 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniDriveDreamer: A Single-Stage Multimodal World Model for Autonomous Driving
Feb 02, 2026World models have demonstrated significant promise for data synthesis in autonomous driving. However, existing methods predominantly concentrate on single-modality generation, typically focusing on either multi-camera video or LiDAR sequence synthesis. In this paper, we propose UniDriveDreamer, a single-stage unified multimodal world model for autonomous driving, which directly generates multimodal future observations without relying on intermediate representations or cascaded modules. Our framework introduces a LiDAR-specific variational autoencoder (VAE) designed to encode input LiDAR sequences, alongside a video VAE for multi-camera images. To ensure cross-modal compatibility and training stability, we propose Unified Latent Anchoring (ULA), which explicitly aligns the latent distributions of the two modalities. The aligned features are fused and processed by a diffusion transformer that jointly models their geometric correspondence and temporal evolution. Additionally, structured scene layout information is projected per modality as a conditioning signal to guide the synthesis. Extensive experiments demonstrate that UniDriveDreamer outperforms previous state-of-the-art methods in both video and LiDAR generation, while also yielding measurable improvements in downstream
MimicDreamer: Aligning Human and Robot Demonstrations for Scalable VLA Training
Sep 26, 2025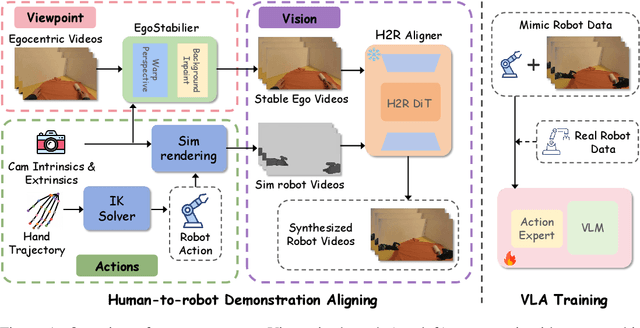

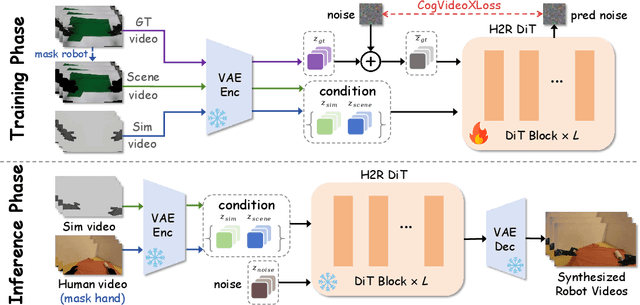
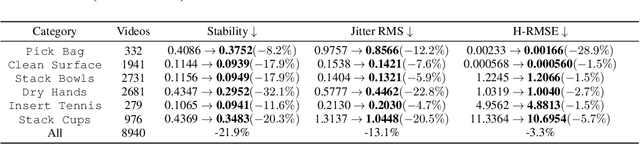
Vision Language Action (VLA) models derive their generalization capability from diverse training data, yet collecting embodied robot interaction data remains prohibitively expensive. In contrast, human demonstration videos are far more scalable and cost-efficient to collect, and recent studies confirm their effectiveness in training VLA models. However, a significant domain gap persists between human videos and robot-executed videos, including unstable camera viewpoints, visual discrepancies between human hands and robotic arms, and differences in motion dynamics. To bridge this gap, we propose MimicDreamer, a framework that turns fast, low-cost human demonstrations into robot-usable supervision by jointly aligning vision, viewpoint, and actions to directly support policy training. For visual alignment, we propose H2R Aligner, a video diffusion model that generates high-fidelity robot demonstration videos by transferring motion from human manipulation footage. For viewpoint stabilization, EgoStabilizer is proposed, which canonicalizes egocentric videos via homography and inpaints occlusions and distortions caused by warping. For action alignment, we map human hand trajectories to the robot frame and apply a constrained inverse kinematics solver to produce feasible, low-jitter joint commands with accurate pose tracking. Empirically, VLA models trained purely on our synthesized human-to-robot videos achieve few-shot execution on real robots. Moreover, scaling training with human data significantly boosts performance compared to models trained solely on real robot data; our approach improves the average success rate by 14.7\% across six representative manipulation tasks.
