 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical optimality conditions for compressive ensembles
Jun 02, 2021We present a framework for the theoretical analysis of ensembles of low-complexity empirical risk minimisers trained on independent random compressions of high-dimensional data. First we introduce a general distribution-dependent upper-bound on the excess risk, framed in terms of a natural notion of compressibility. This bound is independent of the dimension of the original data representation, and explains the in-built regularisation effect of the compressive approach. We then instantiate this general bound to classification and regression tasks, considering Johnson-Lindenstrauss mappings as the compression scheme. For each of these tasks, our strategy is to develop a tight upper bound on the compressibility function, and by doing so we discover distributional conditions of geometric nature under which the compressive algorithm attains minimax-optimal rates up to at most poly-logarithmic factors. In the case of compressive classification, this is achieved with a mild geometric margin condition along with a flexible moment condition that is significantly more general than the assumption of bounded domain. In the case of regression with strongly convex smooth loss functions we find that compressive regression is capable of exploiting spectral decay with near-optimal guarantees. In addition, a key ingredient for our central upper bound is a high probability uniform upper bound on the integrated deviation of dependent empirical processes, which may be of independent interest.
Optimistic bounds for multi-output prediction
Feb 22, 2020We investigate the challenge of multi-output learning, where the goal is to learn a vector-valued function based on a supervised data set. This includes a range of important problems in Machine Learning including multi-target regression, multi-class classification and multi-label classification. We begin our analysis by introducing the self-bounding Lipschitz condition for multi-output loss functions, which interpolates continuously between a classical Lipschitz condition and a multi-dimensional analogue of a smoothness condition. We then show that the self-bounding Lipschitz condition gives rise to optimistic bounds for multi-output learning, which are minimax optimal up to logarithmic factors. The proof exploits local Rademacher complexity combined with a powerful minoration inequality due to Srebro, Sridharan and Tewari. As an application we derive a state-of-the-art generalization bound for multi-class gradient boosting.
Fast Rates for a kNN Classifier Robust to Unknown Asymmetric Label Noise
Jun 11, 2019
We consider classification in the presence of class-dependent asymmetric label noise with unknown noise probabilities. In this setting, identifiability conditions are known, but additional assumptions were shown to be required for finite sample rates, and so far only the parametric rate has been obtained. Assuming these identifiability conditions, together with a measure-smoothness condition on the regression function and Tsybakov's margin condition, we show that the Robust kNN classifier of Gao et al. attains, the minimax optimal rates of the noise-free setting, up to a log factor, even when trained on data with unknown asymmetric label noise. Hence, our results provide a solid theoretical backing for this empirically successful algorithm. By contrast the standard kNN is not even consistent in the setting of asymmetric label noise. A key idea in our analysis is a simple kNN based method for estimating the maximum of a function that requires far less assumptions than existing mode estimators do, and which may be of independent interest for noise proportion estimation and randomised optimisation problems.
Classification with unknown class conditional label noise on non-compact feature spaces
Feb 14, 2019
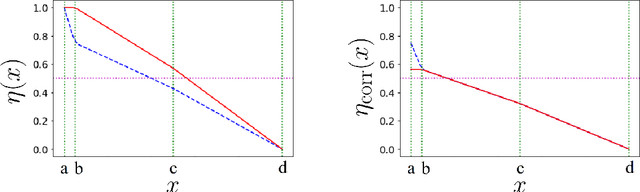
We investigate the problem of classification in the presence of unknown class conditional label noise in which the labels observed by the learner have been corrupted with some unknown class dependent probability. In order to obtain finite sample rates, previous approaches to classification with unknown class conditional label noise have required that the regression function attains its extrema uniformly on sets of positive measure. We shall consider this problem in the setting of non-compact metric spaces, where the regression function need not attain its extrema. In this setting we determine the minimax optimal learning rates (up to logarithmic factors). The rate displays interesting threshold behaviour: When the regression function approaches its extrema at a sufficient rate, the optimal learning rates are of the same order as those obtained in the label-noise free setting. If the regression function approaches its extrema more gradually then classification performance necessarily degrades. In addition, we present an algorithm which attains these rates without prior knowledge of either the distributional parameters or the local density. This identifies for the first time a scenario in which finite sample rates are achievable in the label noise setting, but they differ from the optimal rates without label noise.
Boosting in the presence of label noise
Sep 26, 2013
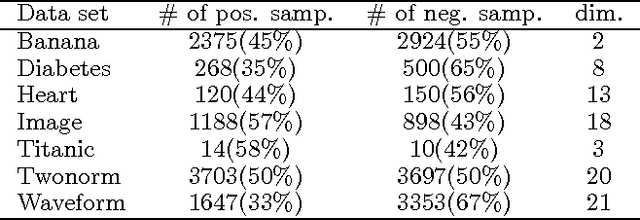


Boosting is known to be sensitive to label noise. We studied two approaches to improve AdaBoost's robustness against labelling errors. One is to employ a label-noise robust classifier as a base learner, while the other is to modify the AdaBoost algorithm to be more robust. Empirical evaluation shows that a committee of robust classifiers, although converges faster than non label-noise aware AdaBoost, is still susceptible to label noise. However, pairing it with the new robust Boosting algorithm we propose here results in a more resilient algorithm under mislabelling.