 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Pruning of Recurrent Neural Networks through Neuron Selection
Jun 17, 2019
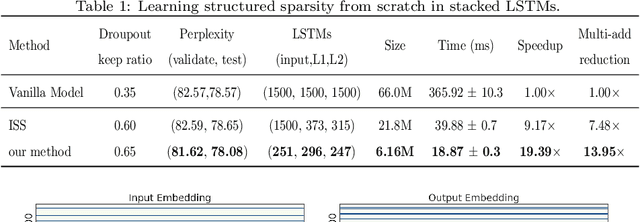

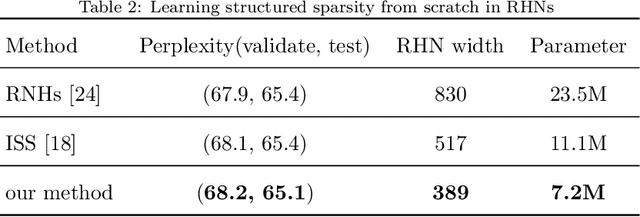
Recurrent neural networks (RNNs) have recently achieved remarkable successes in a number of applications. However, the huge sizes and computational burden of these models make it difficult for their deployment on edge devices. A practically effective approach is to reduce the overall storage and computation costs of RNNs by network pruning techniques. Despite their successful applications, those pruning methods based on Lasso either produce irregular sparse patterns in weight matrices, which is not helpful in practical speedup. To address these issues, we propose structured pruning method through neuron selection which can reduce the sizes of basic structures of RNNs. More specifically, we introduce two sets of binary random variables, which can be interpreted as gates or switches to the input neurons and the hidden neurons, respectively. We demonstrate that the corresponding optimization problem can be addressed by minimizing the L0 norm of the weight matrix. Finally, experimental results on language modeling and machine reading comprehension tasks have indicated the advantages of the proposed method in comparison with state-of-the-art pruning competitors. In particular, nearly 20 x practical speedup during inference was achieved without losing performance for language model on the Penn TreeBank dataset, indicating the promising performance of the proposed method