 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreetForward: Perceiving Dynamic Street with Feedforward Causal Attention
Mar 20, 2026Feedforward reconstruction is crucial for autonomous driving applications, where rapid scene reconstruction enables efficient utilization of large-scale driving datasets in closed-loop simulation and other downstream tasks, eliminating the need for time-consuming per-scene optimization. We present StreetForward, a pose-free and tracker-free feedforward framework for dynamic street reconstruction. Building upon the alternating attention mechanism from Visual Geometry Grounded Transformer (VGGT), we propose a simple yet effective temporal mask attention module that captures dynamic motion information from image sequences and produces motion-aware latent representations. Static content and dynamic instances are represented uniformly with 3D Gaussian Splatting, and are optimized jointly by cross-frame rendering with spatio-temporal consistency, allowing the model to infer per-pixel velocities and produce high-fidelity novel views at new poses and times. We train and evaluate our model on the Waymo Open Dataset, demonstrating superior performance on novel view synthesis and depth estimation compared to existing methods. Furthermore, zero-shot inference on CARLA and other datasets validates the generalization capability of our approach. More visualizations are available on our project page: https://streetforward.github.io.
DriveCombo: Benchmarking Compositional Traffic Rule Reasoning in Autonomous Driving
Mar 02, 2026Multimodal Large Language Models (MLLMs) are rapidly becoming the intelligence brain of end-to-end autonomous driving systems. A key challenge is to assess whether MLLMs can truly understand and follow complex real-world traffic rules. However, existing benchmarks mainly focus on single-rule scenarios like traffic sign recognition, neglecting the complexity of multi-rule concurrency and conflicts in real driving. Consequently, models perform well on simple tasks but often fail or violate rules in real world complex situations. To bridge this gap, we propose DriveCombo, a text and vision-based benchmark for compositional traffic rule reasoning. Inspired by human drivers' cognitive development, we propose a systematic Five-Level Cognitive Ladder that evaluates reasoning from single-rule understanding to multi-rule integration and conflict resolution, enabling quantitative assessment across cognitive stages. We further propose a Rule2Scene Agent that maps language-based traffic rules to dynamic driving scenes through rule crafting and scene generation, enabling scene-level traffic rule visual reasoning. Evaluations of 14 mainstream MLLMs reveal performance drops as task complexity grows, particularly during rule conflicts. After splitting the dataset and fine-tuning on the training set, we further observe substantial improvements in both traffic rule reasoning and downstream planning capabilities. These results highlight the effectiveness of DriveCombo in advancing compliant and intelligent autonomous driving systems.
InfiniDepth: Arbitrary-Resolution and Fine-Grained Depth Estimation with Neural Implicit Fields
Jan 06, 2026Existing depth estimation methods are fundamentally limited to predicting depth on discrete image grids. Such representations restrict their scalability to arbitrary output resolutions and hinder the geometric detail recovery. This paper introduces InfiniDepth, which represents depth as neural implicit fields. Through a simple yet effective local implicit decoder, we can query depth at continuous 2D coordinates, enabling arbitrary-resolution and fine-grained depth estimation. To better assess our method's capabilities, we curate a high-quality 4K synthetic benchmark from five different games, spanning diverse scenes with rich geometric and appearance details. Extensive experiments demonstrate that InfiniDepth achieves state-of-the-art performance on both synthetic and real-world benchmarks across relative and metric depth estimation tasks, particularly excelling in fine-detail regions. It also benefits the task of novel view synthesis under large viewpoint shifts, producing high-quality results with fewer holes and artifacts.
OmniGen: Unified Multimodal Sensor Generation for Autonomous Driving
Dec 16, 2025Autonomous driving has seen remarkable advancements, largely driven by extensive real-world data collection. However, acquiring diverse and corner-case data remains costly and inefficient. Generative models have emerged as a promising solution by synthesizing realistic sensor data. However, existing approaches primarily focus on single-modality generation, leading to inefficiencies and misalignment in multimodal sensor data. To address these challenges, we propose OminiGen, which generates aligned multimodal sensor data in a unified framework. Our approach leverages a shared Bird\u2019s Eye View (BEV) space to unify multimodal features and designs a novel generalizable multimodal reconstruction method, UAE, to jointly decode LiDAR and multi-view camera data. UAE achieves multimodal sensor decoding through volume rendering, enabling accurate and flexible reconstruction. Furthermore, we incorporate a Diffusion Transformer (DiT) with a ControlNet branch to enable controllable multimodal sensor generation. Our comprehensive experiments demonstrate that OminiGen achieves desired performances in unified multimodal sensor data generation with multimodal consistency and flexible sensor adjustments.
