 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Doubly Robust Estimation of Conditional Quantile Contrasts
Jan 27, 2026Within heterogeneous treatment effect (HTE) analysis, various estimands have been proposed to capture the effect of a treatment conditional on covariates. Recently, the conditional quantile comparator (CQC) has emerged as a promising estimand, offering quantile-level summaries akin to the conditional quantile treatment effect (CQTE) while preserving some interpretability of the conditional average treatment effect (CATE). It achieves this by summarising the treated response conditional on both the covariates and the untreated response. Despite these desirable properties, the CQC's current estimation is limited by the need to first estimate the difference in conditional cumulative distribution functions and then invert it. This inversion obscures the CQC estimate, hampering our ability to both model and interpret it. To address this, we propose the first direct estimator of the CQC, allowing for explicit modelling and parameterisation. This explicit parameterisation enables better interpretation of our estimate while also providing a means to constrain and inform the model. We show, both theoretically and empirically, that our estimation error depends directly on the complexity of the CQC itself, improving upon the existing estimation procedure. Furthermore, it retains the desirable double robustness property with respect to nuisance parameter estimation. We further show our method to outperform existing procedures in estimation accuracy across multiple data scenarios while varying sample size and nuisance error. Finally, we apply it to real-world data from an employment scheme, uncovering a reduced range of potential earnings improvement as participant age increases.
Canonical Correlation Patterns for Validating Clustering of Multivariate Time Series
Jul 22, 2025Clustering of multivariate time series using correlation-based methods reveals regime changes in relationships between variables across health, finance, and industrial applications. However, validating whether discovered clusters represent distinct relationships rather than arbitrary groupings remains a fundamental challenge. Existing clustering validity indices were developed for Euclidean data, and their effectiveness for correlation patterns has not been systematically evaluated. Unlike Euclidean clustering, where geometric shapes provide discrete reference targets, correlations exist in continuous space without equivalent reference patterns. We address this validation gap by introducing canonical correlation patterns as mathematically defined validation targets that discretise the infinite correlation space into finite, interpretable reference patterns. Using synthetic datasets with perfect ground truth across controlled conditions, we demonstrate that canonical patterns provide reliable validation targets, with L1 norm for mapping and L5 norm for silhouette width criterion and Davies-Bouldin index showing superior performance. These methods are robust to distribution shifts and appropriately detect correlation structure degradation, enabling practical implementation guidelines. This work establishes a methodological foundation for rigorous correlation-based clustering validation in high-stakes domains.
CSTS: A Benchmark for the Discovery of Correlation Structures in Time Series Clustering
May 20, 2025Time series clustering promises to uncover hidden structural patterns in data with applications across healthcare, finance, industrial systems, and other critical domains. However, without validated ground truth information, researchers cannot objectively assess clustering quality or determine whether poor results stem from absent structures in the data, algorithmic limitations, or inappropriate validation methods, raising the question whether clustering is "more art than science" (Guyon et al., 2009). To address these challenges, we introduce CSTS (Correlation Structures in Time Series), a synthetic benchmark for evaluating the discovery of correlation structures in multivariate time series data. CSTS provides a clean benchmark that enables researchers to isolate and identify specific causes of clustering failures by differentiating between correlation structure deterioration and limitations of clustering algorithms and validation methods. Our contributions are: (1) a comprehensive benchmark for correlation structure discovery with distinct correlation structures, systematically varied data conditions, established performance thresholds, and recommended evaluation protocols; (2) empirical validation of correlation structure preservation showing moderate distortion from downsampling and minimal effects from distribution shifts and sparsification; and (3) an extensible data generation framework enabling structure-first clustering evaluation. A case study demonstrates CSTS's practical utility by identifying an algorithm's previously undocumented sensitivity to non-normal distributions, illustrating how the benchmark enables precise diagnosis of methodological limitations. CSTS advances rigorous evaluation standards for correlation-based time series clustering.
Conditional Outcome Equivalence: A Quantile Alternative to CATE
Oct 16, 2024



