 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Light-Weight Framework for Open-Set Object Detection with Decoupled Feature Alignment in Joint Space
Dec 19, 2024



Open-set object detection (OSOD) is highly desirable for robotic manipulation in unstructured environments. However, existing OSOD methods often fail to meet the requirements of robotic applications due to their high computational burden and complex deployment. To address this issue, this paper proposes a light-weight framework called Decoupled OSOD (DOSOD), which is a practical and highly efficient solution to support real-time OSOD tasks in robotic systems. Specifically, DOSOD builds upon the YOLO-World pipeline by integrating a vision-language model (VLM) with a detector. A Multilayer Perceptron (MLP) adaptor is developed to transform text embeddings extracted by the VLM into a joint space, within which the detector learns the region representations of class-agnostic proposals. Cross-modality features are directly aligned in the joint space, avoiding the complex feature interactions and thereby improving computational efficiency. DOSOD operates like a traditional closed-set detector during the testing phase, effectively bridging the gap between closed-set and open-set detection. Compared to the baseline YOLO-World, the proposed DOSOD significantly enhances real-time performance while maintaining comparable accuracy. The slight DOSOD-S model achieves a Fixed AP of $26.7\%$, compared to $26.2\%$ for YOLO-World-v1-S and $22.7\%$ for YOLO-World-v2-S, using similar backbones on the LVIS minival dataset. Meanwhile, the FPS of DOSOD-S is $57.1\%$ higher than YOLO-World-v1-S and $29.6\%$ higher than YOLO-World-v2-S. Meanwhile, we demonstrate that the DOSOD model facilitates the deployment of edge devices. The codes and models are publicly available at https://github.com/D-Robotics-AI-Lab/DOSOD.
Cross Pseudo-Labeling for Semi-Supervised Audio-Visual Source Localization
Mar 05, 2024Audio-Visual Source Localization (AVSL) is the task of identifying specific sounding objects in the scene given audio cues. In our work, we focus on semi-supervised AVSL with pseudo-labeling. To address the issues with vanilla hard pseudo-labels including bias accumulation, noise sensitivity, and instability, we propose a novel method named Cross Pseudo-Labeling (XPL), wherein two models learn from each other with the cross-refine mechanism to avoid bias accumulation. We equip XPL with two effective components. Firstly, the soft pseudo-labels with sharpening and pseudo-label exponential moving average mechanisms enable models to achieve gradual self-improvement and ensure stable training. Secondly, the curriculum data selection module adaptively selects pseudo-labels with high quality during training to mitigate potential bias. Experimental results demonstrate that XPL significantly outperforms existing methods, achieving state-of-the-art performance while effectively mitigating confirmation bias and ensuring training stability.
Dual Mean-Teacher: An Unbiased Semi-Supervised Framework for Audio-Visual Source Localization
Mar 05, 2024Audio-Visual Source Localization (AVSL) aims to locate sounding objects within video frames given the paired audio clips. Existing methods predominantly rely on self-supervised contrastive learning of audio-visual correspondence. Without any bounding-box annotations, they struggle to achieve precise localization, especially for small objects, and suffer from blurry boundaries and false positives. Moreover, the naive semi-supervised method is poor in fully leveraging the information of abundant unlabeled data. In this paper, we propose a novel semi-supervised learning framework for AVSL, namely Dual Mean-Teacher (DMT), comprising two teacher-student structures to circumvent the confirmation bias issue. Specifically, two teachers, pre-trained on limited labeled data, are employed to filter out noisy samples via the consensus between their predictions, and then generate high-quality pseudo-labels by intersecting their confidence maps. The sufficient utilization of both labeled and unlabeled data and the proposed unbiased framework enable DMT to outperform current state-of-the-art methods by a large margin, with CIoU of 90.4% and 48.8% on Flickr-SoundNet and VGG-Sound Source, obtaining 8.9%, 9.6% and 4.6%, 6.4% improvements over self- and semi-supervised methods respectively, given only 3% positional-annotations. We also extend our framework to some existing AVSL methods and consistently boost their performance.
