 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveDreamer-Policy: A Geometry-Grounded World-Action Model for Unified Generation and Planning
Apr 02, 2026Recently, world-action models (WAM) have emerged to bridge vision-language-action (VLA) models and world models, unifying their reasoning and instruction-following capabilities and spatio-temporal world modeling. However, existing WAM approaches often focus on modeling 2D appearance or latent representations, with limited geometric grounding-an essential element for embodied systems operating in the physical world. We present DriveDreamer-Policy, a unified driving world-action model that integrates depth generation, future video generation, and motion planning within a single modular architecture. The model employs a large language model to process language instructions, multi-view images, and actions, followed by three lightweight generators that produce depth, future video, and actions. By learning a geometry-aware world representation and using it to guide both future prediction and planning within a unified framework, the proposed model produces more coherent imagined futures and more informed driving actions, while maintaining modularity and controllable latency. Experiments on the Navsim v1 and v2 benchmarks demonstrate that DriveDreamer-Policy achieves strong performance on both closed-loop planning and world generation tasks. In particular, our model reaches 89.2 PDMS on Navsim v1 and 88.7 EPDMS on Navsim v2, outperforming existing world-model-based approaches while producing higher-quality future video and depth predictions. Ablation studies further show that explicit depth learning provides complementary benefits to video imagination and improves planning robustness.
WebFace260M: A Benchmark for Million-Scale Deep Face Recognition
Apr 21, 2022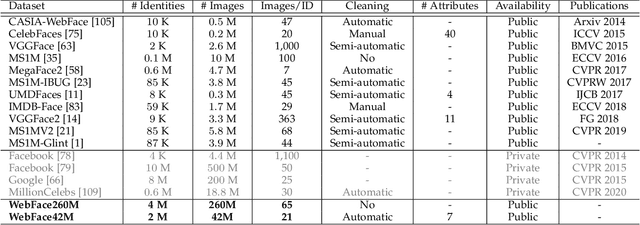

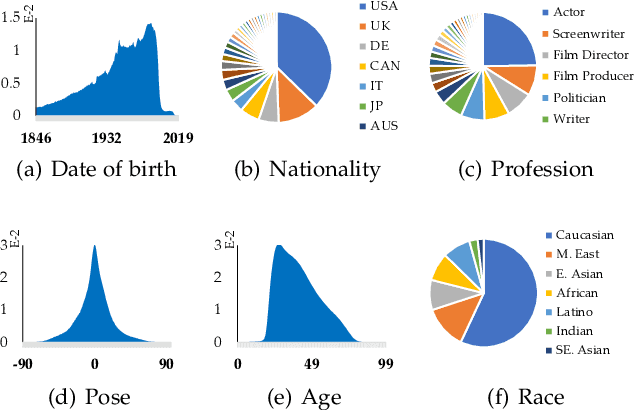
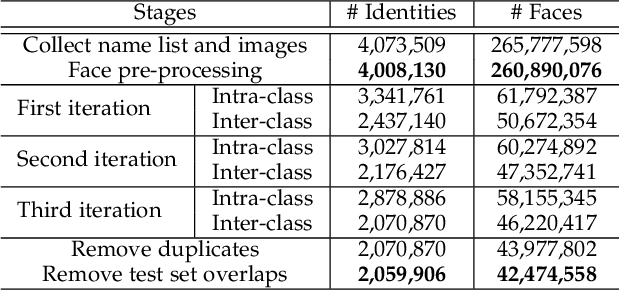
Face benchmarks empower the research community to train and evaluate high-performance face recognition systems. In this paper, we contribute a new million-scale recognition benchmark, containing uncurated 4M identities/260M faces (WebFace260M) and cleaned 2M identities/42M faces (WebFace42M) training data, as well as an elaborately designed time-constrained evaluation protocol. Firstly, we collect 4M name lists and download 260M faces from the Internet. Then, a Cleaning Automatically utilizing Self-Training (CAST) pipeline is devised to purify the tremendous WebFace260M, which is efficient and scalable. To the best of our knowledge, the cleaned WebFace42M is the largest public face recognition training set and we expect to close the data gap between academia and industry. Referring to practical deployments, Face Recognition Under Inference Time conStraint (FRUITS) protocol and a new test set with rich attributes are constructed. Besides, we gather a large-scale masked face sub-set for biometrics assessment under COVID-19. For a comprehensive evaluation of face matchers, three recognition tasks are performed under standard, masked and unbiased settings, respectively. Equipped with this benchmark, we delve into million-scale face recognition problems. A distributed framework is developed to train face recognition models efficiently without tampering with the performance. Enabled by WebFace42M, we reduce 40% failure rate on the challenging IJB-C set and rank 3rd among 430 entries on NIST-FRVT. Even 10% data (WebFace4M) shows superior performance compared with the public training sets. Furthermore, comprehensive baselines are established under the FRUITS-100/500/1000 milliseconds protocols. The proposed benchmark shows enormous potential on standard, masked and unbiased face recognition scenarios. Our WebFace260M website is https://www.face-benchmark.org.
