 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSig-DEG for Distillation: Making Diffusion Models Faster and Lighter
Aug 23, 2025Diffusion models have achieved state-of-the-art results in generative modelling but remain computationally intensive at inference time, often requiring thousands of discretization steps. To this end, we propose Sig-DEG (Signature-based Differential Equation Generator), a novel generator for distilling pre-trained diffusion models, which can universally approximate the backward diffusion process at a coarse temporal resolution. Inspired by high-order approximations of stochastic differential equations (SDEs), Sig-DEG leverages partial signatures to efficiently summarize Brownian motion over sub-intervals and adopts a recurrent structure to enable accurate global approximation of the SDE solution. Distillation is formulated as a supervised learning task, where Sig-DEG is trained to match the outputs of a fine-resolution diffusion model on a coarse time grid. During inference, Sig-DEG enables fast generation, as the partial signature terms can be simulated exactly without requiring fine-grained Brownian paths. Experiments demonstrate that Sig-DEG achieves competitive generation quality while reducing the number of inference steps by an order of magnitude. Our results highlight the effectiveness of signature-based approximations for efficient generative modeling.
Bridging the Gap Between Variational Inference and Wasserstein Gradient Flows
Oct 31, 2023Variational inference is a technique that approximates a target distribution by optimizing within the parameter space of variational families. On the other hand, Wasserstein gradient flows describe optimization within the space of probability measures where they do not necessarily admit a parametric density function. In this paper, we bridge the gap between these two methods. We demonstrate that, under certain conditions, the Bures-Wasserstein gradient flow can be recast as the Euclidean gradient flow where its forward Euler scheme is the standard black-box variational inference algorithm. Specifically, the vector field of the gradient flow is generated via the path-derivative gradient estimator. We also offer an alternative perspective on the path-derivative gradient, framing it as a distillation procedure to the Wasserstein gradient flow. Distillations can be extended to encompass $f$-divergences and non-Gaussian variational families. This extension yields a new gradient estimator for $f$-divergences, readily implementable using contemporary machine learning libraries like PyTorch or TensorFlow.
Variational Gradient Descent using Local Linear Models
May 24, 2023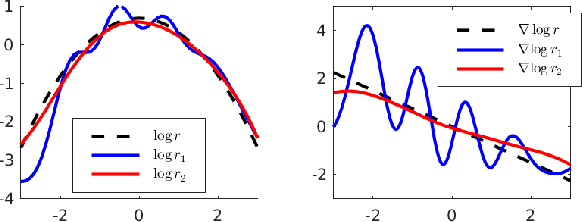

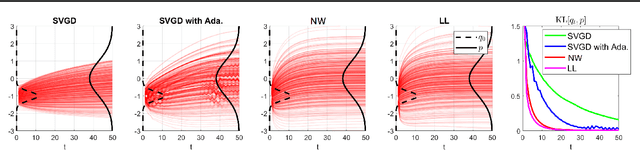

Stein Variational Gradient Descent (SVGD) can transport particles along trajectories that reduce the KL divergence between the target and particle distribution but requires the target score function to compute the update. We introduce a new perspective on SVGD that views it as a local estimator of the reversed KL gradient flow. This perspective inspires us to propose new estimators that use local linear models to achieve the same purpose. The proposed estimators can be computed using only samples from the target and particle distribution without needing the target score function. Our proposed variational gradient estimators utilize local linear models, resulting in computational simplicity while maintaining effectiveness comparable to SVGD in terms of estimation biases. Additionally, we demonstrate that under a mild assumption, the estimation of high-dimensional gradient flow can be translated into a lower-dimensional estimation problem, leading to improved estimation accuracy. We validate our claims with experiments on both simulated and real-world datasets.
MonoFlow: Rethinking Divergence GANs via the Perspective of Differential Equations
Feb 03, 2023



The conventional understanding of adversarial training in generative adversarial networks (GANs) is that the discriminator is trained to estimate a divergence, and the generator learns to minimize this divergence. We argue that despite the fact that many variants of GANs were developed following this paradigm, the current theoretical understanding of GANs and their practical algorithms are inconsistent. In this paper, we leverage Wasserstein gradient flows which characterize the evolution of particles in the sample space, to gain theoretical insights and algorithmic inspiration of GANs. We introduce a unified generative modeling framework - MonoFlow: the particle evolution is rescaled via a monotonically increasing mapping of the log density ratio. Under our framework, adversarial training can be viewed as a procedure first obtaining MonoFlow's vector field via training the discriminator and the generator learns to draw the particle flow defined by the corresponding vector field. We also reveal the fundamental difference between variational divergence minimization and adversarial training. This analysis helps us to identify what types of generator loss functions can lead to the successful training of GANs and suggest that GANs may have more loss designs beyond the literature (e.g., non-saturated loss), as long as they realize MonoFlow. Consistent empirical studies are included to validate the effectiveness of our framework.
Sliced Wasserstein Variational Inference
Jul 26, 2022
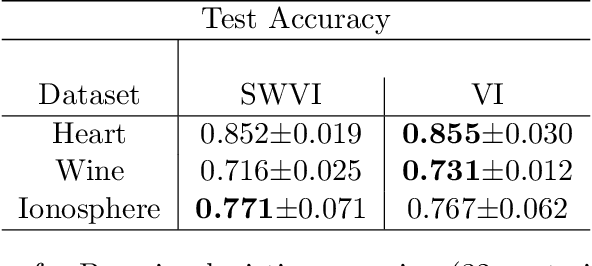

Variational Inference approximates an unnormalized distribution via the minimization of Kullback-Leibler (KL) divergence. Although this divergence is efficient for computation and has been widely used in applications, it suffers from some unreasonable properties. For example, it is not a proper metric, i.e., it is non-symmetric and does not preserve the triangle inequality. On the other hand, optimal transport distances recently have shown some advantages over KL divergence. With the help of these advantages, we propose a new variational inference method by minimizing sliced Wasserstein distance, a valid metric arising from optimal transport. This sliced Wasserstein distance can be approximated simply by running MCMC but without solving any optimization problem. Our approximation also does not require a tractable density function of variational distributions so that approximating families can be amortized by generators like neural networks. Furthermore, we provide an analysis of the theoretical properties of our method. Experiments on synthetic and real data are illustrated to show the performance of the proposed method.
Posterior Ratio Estimation for Latent Variables
Feb 15, 2020
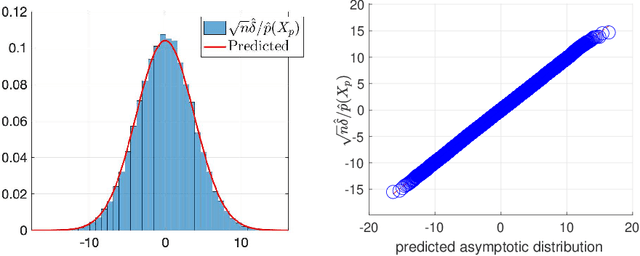


Density Ratio Estimation has attracted attention from machine learning community due to its ability of comparing the underlying distributions of two datasets. However, in some applications, we want to compare distributions of \emph{latent} random variables that can be only inferred from observations. In this paper, we study the problem of estimating the ratio between two posterior probability density functions of a latent variable. Particularly, we assume the posterior ratio function can be well-approximated by a parametric model, which is then estimated using observed datasets and synthetic prior samples. We prove consistency of our estimator and the asymptotic normality of the estimated parameters as the number of prior samples tending to infinity. Finally, we validate our theories using numerical experiments and demonstrate the usefulness of the proposed method through some real-world applications.