Deep Skin Lesion Segmentation with Transformer-CNN Fusion: Toward Intelligent Skin Cancer Analysis
Aug 20, 2025This paper proposes a high-precision semantic segmentation method based on an improved TransUNet architecture to address the challenges of complex lesion structures, blurred boundaries, and significant scale variations in skin lesion images. The method integrates a transformer module into the traditional encoder-decoder framework to model global semantic information, while retaining a convolutional branch to preserve local texture and edge features. This enhances the model's ability to perceive fine-grained structures. A boundary-guided attention mechanism and multi-scale upsampling path are also designed to improve lesion boundary localization and segmentation consistency. To verify the effectiveness of the approach, a series of experiments were conducted, including comparative studies, hyperparameter sensitivity analysis, data augmentation effects, input resolution variation, and training data split ratio tests. Experimental results show that the proposed model outperforms existing representative methods in mIoU, mDice, and mAcc, demonstrating stronger lesion recognition accuracy and robustness. In particular, the model achieves better boundary reconstruction and structural recovery in complex scenarios, making it well-suited for the key demands of automated segmentation tasks in skin lesion analysis.
Motion-R1: Chain-of-Thought Reasoning and Reinforcement Learning for Human Motion Generation
Jun 12, 2025Recent advances in large language models, especially in natural language understanding and reasoning, have opened new possibilities for text-to-motion generation. Although existing approaches have made notable progress in semantic alignment and motion synthesis, they often rely on end-to-end mapping strategies that fail to capture deep linguistic structures and logical reasoning. Consequently, generated motions tend to lack controllability, consistency, and diversity. To address these limitations, we propose Motion-R1, a unified motion-language modeling framework that integrates a Chain-of-Thought mechanism. By explicitly decomposing complex textual instructions into logically structured action paths, Motion-R1 provides high-level semantic guidance for motion generation, significantly enhancing the model's ability to interpret and execute multi-step, long-horizon, and compositionally rich commands. To train our model, we adopt Group Relative Policy Optimization, a reinforcement learning algorithm designed for large models, which leverages motion quality feedback to optimize reasoning chains and motion synthesis jointly. Extensive experiments across multiple benchmark datasets demonstrate that Motion-R1 achieves competitive or superior performance compared to state-of-the-art methods, particularly in scenarios requiring nuanced semantic understanding and long-term temporal coherence. The code, model and data will be publicly available.
GigaVideo-1: Advancing Video Generation via Automatic Feedback with 4 GPU-Hours Fine-Tuning
Jun 12, 2025
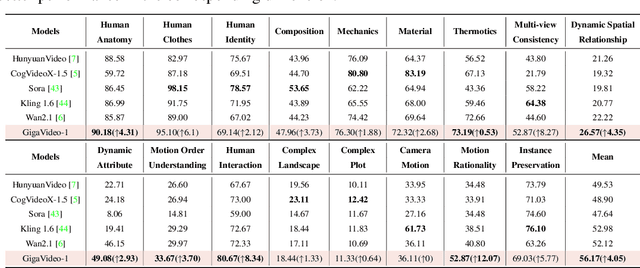
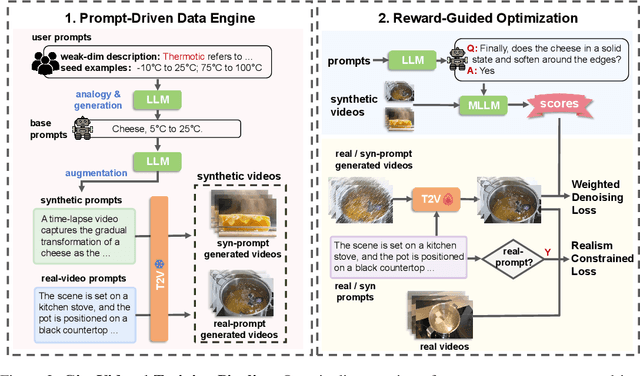

