 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveLiDAR4D: Sequential and Controllable LiDAR Scene Generation for Autonomous Driving
Nov 17, 2025The generation of realistic LiDAR point clouds plays a crucial role in the development and evaluation of autonomous driving systems. Although recent methods for 3D LiDAR point cloud generation have shown significant improvements, they still face notable limitations, including the lack of sequential generation capabilities and the inability to produce accurately positioned foreground objects and realistic backgrounds. These shortcomings hinder their practical applicability. In this paper, we introduce DriveLiDAR4D, a novel LiDAR generation pipeline consisting of multimodal conditions and a novel sequential noise prediction model LiDAR4DNet, capable of producing temporally consistent LiDAR scenes with highly controllable foreground objects and realistic backgrounds. To the best of our knowledge, this is the first work to address the sequential generation of LiDAR scenes with full scene manipulation capability in an end-to-end manner. We evaluated DriveLiDAR4D on the nuScenes and KITTI datasets, where we achieved an FRD score of 743.13 and an FVD score of 16.96 on the nuScenes dataset, surpassing the current state-of-the-art (SOTA) method, UniScene, with an performance boost of 37.2% in FRD and 24.1% in FVD, respectively.
PosePilot: Steering Camera Pose for Generative World Models with Self-supervised Depth
May 03, 2025Recent advancements in autonomous driving (AD) systems have highlighted the potential of world models in achieving robust and generalizable performance across both ordinary and challenging driving conditions. However, a key challenge remains: precise and flexible camera pose control, which is crucial for accurate viewpoint transformation and realistic simulation of scene dynamics. In this paper, we introduce PosePilot, a lightweight yet powerful framework that significantly enhances camera pose controllability in generative world models. Drawing inspiration from self-supervised depth estimation, PosePilot leverages structure-from-motion principles to establish a tight coupling between camera pose and video generation. Specifically, we incorporate self-supervised depth and pose readouts, allowing the model to infer depth and relative camera motion directly from video sequences. These outputs drive pose-aware frame warping, guided by a photometric warping loss that enforces geometric consistency across synthesized frames. To further refine camera pose estimation, we introduce a reverse warping step and a pose regression loss, improving viewpoint precision and adaptability. Extensive experiments on autonomous driving and general-domain video datasets demonstrate that PosePilot significantly enhances structural understanding and motion reasoning in both diffusion-based and auto-regressive world models. By steering camera pose with self-supervised depth, PosePilot sets a new benchmark for pose controllability, enabling physically consistent, reliable viewpoint synthesis in generative world models.
DiVE: Efficient Multi-View Driving Scenes Generation Based on Video Diffusion Transformer
Apr 28, 2025



Collecting multi-view driving scenario videos to enhance the performance of 3D visual perception tasks presents significant challenges and incurs substantial costs, making generative models for realistic data an appealing alternative. Yet, the videos generated by recent works suffer from poor quality and spatiotemporal consistency, undermining their utility in advancing perception tasks under driving scenarios. To address this gap, we propose DiVE, a diffusion transformer-based generative framework meticulously engineered to produce high-fidelity, temporally coherent, and cross-view consistent multi-view videos, aligning seamlessly with bird's-eye view layouts and textual descriptions. DiVE leverages a unified cross-attention and a SketchFormer to exert precise control over multimodal data, while incorporating a view-inflated attention mechanism that adds no extra parameters, thereby guaranteeing consistency across views. Despite these advancements, synthesizing high-resolution videos under multimodal constraints introduces dual challenges: investigating the optimal classifier-free guidance coniguration under intricate multi-condition inputs and mitigating excessive computational latency in high-resolution rendering--both of which remain underexplored in prior researches. To resolve these limitations, we introduce two innovations: Multi-Control Auxiliary Branch Distillation, which streamlines multi-condition CFG selection while circumventing high computational overhead, and Resolution Progressive Sampling, a training-free acceleration strategy that staggers resolution scaling to reduce high latency due to high resolution. These innovations collectively achieve a 2.62x speedup with minimal quality degradation. Evaluated on the nuScenes dataset, DiVE achieves SOTA performance in multi-view video generation, yielding photorealistic outputs with exceptional temporal and cross-view coherence.
DiVE: DiT-based Video Generation with Enhanced Control
Sep 03, 2024



