 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransform your Smartphone into a DSLR Camera: Learning the ISP in the Wild
Mar 22, 2022

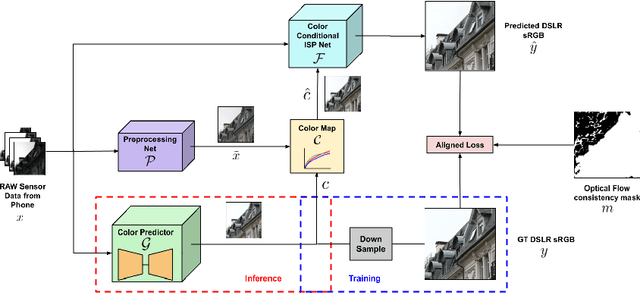

We propose a trainable Image Signal Processing (ISP) framework that produces DSLR quality images given RAW images captured by a smartphone. To address the color misalignments between training image pairs, we employ a color-conditional ISP network and optimize a novel parametric color mapping between each input RAW and reference DSLR image. During inference, we predict the target color image by designing a color prediction network with efficient Global Context Transformer modules. The latter effectively leverage global information to learn consistent color and tone mappings. We further propose a robust masked aligned loss to identify and discard regions with inaccurate motion estimation during training. Lastly, we introduce the ISP in the Wild (ISPW) dataset, consisting of weakly paired phone RAW and DSLR sRGB images. We extensively evaluate our method, setting a new state-of-the-art on two datasets.
Fast and Accurate Single-Image Depth Estimation on Mobile Devices, Mobile AI 2021 Challenge: Report
May 17, 2021


Depth estimation is an important computer vision problem with many practical applications to mobile devices. While many solutions have been proposed for this task, they are usually very computationally expensive and thus are not applicable for on-device inference. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based depth estimation solutions that can demonstrate a nearly real-time performance on smartphones and IoT platforms. For this, the participants were provided with a new large-scale dataset containing RGB-depth image pairs obtained with a dedicated stereo ZED camera producing high-resolution depth maps for objects located at up to 50 meters. The runtime of all models was evaluated on the popular Raspberry Pi 4 platform with a mobile ARM-based Broadcom chipset. The proposed solutions can generate VGA resolution depth maps at up to 10 FPS on the Raspberry Pi 4 while achieving high fidelity results, and are compatible with any Android or Linux-based mobile devices. A detailed description of all models developed in the challenge is provided in this paper.
Zero-Pair Image to Image Translation using Domain Conditional Normalization
Nov 11, 2020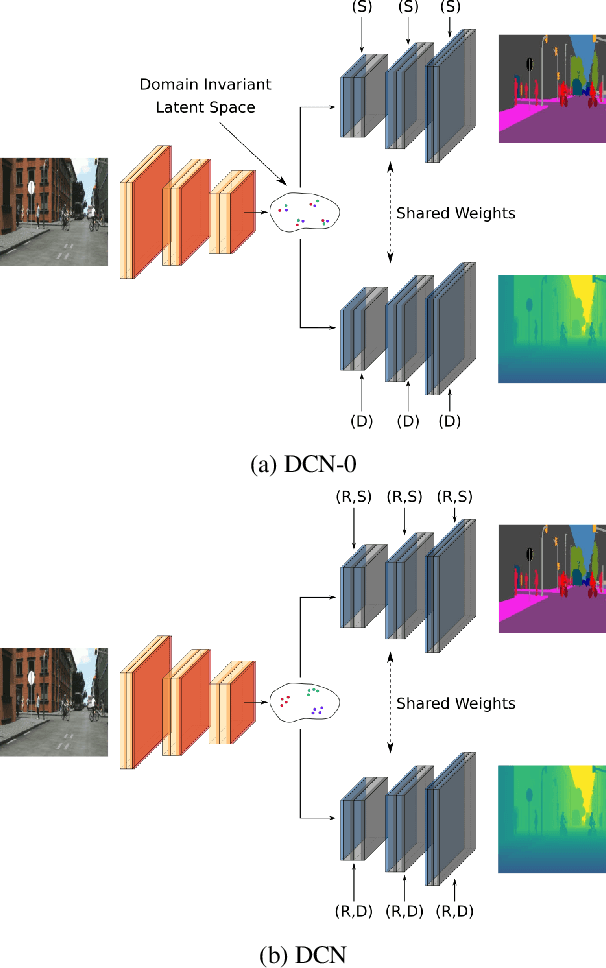
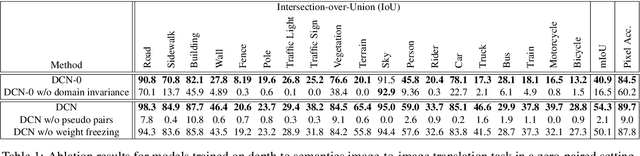
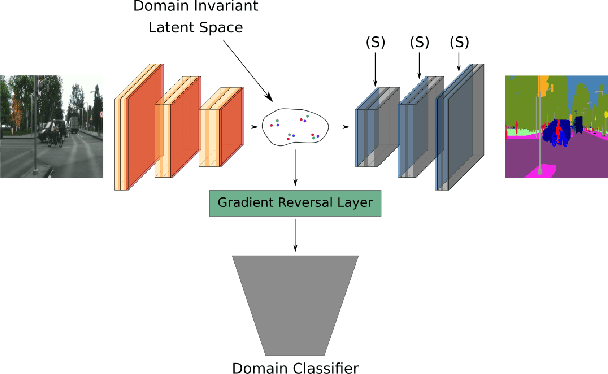

