 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Generation Orders for Masked Discrete Diffusion Models via Variational Inference
Feb 27, 2026Masked discrete diffusion models (MDMs) are a promising new approach to generative modelling, offering the ability for parallel token generation and therefore greater efficiency than autoregressive counterparts. However, achieving an optimal balance between parallel generation and sample quality remains an open problem. Current approaches primarily address this issue through fixed, heuristic parallel sampling methods. There exist some recent learning based approaches to this problem, but its formulation from the perspective of variational inference remains underexplored. In this work, we propose a variational inference framework for learning parallel generation orders for MDMs. As part of our method, we propose a parameterisation for the approximate posterior of generation orders which facilitates parallelism and efficient sampling during training. Using this method, we conduct preliminary experiments on the GSM8K dataset, where our method performs competitively against heuristic sampling strategies in the regime of highly parallel generation. For example, our method achieves 33.1\% accuracy with an average of only only 4 generation steps, compared to 23.7-29.0\% accuracy achieved by standard competitor methods in the same number of steps. We believe further experiments and analysis of the method will yield valuable insights into the problem of parallel generation with MDMs.
GLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
Minimum Distance Summaries for Robust Neural Posterior Estimation
Feb 09, 2026Simulation-based inference (SBI) enables amortized Bayesian inference by first training a neural posterior estimator (NPE) on prior-simulator pairs, typically through low-dimensional summary statistics, which can then be cheaply reused for fast inference by querying it on new test observations. Because NPE is estimated under the training data distribution, it is susceptible to misspecification when observations deviate from the training distribution. Many robust SBI approaches address this by modifying NPE training or introducing error models, coupling robustness to the inference network and compromising amortization and modularity. We introduce minimum-distance summaries, a plug-in robust NPE method that adapts queried test-time summaries independently of the pretrained NPE. Leveraging the maximum mean discrepancy (MMD) as a distance between observed data and a summary-conditional predictive distribution, the adapted summary inherits strong robustness properties from the MMD. We demonstrate that the algorithm can be implemented efficiently with random Fourier feature approximations, yielding a lightweight, model-free test-time adaptation procedure. We provide theoretical guarantees for the robustness of our algorithm and empirically evaluate it on a range of synthetic and real-world tasks, demonstrating substantial robustness gains with minimal additional overhead.
Missing At Random as Covariate Shift: Correcting Bias in Iterative Imputation
Feb 06, 2026Accurate imputation of missing data is critical to downstream machine learning performance. We formulate missing data imputation as a risk minimisation problem, which highlights a covariate shift between the observed and unobserved data distributions. This covariate shift induced bias is not accounted for by popular imputation methods and leads to suboptimal performance. In this paper, we derive theoretically valid importance weights that correct for the induced distributional bias. Furthermore, we propose a novel imputation algorithm that jointly estimates both the importance weights and imputation models, enabling bias correction throughout the imputation process. Empirical results across benchmark datasets show reductions in root mean squared error and Wasserstein distance of up to 7% and 20%, respectively, compared to otherwise identical unweighted methods.
Zero-Flow Encoders
Jan 31, 2026Flow-based methods have achieved significant success in various generative modeling tasks, capturing nuanced details within complex data distributions. However, few existing works have exploited this unique capability to resolve fine-grained structural details beyond generation tasks. This paper presents a flow-inspired framework for representation learning. First, we demonstrate that a rectified flow trained using independent coupling is zero everywhere at $t=0.5$ if and only if the source and target distributions are identical. We term this property the \emph{zero-flow criterion}. Second, we show that this criterion can certify conditional independence, thereby extracting \emph{sufficient information} from the data. Third, we translate this criterion into a tractable, simulation-free loss function that enables learning amortized Markov blankets in graphical models and latent representations in self-supervised learning tasks. Experiments on both simulated and real-world datasets demonstrate the effectiveness of our approach. The code reproducing our experiments can be found at: https://github.com/probabilityFLOW/zfe.
