Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModular Autoencoders for Ensemble Feature Extraction
Paper and Code
Nov 23, 2015


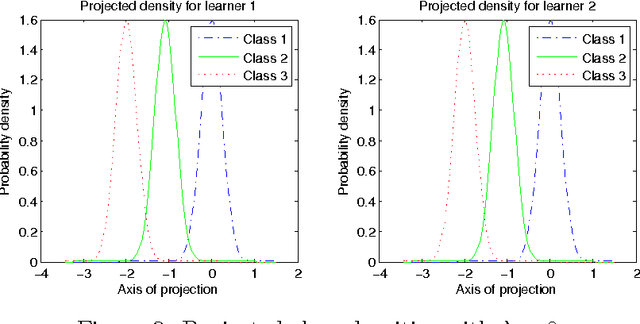
We introduce the concept of a Modular Autoencoder (MAE), capable of learning a set of diverse but complementary representations from unlabelled data, that can later be used for supervised tasks. The learning of the representations is controlled by a trade off parameter, and we show on six benchmark datasets the optimum lies between two extremes: a set of smaller, independent autoencoders each with low capacity, versus a single monolithic encoding, outperforming an appropriate baseline. In the present paper we explore the special case of linear MAE, and derive an SVD-based algorithm which converges several orders of magnitude faster than gradient descent.
* 18 pages, 8 figures, to appear in a special issue of The Journal Of
Machine Learning Research (vol.44, Dec 2015)
View paper on