Face-NMS: A Core-set Selection Approach for Efficient Face Recognition
Sep 10, 2021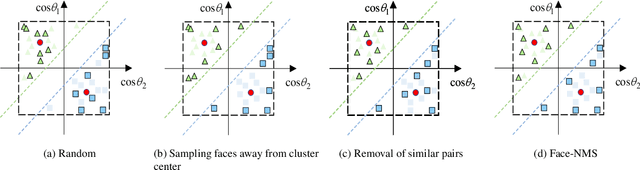
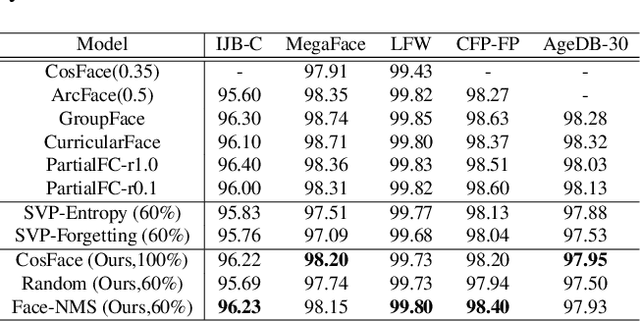
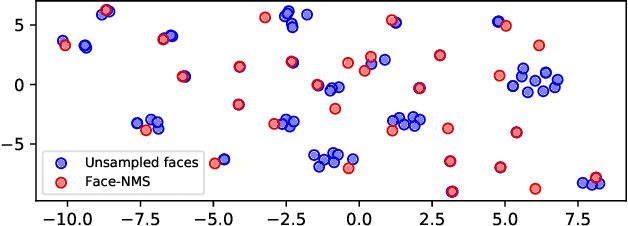
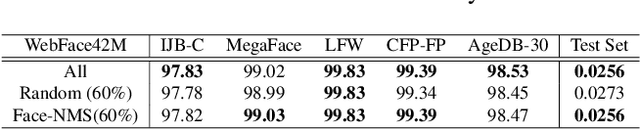
Recently, face recognition in the wild has achieved remarkable success and one key engine is the increasing size of training data. For example, the largest face dataset, WebFace42M contains about 2 million identities and 42 million faces. However, a massive number of faces raise the constraints in training time, computing resources, and memory cost. The current research on this problem mainly focuses on designing an efficient Fully-connected layer (FC) to reduce GPU memory consumption caused by a large number of identities. In this work, we relax these constraints by resolving the redundancy problem of the up-to-date face datasets caused by the greedily collecting operation (i.e. the core-set selection perspective). As the first attempt in this perspective on the face recognition problem, we find that existing methods are limited in both performance and efficiency. For superior cost-efficiency, we contribute a novel filtering strategy dubbed Face-NMS. Face-NMS works on feature space and simultaneously considers the local and global sparsity in generating core sets. In practice, Face-NMS is analogous to Non-Maximum Suppression (NMS) in the object detection community. It ranks the faces by their potential contribution to the overall sparsity and filters out the superfluous face in the pairs with high similarity for local sparsity. With respect to the efficiency aspect, Face-NMS accelerates the whole pipeline by applying a smaller but sufficient proxy dataset in training the proxy model. As a result, with Face-NMS, we successfully scale down the WebFace42M dataset to 60% while retaining its performance on the main benchmarks, offering a 40% resource-saving and 1.64 times acceleration. The code is publicly available for reference at https://github.com/HuangJunJie2017/Face-NMS.
