 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforced Imitation: Sample Efficient Deep Reinforcement Learning for Map-less Navigation by Leveraging Prior Demonstrations
Paper and Code
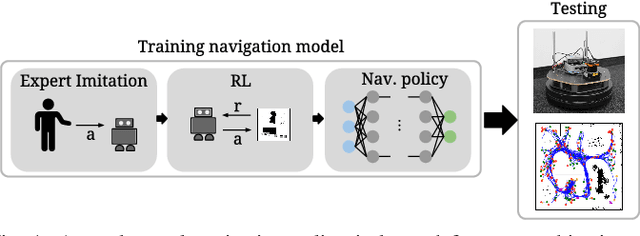
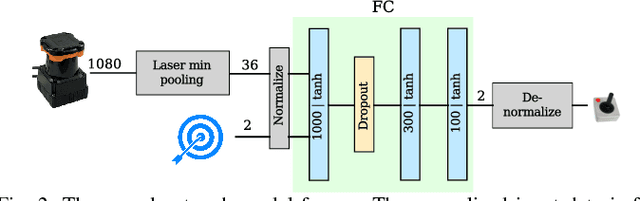
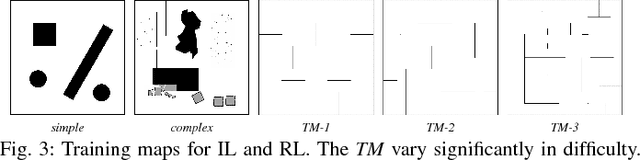
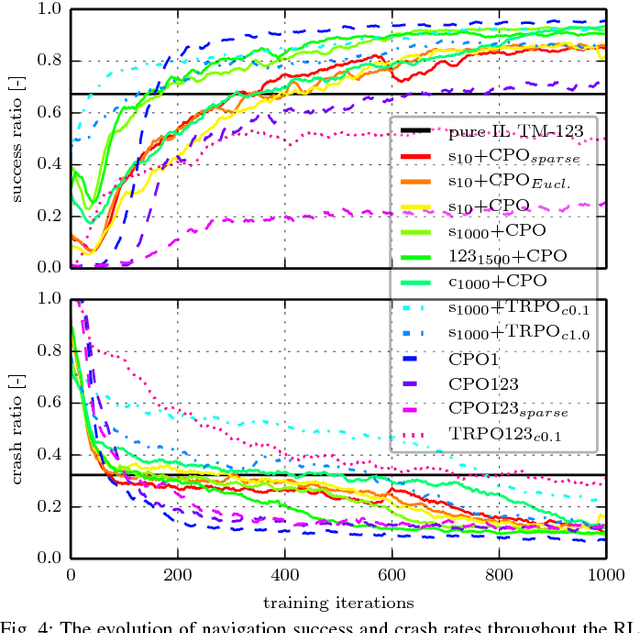
This work presents a case study of a learning-based approach for target driven map-less navigation. The underlying navigation model is an end-to-end neural network which is trained using a combination of expert demonstrations, imitation learning (IL) and reinforcement learning (RL). While RL and IL suffer from a large sample complexity and the distribution mismatch problem, respectively, we show that leveraging prior expert demonstrations for pre-training can reduce the training time to reach at least the same level of performance compared to plain RL by a factor of 5. We present a thorough evaluation of different combinations of expert demonstrations, different RL algorithms and reward functions, both in simulation and on a real robotic platform. Our results show that the final model outperforms both standalone approaches in the amount of successful navigation tasks. In addition, the RL reward function can be significantly simplified when using pre-training, e.g. by using a sparse reward only. The learned navigation policy is able to generalize to unseen and real-world environments.