Recent progress in diffusion models has greatly enhanced video generation quality, yet these models still require fine-tuning to improve specific dimensions like instance preservation, motion rationality, composition, and physical plausibility. Existing fine-tuning approaches often rely on human annotations and large-scale computational resources, limiting their practicality. In this work, we propose GigaVideo-1, an efficient fine-tuning framework that advances video generation without additional human supervision. Rather than injecting large volumes of high-quality data from external sources, GigaVideo-1 unlocks the latent potential of pre-trained video diffusion models through automatic feedback. Specifically, we focus on two key aspects of the fine-tuning process: data and optimization. To improve fine-tuning data, we design a prompt-driven data engine that constructs diverse, weakness-oriented training samples. On the optimization side, we introduce a reward-guided training strategy, which adaptively weights samples using feedback from pre-trained vision-language models with a realism constraint. We evaluate GigaVideo-1 on the VBench-2.0 benchmark using Wan2.1 as the baseline across 17 evaluation dimensions. Experiments show that GigaVideo-1 consistently improves performance on almost all the dimensions with an average gain of about 4% using only 4 GPU-hours. Requiring no manual annotations and minimal real data, GigaVideo-1 demonstrates both effectiveness and efficiency. Code, model, and data will be publicly available.
Versatile Reservoir Computing for Heterogeneous Complex Networks
May 21, 2025A new machine learning scheme, termed versatile reservoir computing, is proposed for sustaining the dynamics of heterogeneous complex networks. We show that a single, small-scale reservoir computer trained on time series from a subset of elements is able to replicate the dynamics of any element in a large-scale complex network, though the elements are of different intrinsic parameters and connectivities. Furthermore, by substituting failed elements with the trained machine, we demonstrate that the collective dynamics of the network can be preserved accurately over a finite time horizon. The capability and effectiveness of the proposed scheme are validated on three representative network models: a homogeneous complex network of non-identical phase oscillators, a heterogeneous complex network of non-identical phase oscillators, and a heterogeneous complex network of non-identical chaotic oscillators.
HumanDreamer-X: Photorealistic Single-image Human Avatars Reconstruction via Gaussian Restoration
Apr 04, 2025
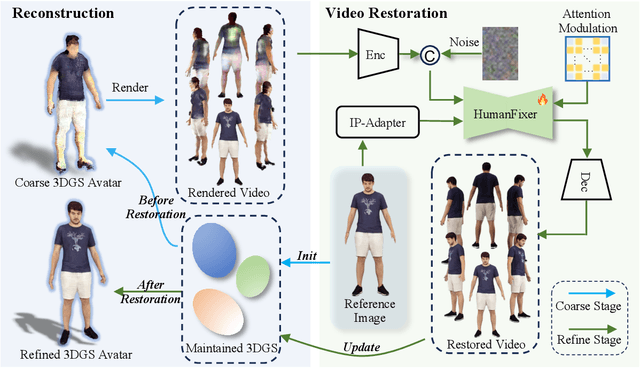

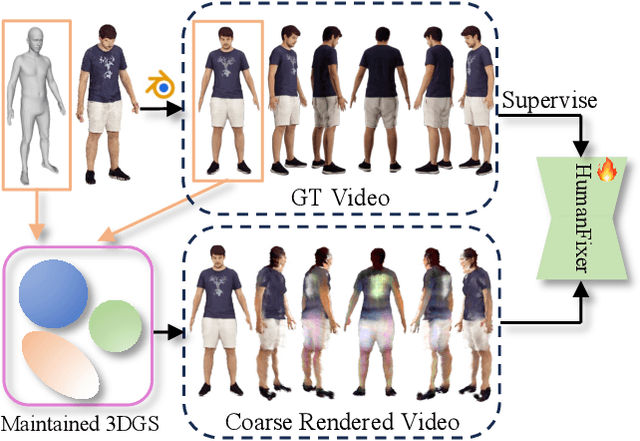
Single-image human reconstruction is vital for digital human modeling applications but remains an extremely challenging task. Current approaches rely on generative models to synthesize multi-view images for subsequent 3D reconstruction and animation. However, directly generating multiple views from a single human image suffers from geometric inconsistencies, resulting in issues like fragmented or blurred limbs in the reconstructed models. To tackle these limitations, we introduce \textbf{HumanDreamer-X}, a novel framework that integrates multi-view human generation and reconstruction into a unified pipeline, which significantly enhances the geometric consistency and visual fidelity of the reconstructed 3D models. In this framework, 3D Gaussian Splatting serves as an explicit 3D representation to provide initial geometry and appearance priority. Building upon this foundation, \textbf{HumanFixer} is trained to restore 3DGS renderings, which guarantee photorealistic results. Furthermore, we delve into the inherent challenges associated with attention mechanisms in multi-view human generation, and propose an attention modulation strategy that effectively enhances geometric details identity consistency across multi-view. Experimental results demonstrate that our approach markedly improves generation and reconstruction PSNR quality metrics by 16.45% and 12.65%, respectively, achieving a PSNR of up to 25.62 dB, while also showing generalization capabilities on in-the-wild data and applicability to various human reconstruction backbone models.