In this paper, we propose an approach based on domain conditional normalization (DCN) for zero-pair image-to-image translation, i.e., translating between two domains which have no paired training data available but each have paired training data with a third domain. We employ a single generator which has an encoder-decoder structure and analyze different implementations of domain conditional normalization to obtain the desired target domain output. The validation benchmark uses RGB-depth pairs and RGB-semantic pairs for training and compares performance for the depth-semantic translation task. The proposed approaches improve in qualitative and quantitative terms over the compared methods, while using much fewer parameters. Code available at https://github.com/samarthshukla/dcn
Extremely Weak Supervised Image-to-Image Translation for Semantic Segmentation
Sep 18, 2019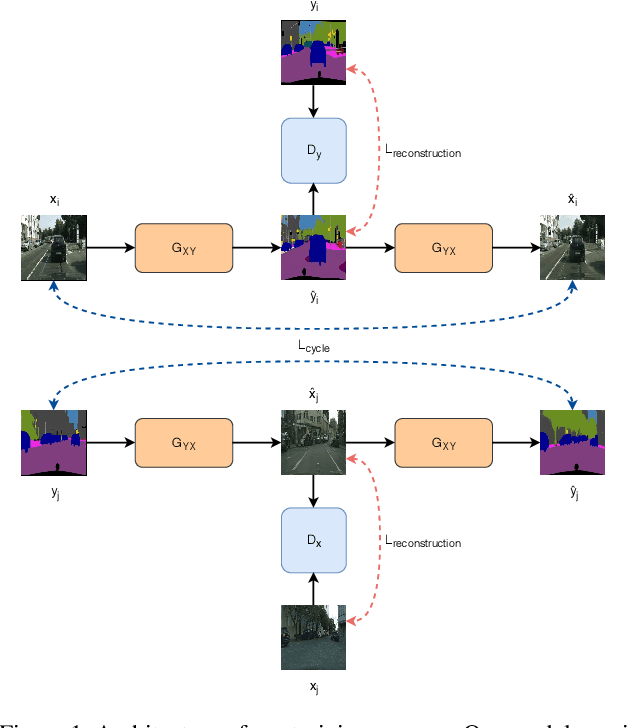
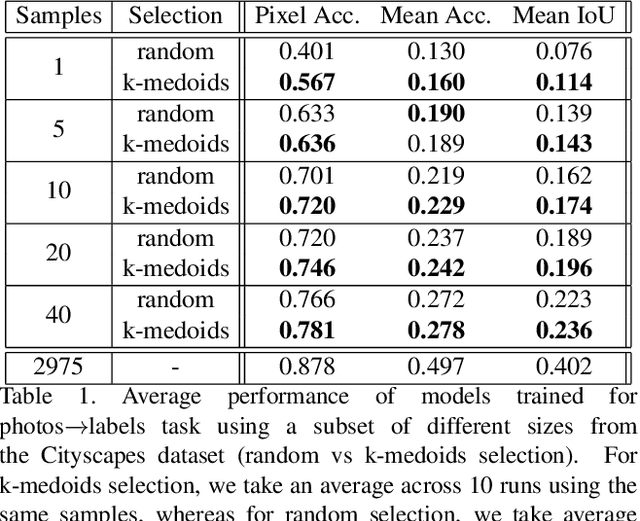
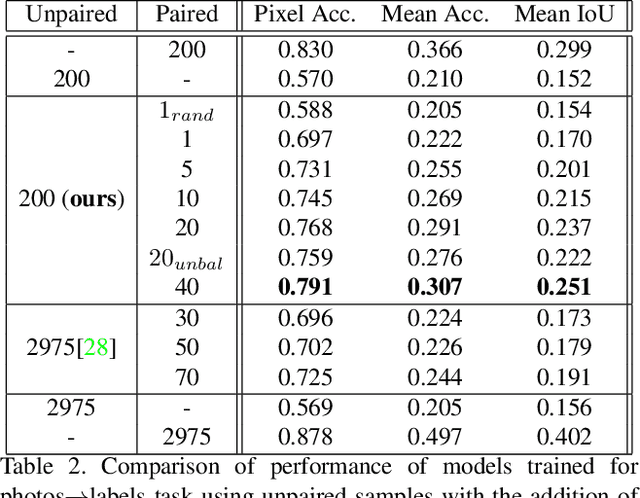