Generating high-fidelity, temporally consistent videos in autonomous driving scenarios faces a significant challenge, e.g. problematic maneuvers in corner cases. Despite recent video generation works are proposed to tackcle the mentioned problem, i.e. models built on top of Diffusion Transformers (DiT), works are still missing which are targeted on exploring the potential for multi-view videos generation scenarios. Noticeably, we propose the first DiT-based framework specifically designed for generating temporally and multi-view consistent videos which precisely match the given bird's-eye view layouts control. Specifically, the proposed framework leverages a parameter-free spatial view-inflated attention mechanism to guarantee the cross-view consistency, where joint cross-attention modules and ControlNet-Transformer are integrated to further improve the precision of control. To demonstrate our advantages, we extensively investigate the qualitative comparisons on nuScenes dataset, particularly in some most challenging corner cases. In summary, the effectiveness of our proposed method in producing long, controllable, and highly consistent videos under difficult conditions is proven to be effective.
One-bit Supervision for Image Classification: Problem, Solution, and Beyond
Nov 26, 2023This paper presents one-bit supervision, a novel setting of learning with fewer labels, for image classification. Instead of training model using the accurate label of each sample, our setting requires the model to interact with the system by predicting the class label of each sample and learn from the answer whether the guess is correct, which provides one bit (yes or no) of information. An intriguing property of the setting is that the burden of annotation largely alleviates in comparison to offering the accurate label. There are two keys to one-bit supervision, which are (i) improving the guess accuracy and (ii) making good use of the incorrect guesses. To achieve these goals, we propose a multi-stage training paradigm and incorporate negative label suppression into an off-the-shelf semi-supervised learning algorithm. Theoretical analysis shows that one-bit annotation is more efficient than full-bit annotation in most cases and gives the conditions of combining our approach with active learning. Inspired by this, we further integrate the one-bit supervision framework into the self-supervised learning algorithm which yields an even more efficient training schedule. Different from training from scratch, when self-supervised learning is used for initialization, both hard example mining and class balance are verified effective in boosting the learning performance. However, these two frameworks still need full-bit labels in the initial stage. To cast off this burden, we utilize unsupervised domain adaptation to train the initial model and conduct pure one-bit annotations on the target dataset. In multiple benchmarks, the learning efficiency of the proposed approach surpasses that using full-bit, semi-supervised supervision.
Domain-Agnostic Prior for Transfer Semantic Segmentation
Apr 20, 2022
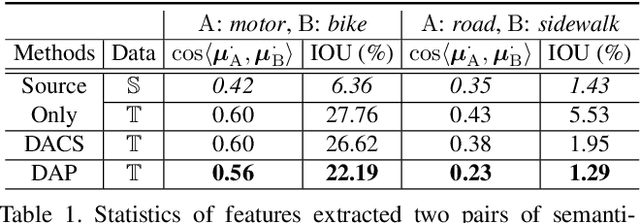
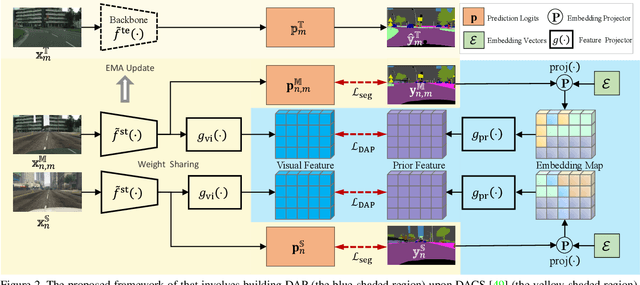
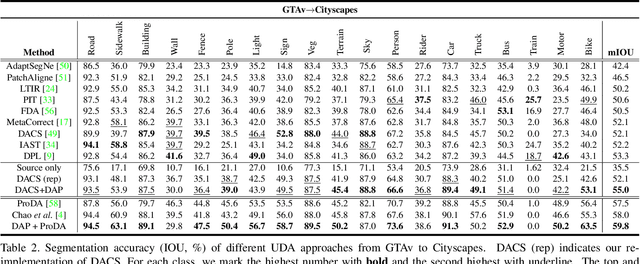
Unsupervised domain adaptation (UDA) is an important topic in the computer vision community. The key difficulty lies in defining a common property between the source and target domains so that the source-domain features can align with the target-domain semantics. In this paper, we present a simple and effective mechanism that regularizes cross-domain representation learning with a domain-agnostic prior (DAP) that constrains the features extracted from source and target domains to align with a domain-agnostic space. In practice, this is easily implemented as an extra loss term that requires a little extra costs. In the standard evaluation protocol of transferring synthesized data to real data, we validate the effectiveness of different types of DAP, especially that borrowed from a text embedding model that shows favorable performance beyond the state-of-the-art UDA approaches in terms of segmentation accuracy. Our research reveals that UDA benefits much from better proxies, possibly from other data modalities.
One-bit Supervision for Image Classification
Sep 16, 2020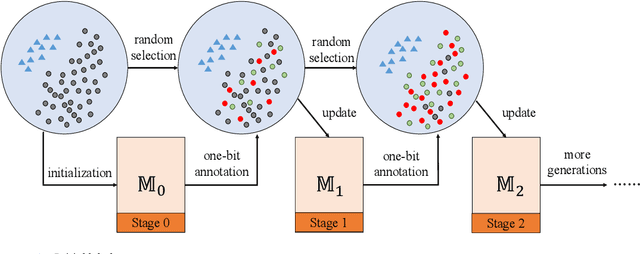