Masked Face Recognition Challenge: The WebFace260M Track Report
Aug 16, 2021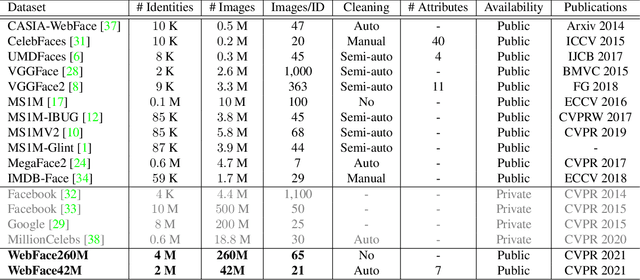
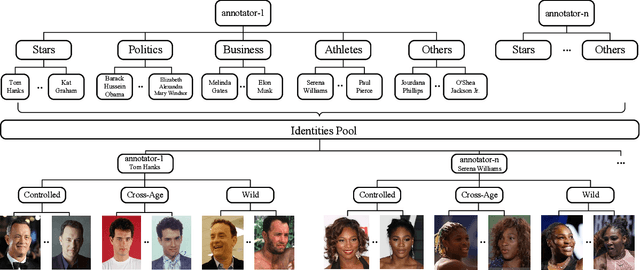
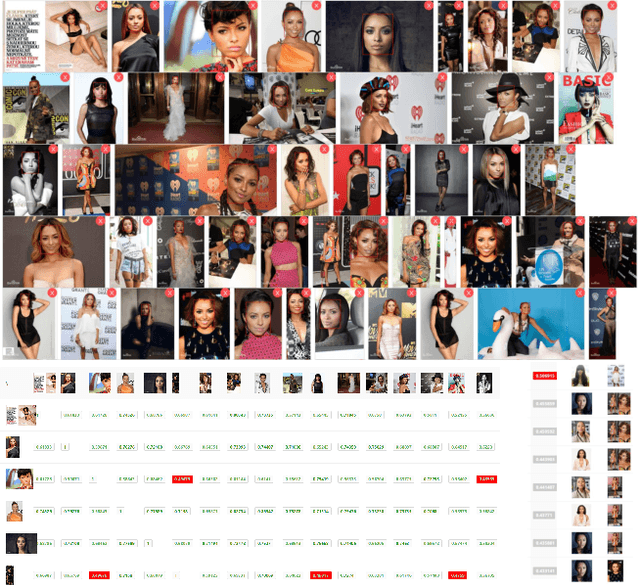
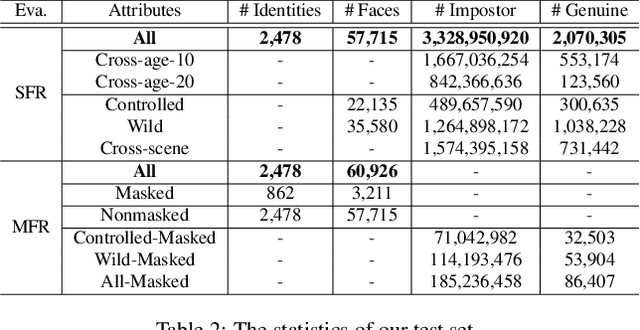
According to WHO statistics, there are more than 204,617,027 confirmed COVID-19 cases including 4,323,247 deaths worldwide till August 12, 2021. During the coronavirus epidemic, almost everyone wears a facial mask. Traditionally, face recognition approaches process mostly non-occluded faces, which include primary facial features such as the eyes, nose, and mouth. Removing the mask for authentication in airports or laboratories will increase the risk of virus infection, posing a huge challenge to current face recognition systems. Due to the sudden outbreak of the epidemic, there are yet no publicly available real-world masked face recognition (MFR) benchmark. To cope with the above-mentioned issue, we organize the Face Bio-metrics under COVID Workshop and Masked Face Recognition Challenge in ICCV 2021. Enabled by the ultra-large-scale WebFace260M benchmark and the Face Recognition Under Inference Time conStraint (FRUITS) protocol, this challenge (WebFace260M Track) aims to push the frontiers of practical MFR. Since public evaluation sets are mostly saturated or contain noise, a new test set is gathered consisting of elaborated 2,478 celebrities and 60,926 faces. Meanwhile, we collect the world-largest real-world masked test set. In the first phase of WebFace260M Track, 69 teams (total 833 solutions) participate in the challenge and 49 teams exceed the performance of our baseline. There are second phase of the challenge till October 1, 2021 and on-going leaderboard. We will actively update this report in the future.