DSLA: Dynamic smooth label assignment for efficient anchor-free object detection
Aug 01, 2022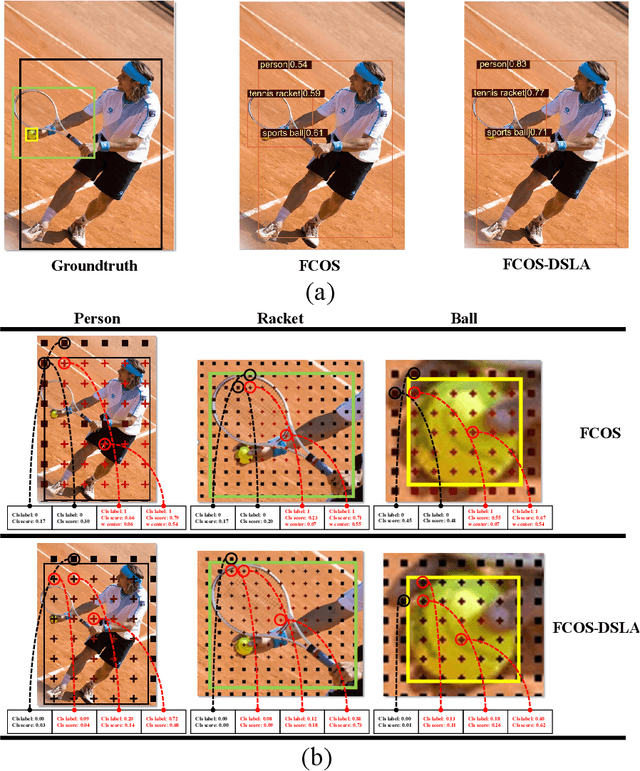
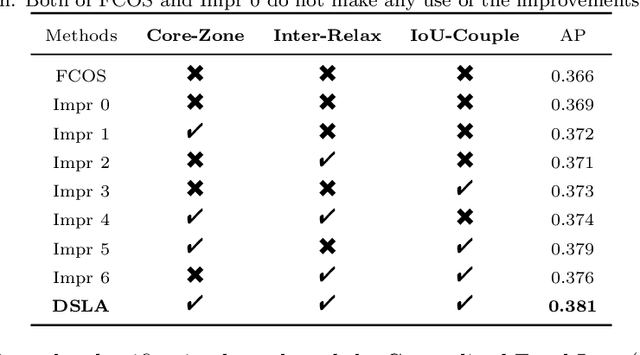


Anchor-free detectors basically formulate object detection as dense classification and regression. For popular anchor-free detectors, it is common to introduce an individual prediction branch to estimate the quality of localization. The following inconsistencies are observed when we delve into the practices of classification and quality estimation. Firstly, for some adjacent samples which are assigned completely different labels, the trained model would produce similar classification scores. This violates the training objective and leads to performance degradation. Secondly, it is found that detected bounding boxes with higher confidences contrarily have smaller overlaps with the corresponding ground-truth. Accurately localized bounding boxes would be suppressed by less accurate ones in the Non-Maximum Suppression (NMS) procedure. To address the inconsistency problems, the Dynamic Smooth Label Assignment (DSLA) method is proposed. Based on the concept of centerness originally developed in FCOS, a smooth assignment strategy is proposed. The label is smoothed to a continuous value in [0, 1] to make a steady transition between positive and negative samples. Intersection-of-Union (IoU) is predicted dynamically during training and is coupled with the smoothed label. The dynamic smooth label is assigned to supervise the classification branch. Under such supervision, quality estimation branch is naturally merged into the classification branch, which simplifies the architecture of anchor-free detector. Comprehensive experiments are conducted on the MS COCO benchmark. It is demonstrated that, DSLA can significantly boost the detection accuracy by alleviating the above inconsistencies for anchor-free detectors. Our codes are released at https://github.com/YonghaoHe/DSLA.