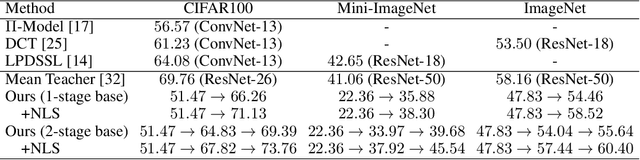

This paper presents one-bit supervision, a novel setting of learning from incomplete annotations, in the scenario of image classification. Instead of training a model upon the accurate label of each sample, our setting requires the model to query with a predicted label of each sample and learn from the answer whether the guess is correct. This provides one bit (yes or no) of information, and more importantly, annotating each sample becomes much easier than finding the accurate label from many candidate classes. There are two keys to training a model upon one-bit supervision: improving the guess accuracy and making use of incorrect guesses. For these purposes, we propose a multi-stage training paradigm which incorporates negative label suppression into an off-the-shelf semi-supervised learning algorithm. In three popular image classification benchmarks, our approach claims higher efficiency in utilizing the limited amount of annotations.
Creating Something from Nothing: Unsupervised Knowledge Distillation for Cross-Modal Hashing
Apr 01, 2020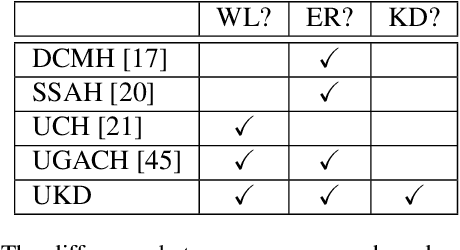
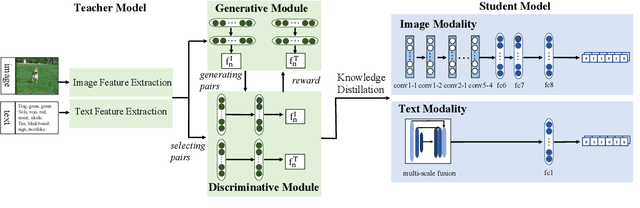
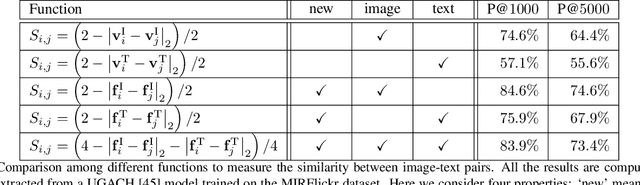

In recent years, cross-modal hashing (CMH) has attracted increasing attentions, mainly because its potential ability of mapping contents from different modalities, especially in vision and language, into the same space, so that it becomes efficient in cross-modal data retrieval. There are two main frameworks for CMH, differing from each other in whether semantic supervision is required. Compared to the unsupervised methods, the supervised methods often enjoy more accurate results, but require much heavier labors in data annotation. In this paper, we propose a novel approach that enables guiding a supervised method using outputs produced by an unsupervised method. Specifically, we make use of teacher-student optimization for propagating knowledge. Experiments are performed on two popular CMH benchmarks, i.e., the MIRFlickr and NUS-WIDE datasets. Our approach outperforms all existing unsupervised methods by a large margin.