HumanDreamer: Generating Controllable Human-Motion Videos via Decoupled Generation
Apr 01, 2025Human-motion video generation has been a challenging task, primarily due to the difficulty inherent in learning human body movements. While some approaches have attempted to drive human-centric video generation explicitly through pose control, these methods typically rely on poses derived from existing videos, thereby lacking flexibility. To address this, we propose HumanDreamer, a decoupled human video generation framework that first generates diverse poses from text prompts and then leverages these poses to generate human-motion videos. Specifically, we propose MotionVid, the largest dataset for human-motion pose generation. Based on the dataset, we present MotionDiT, which is trained to generate structured human-motion poses from text prompts. Besides, a novel LAMA loss is introduced, which together contribute to a significant improvement in FID by 62.4%, along with respective enhancements in R-precision for top1, top2, and top3 by 41.8%, 26.3%, and 18.3%, thereby advancing both the Text-to-Pose control accuracy and FID metrics. Our experiments across various Pose-to-Video baselines demonstrate that the poses generated by our method can produce diverse and high-quality human-motion videos. Furthermore, our model can facilitate other downstream tasks, such as pose sequence prediction and 2D-3D motion lifting.
Bayesian Prompt Flow Learning for Zero-Shot Anomaly Detection
Mar 13, 2025Recently, vision-language models (e.g. CLIP) have demonstrated remarkable performance in zero-shot anomaly detection (ZSAD). By leveraging auxiliary data during training, these models can directly perform cross-category anomaly detection on target datasets, such as detecting defects on industrial product surfaces or identifying tumors in organ tissues. Existing approaches typically construct text prompts through either manual design or the optimization of learnable prompt vectors. However, these methods face several challenges: 1) handcrafted prompts require extensive expert knowledge and trial-and-error; 2) single-form learnable prompts struggle to capture complex anomaly semantics; and 3) an unconstrained prompt space limit generalization to unseen categories. To address these issues, we propose Bayesian Prompt Flow Learning (Bayes-PFL), which models the prompt space as a learnable probability distribution from a Bayesian perspective. Specifically, a prompt flow module is designed to learn both image-specific and image-agnostic distributions, which are jointly utilized to regularize the text prompt space and enhance the model's generalization on unseen categories. These learned distributions are then sampled to generate diverse text prompts, effectively covering the prompt space. Additionally, a residual cross-attention (RCA) module is introduced to better align dynamic text embeddings with fine-grained image features. Extensive experiments on 15 industrial and medical datasets demonstrate our method's superior performance.
