 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMambaSeg: Harnessing Mamba for Accurate and Efficient Image-Event Semantic Segmentation
Dec 30, 2025Semantic segmentation is a fundamental task in computer vision with wide-ranging applications, including autonomous driving and robotics. While RGB-based methods have achieved strong performance with CNNs and Transformers, their effectiveness degrades under fast motion, low-light, or high dynamic range conditions due to limitations of frame cameras. Event cameras offer complementary advantages such as high temporal resolution and low latency, yet lack color and texture, making them insufficient on their own. To address this, recent research has explored multimodal fusion of RGB and event data; however, many existing approaches are computationally expensive and focus primarily on spatial fusion, neglecting the temporal dynamics inherent in event streams. In this work, we propose MambaSeg, a novel dual-branch semantic segmentation framework that employs parallel Mamba encoders to efficiently model RGB images and event streams. To reduce cross-modal ambiguity, we introduce the Dual-Dimensional Interaction Module (DDIM), comprising a Cross-Spatial Interaction Module (CSIM) and a Cross-Temporal Interaction Module (CTIM), which jointly perform fine-grained fusion along both spatial and temporal dimensions. This design improves cross-modal alignment, reduces ambiguity, and leverages the complementary properties of each modality. Extensive experiments on the DDD17 and DSEC datasets demonstrate that MambaSeg achieves state-of-the-art segmentation performance while significantly reducing computational cost, showcasing its promise for efficient, scalable, and robust multimodal perception.
Heteroscedastic Bayesian Optimization-Based Dynamic PID Tuning for Accurate and Robust UAV Trajectory Tracking
Dec 30, 2025Unmanned Aerial Vehicles (UAVs) play an important role in various applications, where precise trajectory tracking is crucial. However, conventional control algorithms for trajectory tracking often exhibit limited performance due to the underactuated, nonlinear, and highly coupled dynamics of quadrotor systems. To address these challenges, we propose HBO-PID, a novel control algorithm that integrates the Heteroscedastic Bayesian Optimization (HBO) framework with the classical PID controller to achieve accurate and robust trajectory tracking. By explicitly modeling input-dependent noise variance, the proposed method can better adapt to dynamic and complex environments, and therefore improve the accuracy and robustness of trajectory tracking. To accelerate the convergence of optimization, we adopt a two-stage optimization strategy that allow us to more efficiently find the optimal controller parameters. Through experiments in both simulation and real-world scenarios, we demonstrate that the proposed method significantly outperforms state-of-the-art (SOTA) methods. Compared to SOTA methods, it improves the position accuracy by 24.7% to 42.9%, and the angular accuracy by 40.9% to 78.4%.
* Accepted by IROS 2025 (2025 IEEE/RSJ International Conference on Intelligent Robots and Systems)
Efficient Event-based Semantic Segmentation with Spike-driven Lightweight Transformer-based Networks
Dec 17, 2024



Event-based semantic segmentation has great potential in autonomous driving and robotics due to the advantages of event cameras, such as high dynamic range, low latency, and low power cost. Unfortunately, current artificial neural network (ANN)-based segmentation methods suffer from high computational demands, the requirements for image frames, and massive energy consumption, limiting their efficiency and application on resource-constrained edge/mobile platforms. To address these problems, we introduce SLTNet, a spike-driven lightweight transformer-based network designed for event-based semantic segmentation. Specifically, SLTNet is built on efficient spike-driven convolution blocks (SCBs) to extract rich semantic features while reducing the model's parameters. Then, to enhance the long-range contextural feature interaction, we propose novel spike-driven transformer blocks (STBs) with binary mask operations. Based on these basic blocks, SLTNet employs a high-efficiency single-branch architecture while maintaining the low energy consumption of the Spiking Neural Network (SNN). Finally, extensive experiments on DDD17 and DSEC-Semantic datasets demonstrate that SLTNet outperforms state-of-the-art (SOTA) SNN-based methods by at least 7.30% and 3.30% mIoU, respectively, with extremely 5.48x lower energy consumption and 1.14x faster inference speed.
A Novel Wide-Area Multiobject Detection System with High-Probability Region Searching
May 07, 2024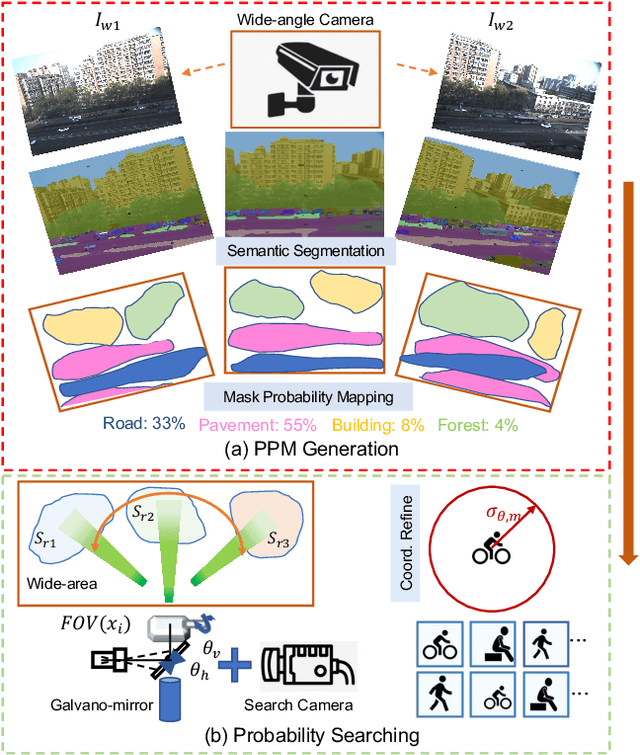
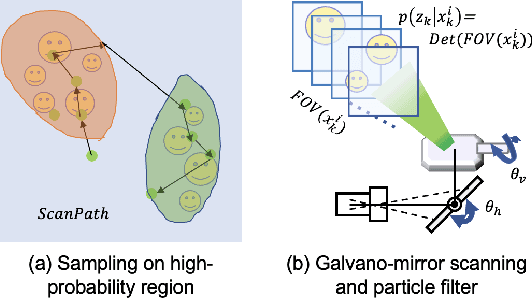