WebFace260M: A Benchmark Unveiling the Power of Million-Scale Deep Face Recognition
Mar 06, 2021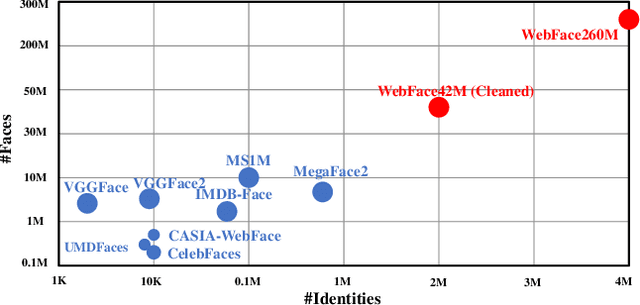
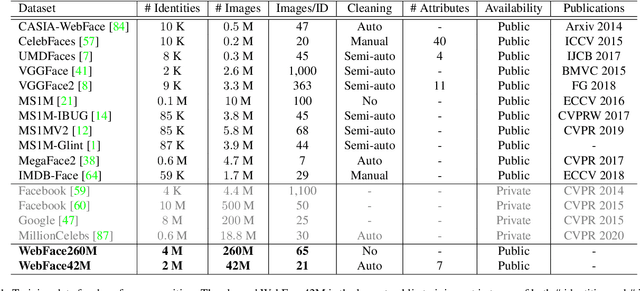
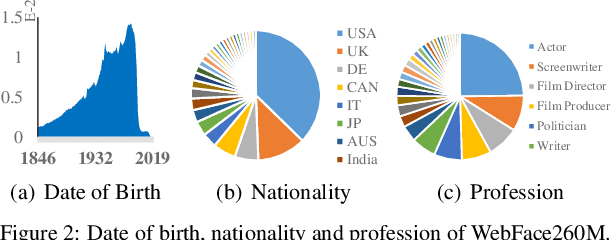
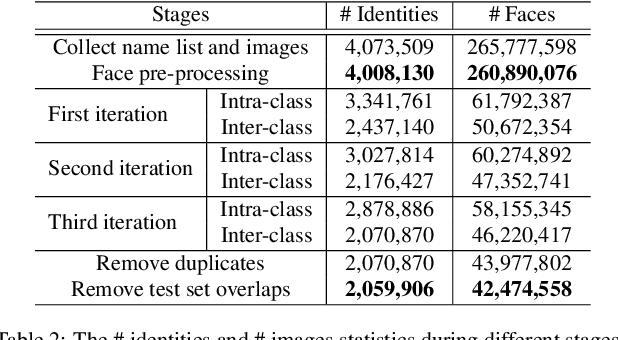
In this paper, we contribute a new million-scale face benchmark containing noisy 4M identities/260M faces (WebFace260M) and cleaned 2M identities/42M faces (WebFace42M) training data, as well as an elaborately designed time-constrained evaluation protocol. Firstly, we collect 4M name list and download 260M faces from the Internet. Then, a Cleaning Automatically utilizing Self-Training (CAST) pipeline is devised to purify the tremendous WebFace260M, which is efficient and scalable. To the best of our knowledge, the cleaned WebFace42M is the largest public face recognition training set and we expect to close the data gap between academia and industry. Referring to practical scenarios, Face Recognition Under Inference Time conStraint (FRUITS) protocol and a test set are constructed to comprehensively evaluate face matchers. Equipped with this benchmark, we delve into million-scale face recognition problems. A distributed framework is developed to train face recognition models efficiently without tampering with the performance. Empowered by WebFace42M, we reduce relative 40% failure rate on the challenging IJB-C set, and ranks the 3rd among 430 entries on NIST-FRVT. Even 10% data (WebFace4M) shows superior performance compared with public training set. Furthermore, comprehensive baselines are established on our rich-attribute test set under FRUITS-100ms/500ms/1000ms protocol, including MobileNet, EfficientNet, AttentionNet, ResNet, SENet, ResNeXt and RegNet families. Benchmark website is https://www.face-benchmark.org.