Rethinking Lanes and Points in Complex Scenarios for Monocular 3D Lane Detection
Mar 08, 2025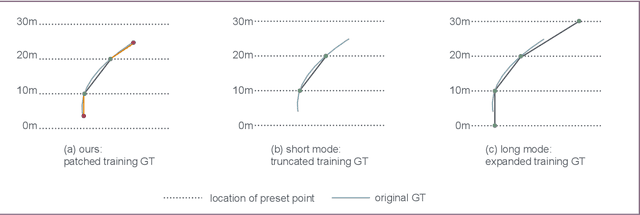
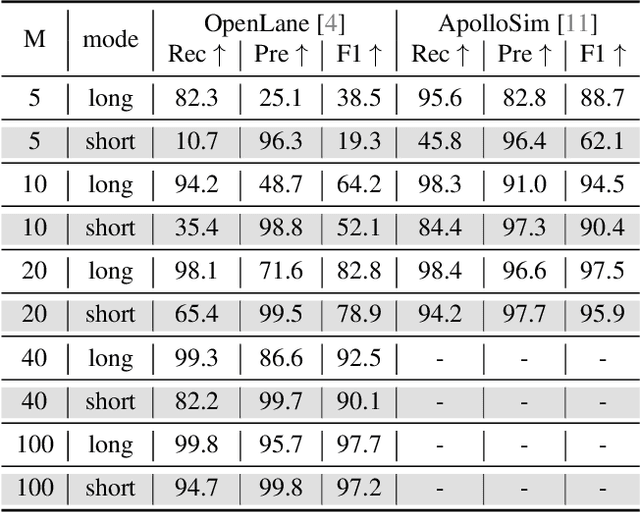
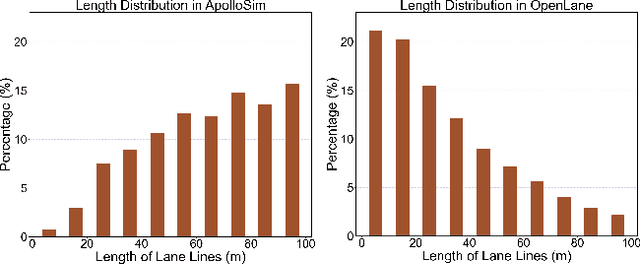
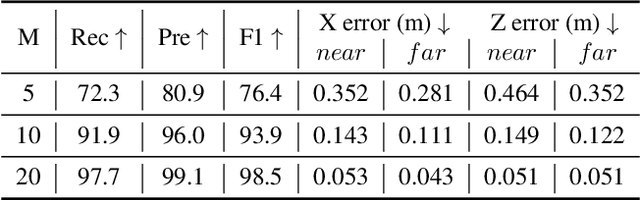
Monocular 3D lane detection is a fundamental task in autonomous driving. Although sparse-point methods lower computational load and maintain high accuracy in complex lane geometries, current methods fail to fully leverage the geometric structure of lanes in both lane geometry representations and model design. In lane geometry representations, we present a theoretical analysis alongside experimental validation to verify that current sparse lane representation methods contain inherent flaws, resulting in potential errors of up to 20 m, which raise significant safety concerns for driving. To address this issue, we propose a novel patching strategy to completely represent the full lane structure. To enable existing models to match this strategy, we introduce the EndPoint head (EP-head), which adds a patching distance to endpoints. The EP-head enables the model to predict more complete lane representations even with fewer preset points, effectively addressing existing limitations and paving the way for models that are faster and require fewer parameters in the future. In model design, to enhance the model's perception of lane structures, we propose the PointLane attention (PL-attention), which incorporates prior geometric knowledge into the attention mechanism. Extensive experiments demonstrate the effectiveness of the proposed methods on various state-of-the-art models. For instance, in terms of the overall F1-score, our methods improve Persformer by 4.4 points, Anchor3DLane by 3.2 points, and LATR by 2.8 points. The code will be available soon.