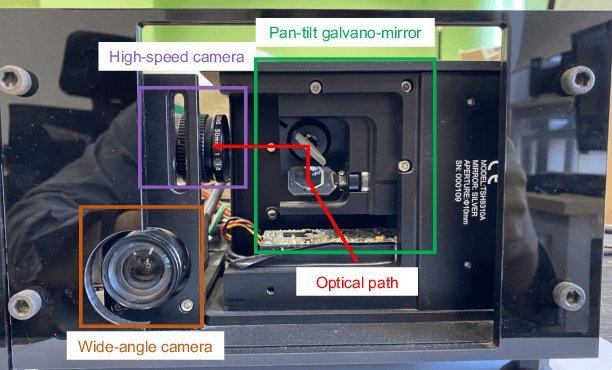
In recent years, wide-area visual surveillance systems have been widely applied in various industrial and transportation scenarios. These systems, however, face significant challenges when implementing multi-object detection due to conflicts arising from the need for high-resolution imaging, efficient object searching, and accurate localization. To address these challenges, this paper presents a hybrid system that incorporates a wide-angle camera, a high-speed search camera, and a galvano-mirror. In this system, the wide-angle camera offers panoramic images as prior information, which helps the search camera capture detailed images of the targeted objects. This integrated approach enhances the overall efficiency and effectiveness of wide-area visual detection systems. Specifically, in this study, we introduce a wide-angle camera-based method to generate a panoramic probability map (PPM) for estimating high-probability regions of target object presence. Then, we propose a probability searching module that uses the PPM-generated prior information to dynamically adjust the sampling range and refine target coordinates based on uncertainty variance computed by the object detector. Finally, the integration of PPM and the probability searching module yields an efficient hybrid vision system capable of achieving 120 fps multi-object search and detection. Extensive experiments are conducted to verify the system's effectiveness and robustness.
* Accepted by ICRA 2024
Cluster Regularized Quantization for Deep Networks Compression
Feb 27, 2019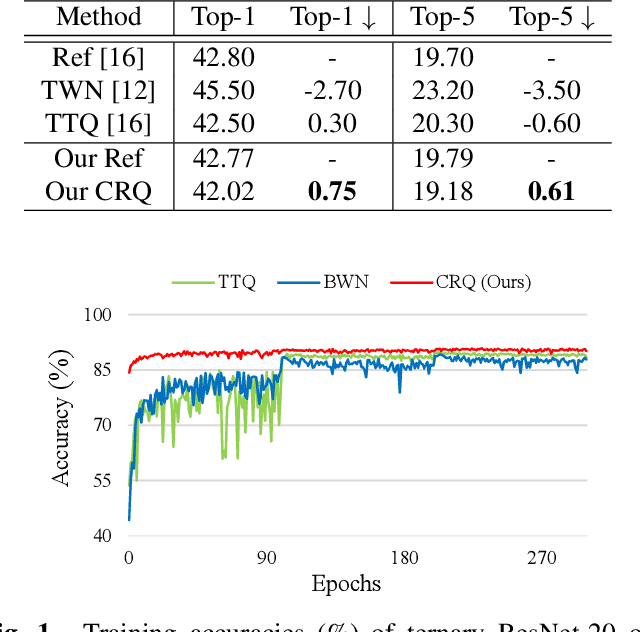


Deep neural networks (DNNs) have achieved great success in a wide range of computer vision areas, but the applications to mobile devices is limited due to their high storage and computational cost. Much efforts have been devoted to compress DNNs. In this paper, we propose a simple yet effective method for deep networks compression, named Cluster Regularized Quantization (CRQ), which can reduce the presentation precision of a full-precision model to ternary values without significant accuracy drop. In particular, the proposed method aims at reducing the quantization error by introducing a cluster regularization term, which is imposed on the full-precision weights to enable them naturally concentrate around the target values. Through explicitly regularizing the weights during the re-training stage, the full-precision model can achieve the smooth transition to the low-bit one. Comprehensive experiments on benchmark datasets demonstrate the effectiveness of the proposed method.