Semi-Global Shape-aware Network
Dec 17, 2020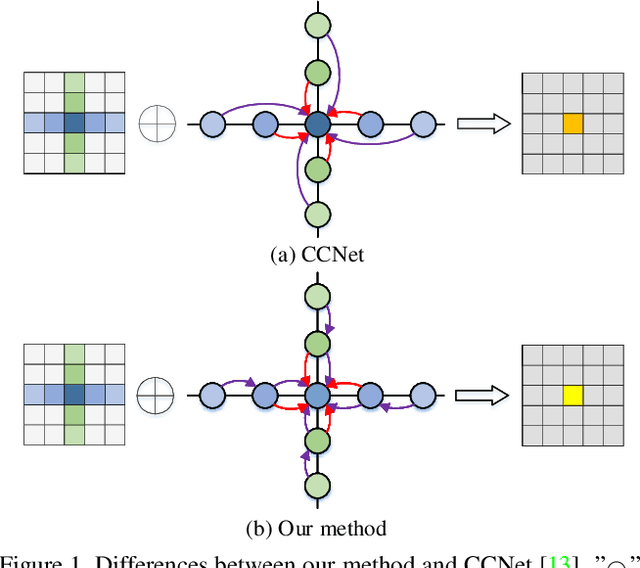

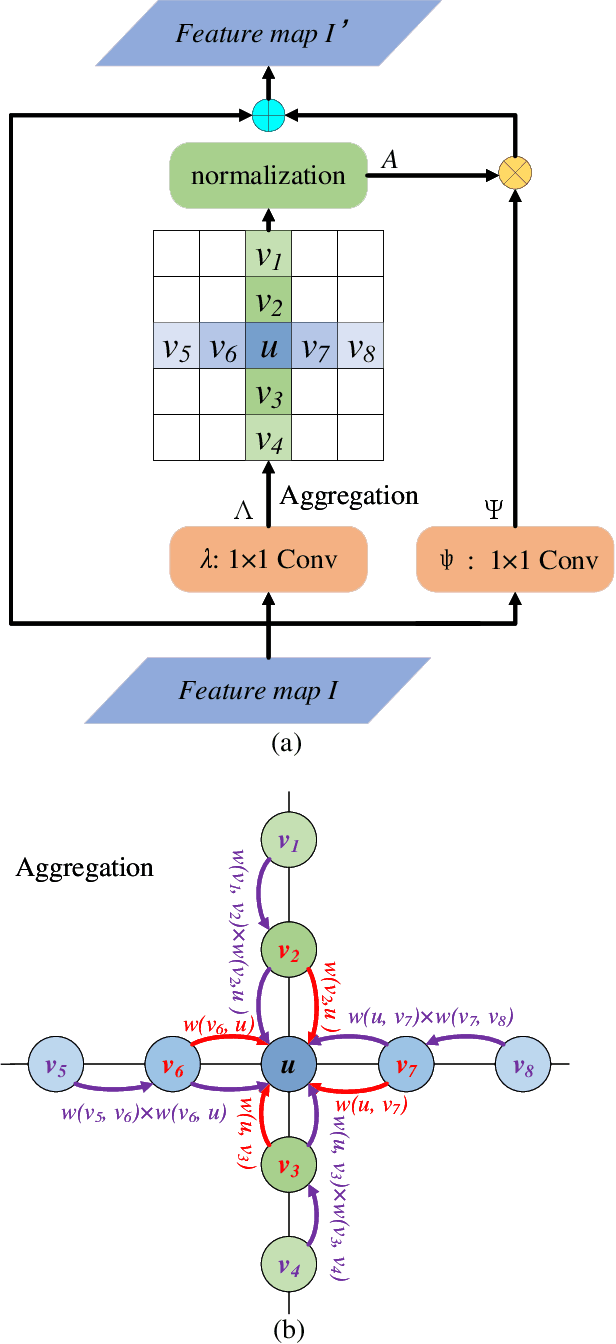
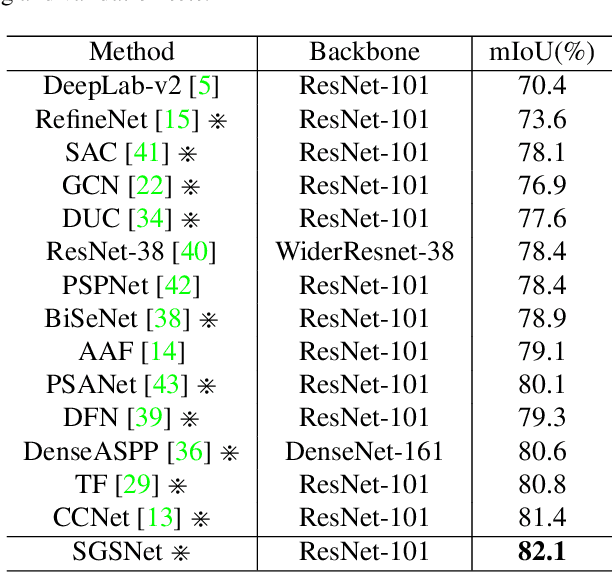
Non-local operations are usually used to capture long-range dependencies via aggregating global context to each position recently. However, most of the methods cannot preserve object shapes since they only focus on feature similarity but ignore proximity between central and other positions for capturing long-range dependencies, while shape-awareness is beneficial to many computer vision tasks. In this paper, we propose a Semi-Global Shape-aware Network (SGSNet) considering both feature similarity and proximity for preserving object shapes when modeling long-range dependencies. A hierarchical way is taken to aggregate global context. In the first level, each position in the whole feature map only aggregates contextual information in vertical and horizontal directions according to both similarity and proximity. And then the result is input into the second level to do the same operations. By this hierarchical way, each central position gains supports from all other positions, and the combination of similarity and proximity makes each position gain supports mostly from the same semantic object. Moreover, we also propose a linear time algorithm for the aggregation of contextual information, where