FastPose: Towards Real-time Pose Estimation and Tracking via Scale-normalized Multi-task Networks
Aug 15, 2019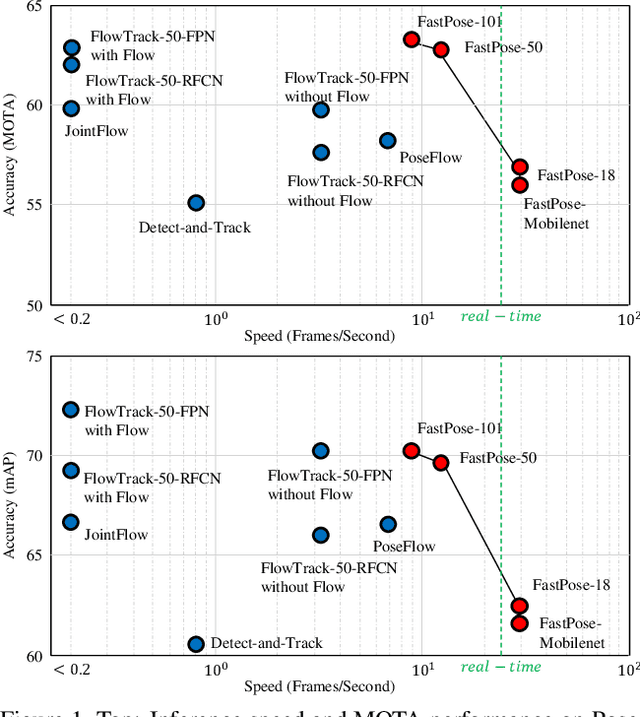

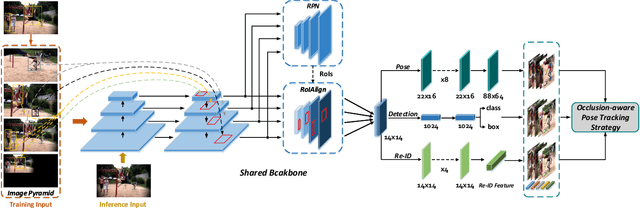
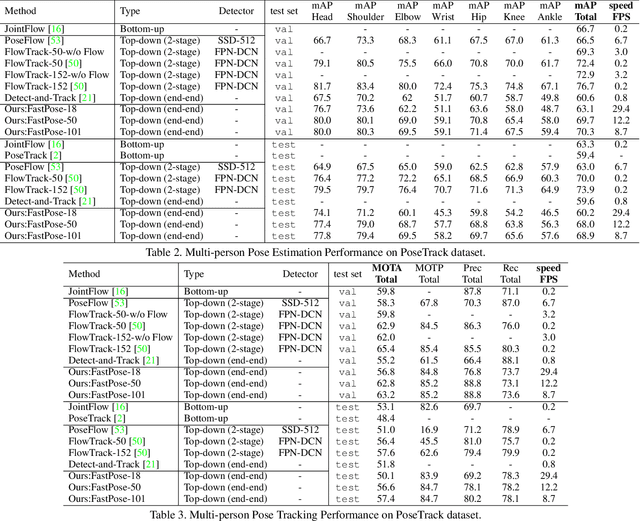
Both accuracy and efficiency are significant for pose estimation and tracking in videos. State-of-the-art performance is dominated by two-stages top-down methods. Despite the leading results, these methods are impractical for real-world applications due to their separated architectures and complicated calculation. This paper addresses the task of articulated multi-person pose estimation and tracking towards real-time speed. An end-to-end multi-task network (MTN) is designed to perform human detection, pose estimation, and person re-identification (Re-ID) tasks simultaneously. To alleviate the performance bottleneck caused by scale variation problem, a paradigm which exploits scale-normalized image and feature pyramids (SIFP) is proposed to boost both performance and speed. Given the results of MTN, we adopt an occlusion-aware Re-ID feature strategy in the pose tracking module, where pose information is utilized to infer the occlusion state to make better use of Re-ID feature. In experiments, we demonstrate that the pose estimation and tracking performance improves steadily utilizing SIFP through different backbones. Using ResNet-18 and ResNet-50 as backbones, the overall pose tracking framework achieves competitive performance with 29.4 FPS and 12.2 FPS, respectively. Additionally, occlusion-aware Re-ID feature decreases the identification switches by 37% in the pose tracking process.