Recent advances in generative models and adversarial training have led to a flourishing image-to-image (I2I) translation literature. The current I2I translation approaches require training images from the two domains that are either all paired (supervised) or all unpaired (unsupervised). In practice, obtaining paired training data in sufficient quantities is often very costly and cumbersome. Therefore solutions that employ unpaired data, while less accurate, are largely preferred. In this paper, we aim to bridge the gap between supervised and unsupervised I2I translation, with application to semantic image segmentation. We build upon pix2pix and CycleGAN, state-of-the-art seminal I2I translation techniques. We propose a method to select (very few) paired training samples and achieve significant improvements in both supervised and unsupervised I2I translation settings over random selection. Further, we boost the performance by incorporating both (selected) paired and unpaired samples in the training process. Our experiments show that an extremely weak supervised I2I translation solution using only one paired training sample can achieve a quantitative performance much better than the unsupervised CycleGAN model, and comparable to that of the supervised pix2pix model trained on thousands of pairs.
Reinforced Imitation: Sample Efficient Deep Reinforcement Learning for Map-less Navigation by Leveraging Prior Demonstrations
Aug 31, 2018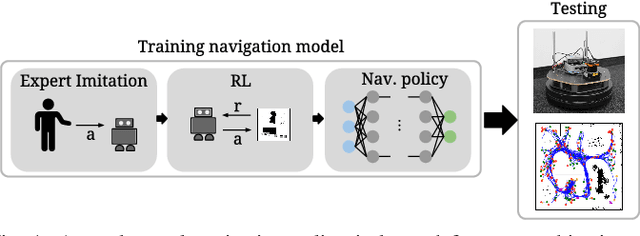
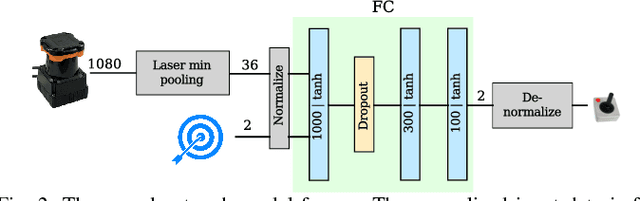
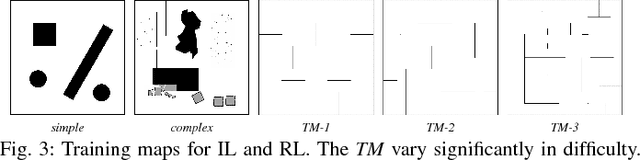
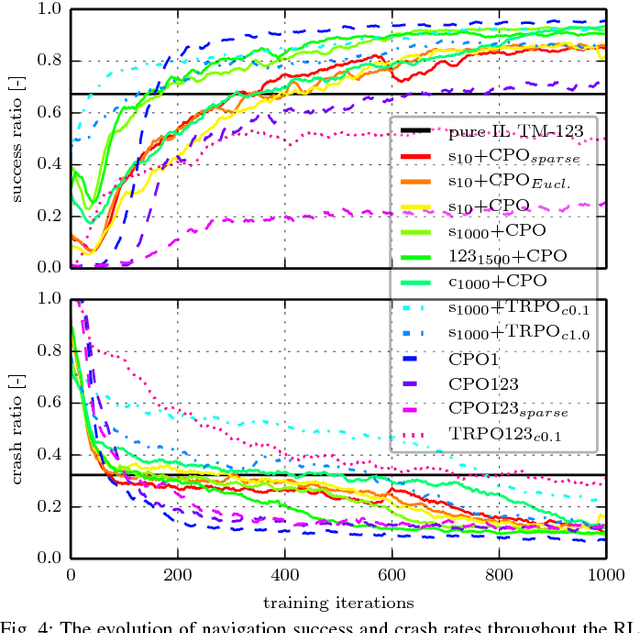
This work presents a case study of a learning-based approach for target driven map-less navigation. The underlying navigation model is an end-to-end neural network which is trained using a combination of expert demonstrations, imitation learning (IL) and reinforcement learning (RL). While RL and IL suffer from a large sample complexity and the distribution mismatch problem, respectively, we show that leveraging prior expert demonstrations for pre-training can reduce the training time to reach at least the same level of performance compared to plain RL by a factor of 5. We present a thorough evaluation of different combinations of expert demonstrations, different RL algorithms and reward functions, both in simulation and on a real robotic platform. Our results show that the final model outperforms both standalone approaches in the amount of successful navigation tasks. In addition, the RL reward function can be significantly simplified when using pre-training, e.g. by using a sparse reward only. The learned navigation policy is able to generalize to unseen and real-world environments.