each of rows and columns in the feature map is treated as a binary tree to reduce similarity computation cost. Experiments on semantic segmentation and image retrieval show that adding SGSNet to existing networks gains solid improvements on both accuracy and efficiency.
Cluster Regularized Quantization for Deep Networks Compression
Feb 27, 2019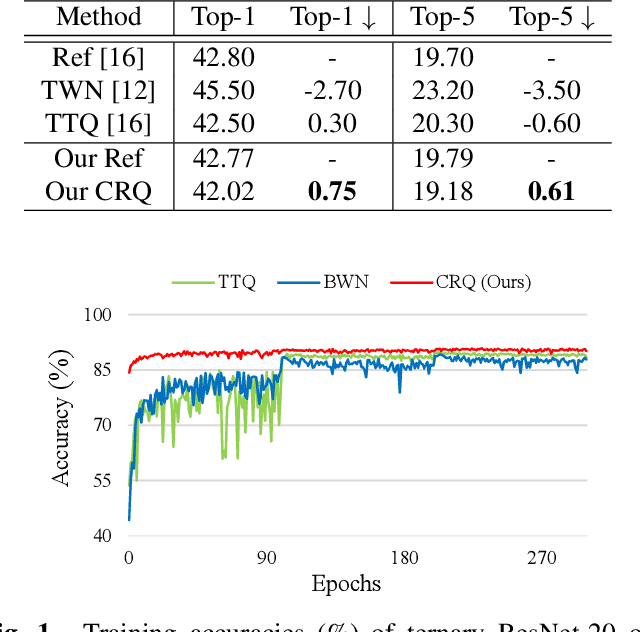


Deep neural networks (DNNs) have achieved great success in a wide range of computer vision areas, but the applications to mobile devices is limited due to their high storage and computational cost. Much efforts have been devoted to compress DNNs. In this paper, we propose a simple yet effective method for deep networks compression, named Cluster Regularized Quantization (CRQ), which can reduce the presentation precision of a full-precision model to ternary values without significant accuracy drop. In particular, the proposed method aims at reducing the quantization error by introducing a cluster regularization term, which is imposed on the full-precision weights to enable them naturally concentrate around the target values. Through explicitly regularizing the weights during the re-training stage, the full-precision model can achieve the smooth transition to the low-bit one. Comprehensive experiments on benchmark datasets demonstrate the effectiveness of the proposed method.