CorrectAD: A Self-Correcting Agentic System to Improve End-to-end Planning in Autonomous Driving
Nov 17, 2025End-to-end planning methods are the de facto standard of the current autonomous driving system, while the robustness of the data-driven approaches suffers due to the notorious long-tail problem (i.e., rare but safety-critical failure cases). In this work, we explore whether recent diffusion-based video generation methods (a.k.a. world models), paired with structured 3D layouts, can enable a fully automated pipeline to self-correct such failure cases. We first introduce an agent to simulate the role of product manager, dubbed PM-Agent, which formulates data requirements to collect data similar to the failure cases. Then, we use a generative model that can simulate both data collection and annotation. However, existing generative models struggle to generate high-fidelity data conditioned on 3D layouts. To address this, we propose DriveSora, which can generate spatiotemporally consistent videos aligned with the 3D annotations requested by PM-Agent. We integrate these components into our self-correcting agentic system, CorrectAD. Importantly, our pipeline is an end-to-end model-agnostic and can be applied to improve any end-to-end planner. Evaluated on both nuScenes and a more challenging in-house dataset across multiple end-to-end planners, CorrectAD corrects 62.5% and 49.8% of failure cases, reducing collision rates by 39% and 27%, respectively.
DriveLiDAR4D: Sequential and Controllable LiDAR Scene Generation for Autonomous Driving
Nov 17, 2025The generation of realistic LiDAR point clouds plays a crucial role in the development and evaluation of autonomous driving systems. Although recent methods for 3D LiDAR point cloud generation have shown significant improvements, they still face notable limitations, including the lack of sequential generation capabilities and the inability to produce accurately positioned foreground objects and realistic backgrounds. These shortcomings hinder their practical applicability. In this paper, we introduce DriveLiDAR4D, a novel LiDAR generation pipeline consisting of multimodal conditions and a novel sequential noise prediction model LiDAR4DNet, capable of producing temporally consistent LiDAR scenes with highly controllable foreground objects and realistic backgrounds. To the best of our knowledge, this is the first work to address the sequential generation of LiDAR scenes with full scene manipulation capability in an end-to-end manner. We evaluated DriveLiDAR4D on the nuScenes and KITTI datasets, where we achieved an FRD score of 743.13 and an FVD score of 16.96 on the nuScenes dataset, surpassing the current state-of-the-art (SOTA) method, UniScene, with an performance boost of 37.2% in FRD and 24.1% in FVD, respectively.
GeoDrive: 3D Geometry-Informed Driving World Model with Precise Action Control
May 29, 2025Recent advancements in world models have revolutionized dynamic environment simulation, allowing systems to foresee future states and assess potential actions. In autonomous driving, these capabilities help vehicles anticipate the behavior of other road users, perform risk-aware planning, accelerate training in simulation, and adapt to novel scenarios, thereby enhancing safety and reliability. Current approaches exhibit deficiencies in maintaining robust 3D geometric consistency or accumulating artifacts during occlusion handling, both critical for reliable safety assessment in autonomous navigation tasks. To address this, we introduce GeoDrive, which explicitly integrates robust 3D geometry conditions into driving world models to enhance spatial understanding and action controllability. Specifically, we first extract a 3D representation from the input frame and then obtain its 2D rendering based on the user-specified ego-car trajectory. To enable dynamic modeling, we propose a dynamic editing module during training to enhance the renderings by editing the positions of the vehicles. Extensive experiments demonstrate that our method significantly outperforms existing models in both action accuracy and 3D spatial awareness, leading to more realistic, adaptable, and reliable scene modeling for safer autonomous driving. Additionally, our model can generalize to novel trajectories and offers interactive scene editing capabilities, such as object editing and object trajectory control.
PosePilot: Steering Camera Pose for Generative World Models with Self-supervised Depth
May 03, 2025Recent advancements in autonomous driving (AD) systems have highlighted the potential of world models in achieving robust and generalizable performance across both ordinary and challenging driving conditions. However, a key challenge remains: precise and flexible camera pose control, which is crucial for accurate viewpoint transformation and realistic simulation of scene dynamics. In this paper, we introduce PosePilot, a lightweight yet powerful framework that significantly enhances camera pose controllability in generative world models. Drawing inspiration from self-supervised depth estimation, PosePilot leverages structure-from-motion principles to establish a tight coupling between camera pose and video generation. Specifically, we incorporate self-supervised depth and pose readouts, allowing the model to infer depth and relative camera motion directly from video sequences. These outputs drive pose-aware frame warping, guided by a photometric warping loss that enforces geometric consistency across synthesized frames. To further refine camera pose estimation, we introduce a reverse warping step and a pose regression loss, improving viewpoint precision and adaptability. Extensive experiments on autonomous driving and general-domain video datasets demonstrate that PosePilot significantly enhances structural understanding and motion reasoning in both diffusion-based and auto-regressive world models. By steering camera pose with self-supervised depth, PosePilot sets a new benchmark for pose controllability, enabling physically consistent, reliable viewpoint synthesis in generative world models.
