 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-loss-aware Channel Pruning of Deep Networks
Paper and Code
Feb 27, 2019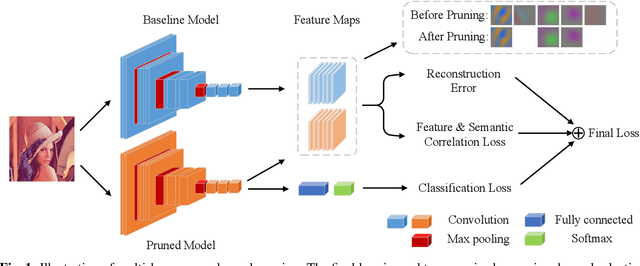
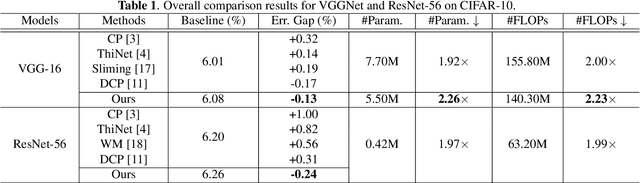
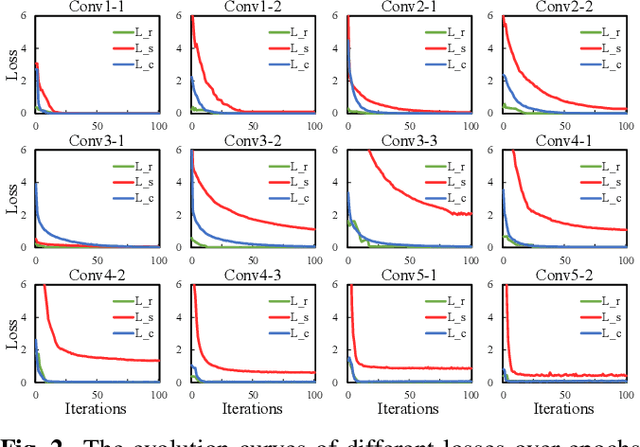
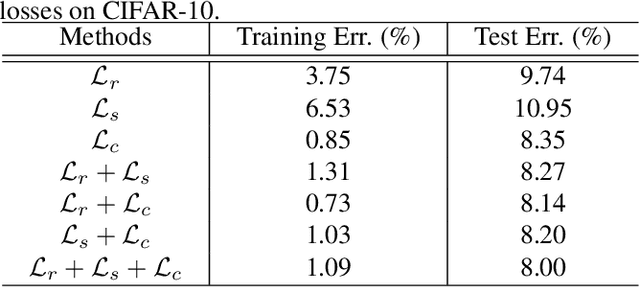
Channel pruning, which seeks to reduce the model size by removing redundant channels, is a popular solution for deep networks compression. Existing channel pruning methods usually conduct layer-wise channel selection by directly minimizing the reconstruction error of feature maps between the baseline model and the pruned one. However, they ignore the feature and semantic distributions within feature maps and real contribution of channels to the overall performance. In this paper, we propose a new channel pruning method by explicitly using both intermediate outputs of the baseline model and the classification loss of the pruned model to supervise layer-wise channel selection. Particularly, we introduce an additional loss to encode the differences in the feature and semantic distributions within feature maps between the baseline model and the pruned one. By considering the reconstruction error, the additional loss and the classification loss at the same time, our approach can significantly improve the performance of the pruned model. Comprehensive experiments on benchmark datasets demonstrate the effectiveness of the proposed method.