Direct Doubly Robust Estimation of Conditional Quantile Contrasts
Jan 27, 2026Within heterogeneous treatment effect (HTE) analysis, various estimands have been proposed to capture the effect of a treatment conditional on covariates. Recently, the conditional quantile comparator (CQC) has emerged as a promising estimand, offering quantile-level summaries akin to the conditional quantile treatment effect (CQTE) while preserving some interpretability of the conditional average treatment effect (CATE). It achieves this by summarising the treated response conditional on both the covariates and the untreated response. Despite these desirable properties, the CQC's current estimation is limited by the need to first estimate the difference in conditional cumulative distribution functions and then invert it. This inversion obscures the CQC estimate, hampering our ability to both model and interpret it. To address this, we propose the first direct estimator of the CQC, allowing for explicit modelling and parameterisation. This explicit parameterisation enables better interpretation of our estimate while also providing a means to constrain and inform the model. We show, both theoretically and empirically, that our estimation error depends directly on the complexity of the CQC itself, improving upon the existing estimation procedure. Furthermore, it retains the desirable double robustness property with respect to nuisance parameter estimation. We further show our method to outperform existing procedures in estimation accuracy across multiple data scenarios while varying sample size and nuisance error. Finally, we apply it to real-world data from an employment scheme, uncovering a reduced range of potential earnings improvement as participant age increases.
FastUMI-100K: Advancing Data-driven Robotic Manipulation with a Large-scale UMI-style Dataset
Oct 09, 2025Data-driven robotic manipulation learning depends on large-scale, high-quality expert demonstration datasets. However, existing datasets, which primarily rely on human teleoperated robot collection, are limited in terms of scalability, trajectory smoothness, and applicability across different robotic embodiments in real-world environments. In this paper, we present FastUMI-100K, a large-scale UMI-style multimodal demonstration dataset, designed to overcome these limitations and meet the growing complexity of real-world manipulation tasks. Collected by FastUMI, a novel robotic system featuring a modular, hardware-decoupled mechanical design and an integrated lightweight tracking system, FastUMI-100K offers a more scalable, flexible, and adaptable solution to fulfill the diverse requirements of real-world robot demonstration data. Specifically, FastUMI-100K contains over 100K+ demonstration trajectories collected across representative household environments, covering 54 tasks and hundreds of object types. Our dataset integrates multimodal streams, including end-effector states, multi-view wrist-mounted fisheye images and textual annotations. Each trajectory has a length ranging from 120 to 500 frames. Experimental results demonstrate that FastUMI-100K enables high policy success rates across various baseline algorithms, confirming its robustness, adaptability, and real-world applicability for solving complex, dynamic manipulation challenges. The source code and dataset will be released in this link https://github.com/MrKeee/FastUMI-100K.
Direct Fisher Score Estimation for Likelihood Maximization
Jun 06, 2025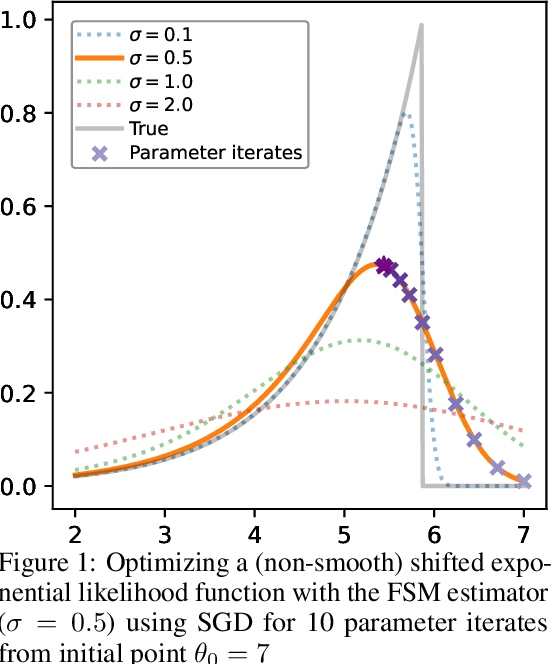
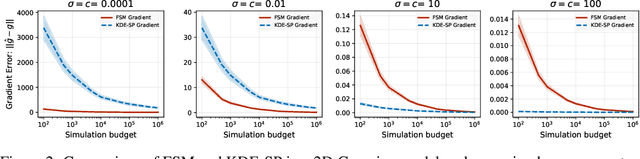
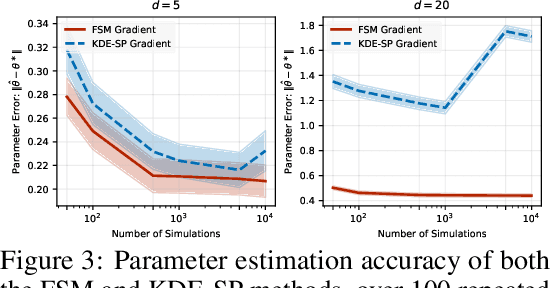
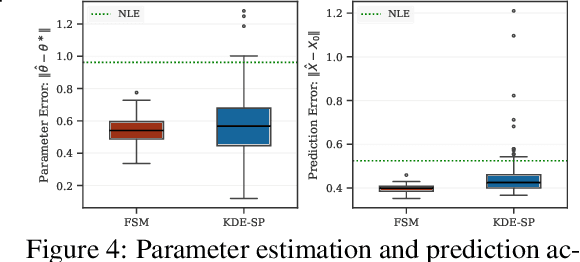