StyledStreets: Multi-style Street Simulator with Spatial and Temporal Consistency
Mar 27, 2025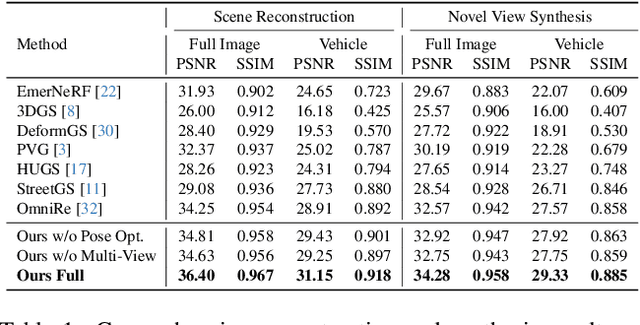

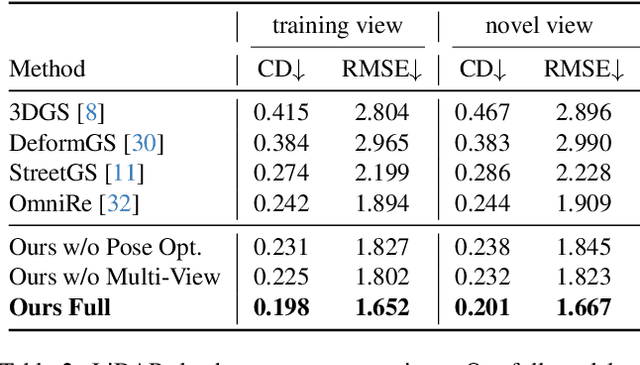
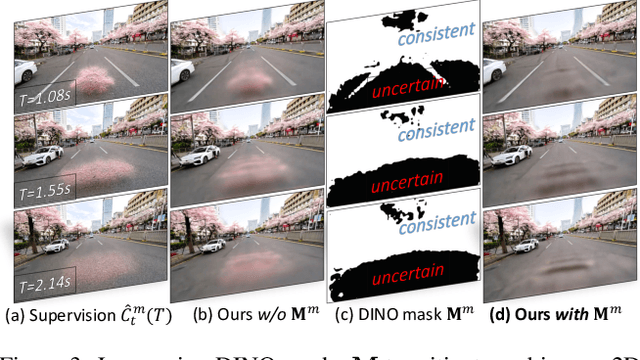
Urban scene reconstruction requires modeling both static infrastructure and dynamic elements while supporting diverse environmental conditions. We present \textbf{StyledStreets}, a multi-style street simulator that achieves instruction-driven scene editing with guaranteed spatial and temporal consistency. Building on a state-of-the-art Gaussian Splatting framework for street scenarios enhanced by our proposed pose optimization and multi-view training, our method enables photorealistic style transfers across seasons, weather conditions, and camera setups through three key innovations: First, a hybrid embedding scheme disentangles persistent scene geometry from transient style attributes, allowing realistic environmental edits while preserving structural integrity. Second, uncertainty-aware rendering mitigates supervision noise from diffusion priors, enabling robust training across extreme style variations. Third, a unified parametric model prevents geometric drift through regularized updates, maintaining multi-view consistency across seven vehicle-mounted cameras. Our framework preserves the original scene's motion patterns and geometric relationships. Qualitative results demonstrate plausible transitions between diverse conditions (snow, sandstorm, night), while quantitative evaluations show state-of-the-art geometric accuracy under style transfers. The approach establishes new capabilities for urban simulation, with applications in autonomous vehicle testing and augmented reality systems requiring reliable environmental consistency. Codes will be publicly available upon publication.
ReconDreamer: Crafting World Models for Driving Scene Reconstruction via Online Restoration
Nov 29, 2024



Closed-loop simulation is crucial for end-to-end autonomous driving. Existing sensor simulation methods (e.g., NeRF and 3DGS) reconstruct driving scenes based on conditions that closely mirror training data distributions. However, these methods struggle with rendering novel trajectories, such as lane changes. Recent works have demonstrated that integrating world model knowledge alleviates these issues. Despite their efficiency, these approaches still encounter difficulties in the accurate representation of more complex maneuvers, with multi-lane shifts being a notable example. Therefore, we introduce ReconDreamer, which enhances driving scene reconstruction through incremental integration of world model knowledge. Specifically, DriveRestorer is proposed to mitigate artifacts via online restoration. This is complemented by a progressive data update strategy designed to ensure high-quality rendering for more complex maneuvers. To the best of our knowledge, ReconDreamer is the first method to effectively render in large maneuvers. Experimental results demonstrate that ReconDreamer outperforms Street Gaussians in the NTA-IoU, NTL-IoU, and FID, with relative improvements by 24.87%, 6.72%, and 29.97%. Furthermore, ReconDreamer surpasses DriveDreamer4D with PVG during large maneuver rendering, as verified by a relative improvement of 195.87% in the NTA-IoU metric and a comprehensive user study.