Multi-loss-aware Channel Pruning of Deep Networks
Feb 27, 2019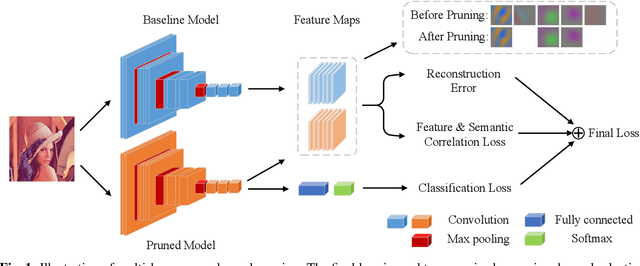
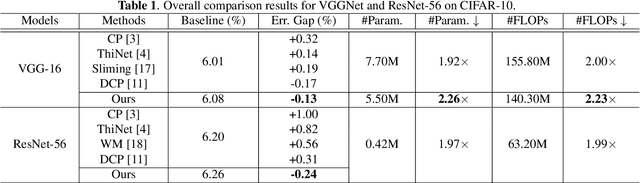
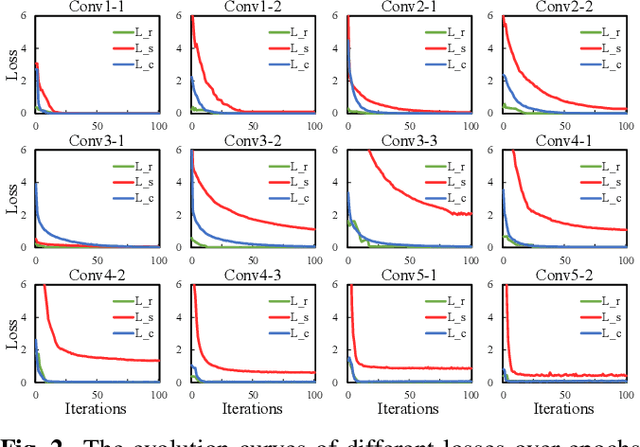
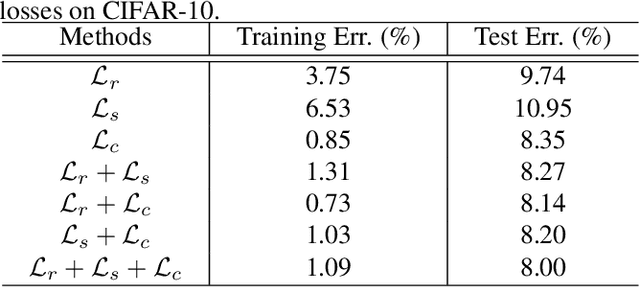
Channel pruning, which seeks to reduce the model size by removing redundant channels, is a popular solution for deep networks compression. Existing channel pruning methods usually conduct layer-wise channel selection by directly minimizing the reconstruction error of feature maps between the baseline model and the pruned one. However, they ignore the feature and semantic distributions within feature maps and real contribution of channels to the overall performance. In this paper, we propose a new channel pruning method by explicitly using both intermediate outputs of the baseline model and the classification loss of the pruned model to supervise layer-wise channel selection. Particularly, we introduce an additional loss to encode the differences in the feature and semantic distributions within feature maps between the baseline model and the pruned one. By considering the reconstruction error, the additional loss and the classification loss at the same time, our approach can significantly improve the performance of the pruned model. Comprehensive experiments on benchmark datasets demonstrate the effectiveness of the proposed method.