We study the problem of likelihood maximization when the likelihood function is intractable but model simulations are readily available. We propose a sequential, gradient-based optimization method that directly models the Fisher score based on a local score matching technique which uses simulations from a localized region around each parameter iterate. By employing a linear parameterization to the surrogate score model, our technique admits a closed-form, least-squares solution. This approach yields a fast, flexible, and efficient approximation to the Fisher score, effectively smoothing the likelihood objective and mitigating the challenges posed by complex likelihood landscapes. We provide theoretical guarantees for our score estimator, including bounds on the bias introduced by the smoothing. Empirical results on a range of synthetic and real-world problems demonstrate the superior performance of our method compared to existing benchmarks.
Missing Data Imputation by Reducing Mutual Information with Rectified Flows
May 16, 2025This paper introduces a novel iterative method for missing data imputation that sequentially reduces the mutual information between data and their corresponding missing mask. Inspired by GAN-based approaches, which train generators to decrease the predictability of missingness patterns, our method explicitly targets the reduction of mutual information. Specifically, our algorithm iteratively minimizes the KL divergence between the joint distribution of the imputed data and missing mask, and the product of their marginals from the previous iteration. We show that the optimal imputation under this framework corresponds to solving an ODE, whose velocity field minimizes a rectified flow training objective. We further illustrate that some existing imputation techniques can be interpreted as approximate special cases of our mutual-information-reducing framework. Comprehensive experiments on synthetic and real-world datasets validate the efficacy of our proposed approach, demonstrating superior imputation performance.
Every FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs
Mar 07, 2025



In this technical report, we tackle the challenges of training large-scale Mixture of Experts (MoE) models, focusing on overcoming cost inefficiency and resource limitations prevalent in such systems. To address these issues, we present two differently sized MoE large language models (LLMs), namely Ling-Lite and Ling-Plus (referred to as "Bailing" in Chinese, spelled B\v{a}il\'ing in Pinyin). Ling-Lite contains 16.8 billion parameters with 2.75 billion activated parameters, while Ling-Plus boasts 290 billion parameters with 28.8 billion activated parameters. Both models exhibit comparable performance to leading industry benchmarks. This report offers actionable insights to improve the efficiency and accessibility of AI development in resource-constrained settings, promoting more scalable and sustainable technologies. Specifically, to reduce training costs for large-scale MoE models, we propose innovative methods for (1) optimization of model architecture and training processes, (2) refinement of training anomaly handling, and (3) enhancement of model evaluation efficiency. Additionally, leveraging high-quality data generated from knowledge graphs, our models demonstrate superior capabilities in tool use compared to other models. Ultimately, our experimental findings demonstrate that a 300B MoE LLM can be effectively trained on lower-performance devices while achieving comparable performance to models of a similar scale, including dense and MoE models. Compared to high-performance devices, utilizing a lower-specification hardware system during the pre-training phase demonstrates significant cost savings, reducing computing costs by approximately 20%. The models can be accessed at https://huggingface.co/inclusionAI.