Conditional quantile treatment effect (CQTE) can provide insight into the effect of a treatment beyond the conditional average treatment effect (CATE). This ability to provide information over multiple quantiles of the response makes CQTE especially valuable in cases where the effect of a treatment is not well-modelled by a location shift, even conditionally on the covariates. Nevertheless, the estimation of CQTE is challenging and often depends upon the smoothness of the individual quantiles as a function of the covariates rather than smoothness of the CQTE itself. This is in stark contrast to CATE where it is possible to obtain high-quality estimates which have less dependency upon the smoothness of the nuisance parameters when the CATE itself is smooth. Moreover, relative smoothness of the CQTE lacks the interpretability of smoothness of the CATE making it less clear whether it is a reasonable assumption to make. We combine the desirable properties of CATE and CQTE by considering a new estimand, the conditional quantile comparator (CQC). The CQC not only retains information about the whole treatment distribution, similar to CQTE, but also having more natural examples of smoothness and is able to leverage simplicity in an auxiliary estimand. We provide finite sample bounds on the error of our estimator, demonstrating its ability to exploit simplicity. We validate our theory in numerical simulations which show that our method produces more accurate estimates than baselines. Finally, we apply our methodology to a study on the effect of employment incentives on earnings across different age groups. We see that our method is able to reveal heterogeneity of the effect across different quantiles.
An adaptive transfer learning perspective on classification in non-stationary environments
May 28, 2024We consider a semi-supervised classification problem with non-stationary label-shift in which we observe a labelled data set followed by a sequence of unlabelled covariate vectors in which the marginal probabilities of the class labels may change over time. Our objective is to predict the corresponding class-label for each covariate vector, without ever observing the ground-truth labels, beyond the initial labelled data set. Previous work has demonstrated the potential of sophisticated variants of online gradient descent to perform competitively with the optimal dynamic strategy (Bai et al. 2022). In this work we explore an alternative approach grounded in statistical methods for adaptive transfer learning. We demonstrate the merits of this alternative methodology by establishing a high-probability regret bound on the test error at any given individual test-time, which adapt automatically to the unknown dynamics of the marginal label probabilities. Further more, we give bounds on the average dynamic regret which match the average guarantees of the online learning perspective for any given time interval.
Density Ratio Estimation and Neyman Pearson Classification with Missing Data
Feb 21, 2023



Density Ratio Estimation (DRE) is an important machine learning technique with many downstream applications. We consider the challenge of DRE with missing not at random (MNAR) data. In this setting, we show that using standard DRE methods leads to biased results while our proposal (M-KLIEP), an adaptation of the popular DRE procedure KLIEP, restores consistency. Moreover, we provide finite sample estimation error bounds for M-KLIEP, which demonstrate minimax optimality with respect to both sample size and worst-case missingness. We then adapt an important downstream application of DRE, Neyman-Pearson (NP) classification, to this MNAR setting. Our procedure both controls Type I error and achieves high power, with high probability. Finally, we demonstrate promising empirical performance both synthetic data and real-world data with simulated missingness.
Classification with unknown class conditional label noise on non-compact feature spaces
Feb 14, 2019
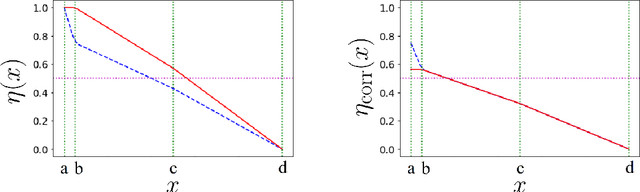
We investigate the problem of classification in the presence of unknown class conditional label noise in which the labels observed by the learner have been corrupted with some unknown class dependent probability. In order to obtain finite sample rates, previous approaches to classification with unknown class conditional label noise have required that the regression function attains its extrema uniformly on sets of positive measure. We shall consider this problem in the setting of non-compact metric spaces, where the regression function need not attain its extrema. In this setting we determine the minimax optimal learning rates (up to logarithmic factors). The rate displays interesting threshold behaviour: When the regression function approaches its extrema at a sufficient rate, the optimal learning rates are of the same order as those obtained in the label-noise free setting. If the regression function approaches its extrema more gradually then classification performance necessarily degrades. In addition, we present an algorithm which attains these rates without prior knowledge of either the distributional parameters or the local density. This identifies for the first time a scenario in which finite sample rates are achievable in the label noise setting, but they differ from the optimal rates without label noise.
Modular Autoencoders for Ensemble Feature Extraction
Nov 23, 2015


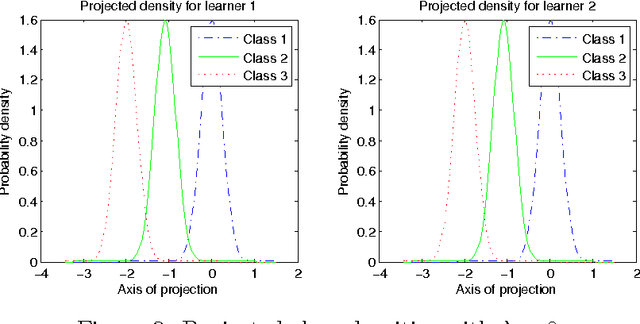
We introduce the concept of a Modular Autoencoder (MAE), capable of learning a set of diverse but complementary representations from unlabelled data, that can later be used for supervised tasks. The learning of the representations is controlled by a trade off parameter, and we show on six benchmark datasets the optimum lies between two extremes: a set of smaller, independent autoencoders each with low capacity, versus a single monolithic encoding, outperforming an appropriate baseline. In the present paper we explore the special case of linear MAE, and derive an SVD-based algorithm which converges several orders of magnitude faster than gradient descent.