their projection model. The general pose expression which fits for different cameras can be acquired by four noncoplanar object points and their corresponding image points. Accurate estimation results are calculated iteratively. Experimental results on synthetic and real data show that the pose estimation results of our method are more stable and accurate than state-of-the-art methods. The source code is available at https://github.com/k032131/EPOSIT.
Camera Pose Correction in SLAM Based on Bias Values of Map Points
Aug 24, 2019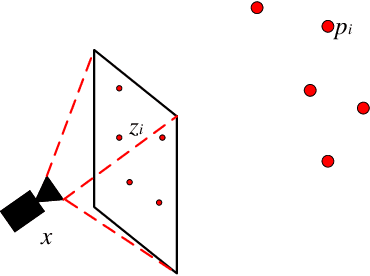
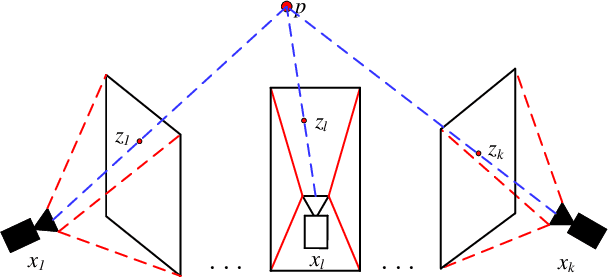
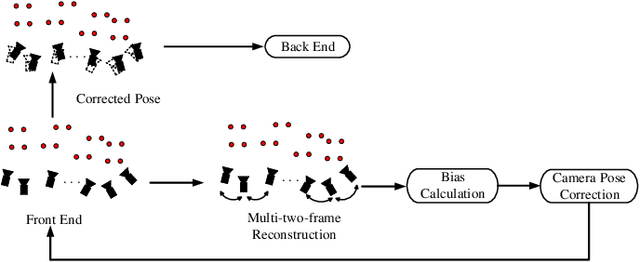
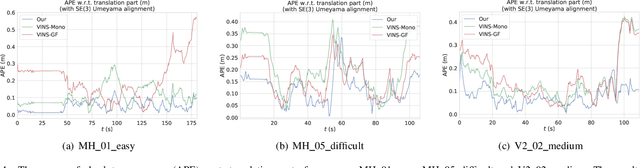
Accurate camera pose estimation result is essential for visual SLAM (VSLAM). This paper presents a novel pose correction method to improve the accuracy of the VSLAM system. Firstly, the relationship between the camera pose estimation error and bias values of map points is derived based on the optimized function in VSLAM. Secondly, the bias value of the map point is calculated by a statistical method. Finally, the camera pose estimation error is compensated according to the first derived relationship. After the pose correction, procedures of the original system, such as the bundle adjustment (BA) optimization, can be executed as before. Compared with existing methods, our algorithm is compact and effective and can be easily generalized to different VSLAM systems. Additionally, the robustness to system noise of our method is better than feature selection methods, due to all original system information is preserved in our algorithm while only a subset is employed in the latter. Experimental results on benchmark datasets show that our approach leads to considerable improvements over state-of-the-art algorithms for absolute pose estimation.