Action Machine: Rethinking Action Recognition in Trimmed Videos
Dec 17, 2018
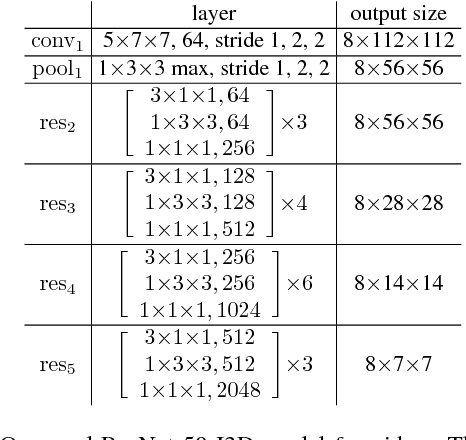
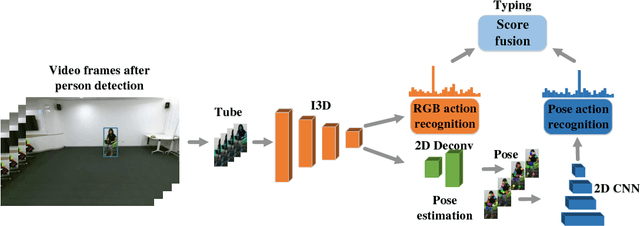

Existing methods in video action recognition mostly do not distinguish human body from the environment and easily overfit the scenes and objects. In this work, we present a conceptually simple, general and high-performance framework for action recognition in trimmed videos, aiming at person-centric modeling. The method, called Action Machine, takes as inputs the videos cropped by person bounding boxes. It extends the Inflated 3D ConvNet (I3D) by adding a branch for human pose estimation and a 2D CNN for pose-based action recognition, being fast to train and test. Action Machine can benefit from the multi-task training of action recognition and pose estimation, the fusion of predictions from RGB images and poses. On NTU RGB-D, Action Machine achieves the state-of-the-art performance with top-1 accuracies of 97.2% and 94.3% on cross-view and cross-subject respectively. Action Machine also achieves competitive performance on another three smaller action recognition datasets: Northwestern UCLA Multiview Action3D, MSR Daily Activity3D and UTD-MHAD. Code will be made available.
An Efficient Optical Flow Based Motion Detection Method for Non-stationary Scenes
Nov 21, 2018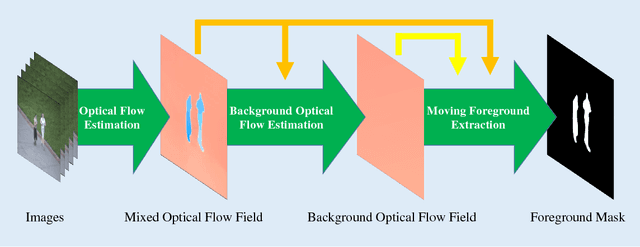

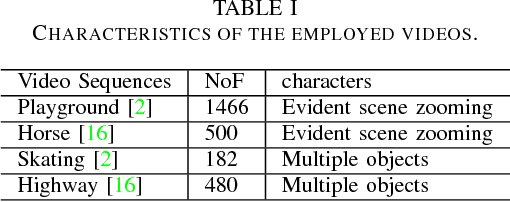
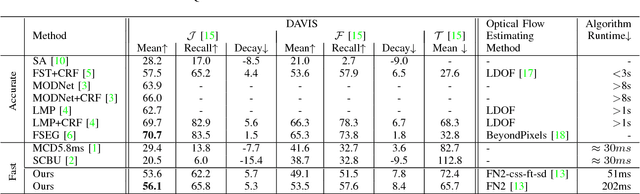
Real-time motion detection in non-stationary scenes is a difficult task due to dynamic background, changing foreground appearance and limited computational resource. These challenges degrade the performance of the existing methods in practical applications. In this paper, an optical flow based framework is proposed to address this problem. By applying a novel strategy to utilize optical flow, we enable our method being free of model constructing, training or updating and can be performed efficiently. Besides, a dual judgment mechanism with adaptive intervals and adaptive thresholds is designed to heighten the system's adaptation to different situations. In experiment part, we quantitatively and qualitatively validate the effectiveness and feasibility of our method with videos in various scene conditions. The experimental results show that our method adapts itself to different situations and outperforms the state-of-the-art real-time methods, indicating the advantages of our optical flow based method.