 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-Bridge: Bridging Video Generative Priors to Versatile Few-shot Image Restoration
Mar 13, 2026Large-scale video generative models are trained on vast and diverse visual data, enabling them to internalize rich structural, semantic, and dynamic priors of the visual world. While these models have demonstrated impressive generative capability, their potential as general-purpose visual learners remains largely untapped. In this work, we introduce V-Bridge, a framework that bridges this latent capacity to versatile few-shot image restoration tasks. We reinterpret image restoration not as a static regression problem, but as a progressive generative process, and leverage video models to simulate the gradual refinement from degraded inputs to high-fidelity outputs. Surprisingly, with only 1,000 multi-task training samples (less than 2% of existing restoration methods), pretrained video models can be induced to perform competitive image restoration, achieving multiple tasks with a single model, rivaling specialized architectures designed explicitly for this purpose. Our findings reveal that video generative models implicitly learn powerful and transferable restoration priors that can be activated with only extremely limited data, challenging the traditional boundary between generative modeling and low-level vision, and opening a new design paradigm for foundation models in visual tasks.
CorrectAD: A Self-Correcting Agentic System to Improve End-to-end Planning in Autonomous Driving
Nov 17, 2025End-to-end planning methods are the de facto standard of the current autonomous driving system, while the robustness of the data-driven approaches suffers due to the notorious long-tail problem (i.e., rare but safety-critical failure cases). In this work, we explore whether recent diffusion-based video generation methods (a.k.a. world models), paired with structured 3D layouts, can enable a fully automated pipeline to self-correct such failure cases. We first introduce an agent to simulate the role of product manager, dubbed PM-Agent, which formulates data requirements to collect data similar to the failure cases. Then, we use a generative model that can simulate both data collection and annotation. However, existing generative models struggle to generate high-fidelity data conditioned on 3D layouts. To address this, we propose DriveSora, which can generate spatiotemporally consistent videos aligned with the 3D annotations requested by PM-Agent. We integrate these components into our self-correcting agentic system, CorrectAD. Importantly, our pipeline is an end-to-end model-agnostic and can be applied to improve any end-to-end planner. Evaluated on both nuScenes and a more challenging in-house dataset across multiple end-to-end planners, CorrectAD corrects 62.5% and 49.8% of failure cases, reducing collision rates by 39% and 27%, respectively.
PosePilot: Steering Camera Pose for Generative World Models with Self-supervised Depth
May 03, 2025Recent advancements in autonomous driving (AD) systems have highlighted the potential of world models in achieving robust and generalizable performance across both ordinary and challenging driving conditions. However, a key challenge remains: precise and flexible camera pose control, which is crucial for accurate viewpoint transformation and realistic simulation of scene dynamics. In this paper, we introduce PosePilot, a lightweight yet powerful framework that significantly enhances camera pose controllability in generative world models. Drawing inspiration from self-supervised depth estimation, PosePilot leverages structure-from-motion principles to establish a tight coupling between camera pose and video generation. Specifically, we incorporate self-supervised depth and pose readouts, allowing the model to infer depth and relative camera motion directly from video sequences. These outputs drive pose-aware frame warping, guided by a photometric warping loss that enforces geometric consistency across synthesized frames. To further refine camera pose estimation, we introduce a reverse warping step and a pose regression loss, improving viewpoint precision and adaptability. Extensive experiments on autonomous driving and general-domain video datasets demonstrate that PosePilot significantly enhances structural understanding and motion reasoning in both diffusion-based and auto-regressive world models. By steering camera pose with self-supervised depth, PosePilot sets a new benchmark for pose controllability, enabling physically consistent, reliable viewpoint synthesis in generative world models.
DiVE: Efficient Multi-View Driving Scenes Generation Based on Video Diffusion Transformer
Apr 28, 2025



Collecting multi-view driving scenario videos to enhance the performance of 3D visual perception tasks presents significant challenges and incurs substantial costs, making generative models for realistic data an appealing alternative. Yet, the videos generated by recent works suffer from poor quality and spatiotemporal consistency, undermining their utility in advancing perception tasks under driving scenarios. To address this gap, we propose DiVE, a diffusion transformer-based generative framework meticulously engineered to produce high-fidelity, temporally coherent, and cross-view consistent multi-view videos, aligning seamlessly with bird's-eye view layouts and textual descriptions. DiVE leverages a unified cross-attention and a SketchFormer to exert precise control over multimodal data, while incorporating a view-inflated attention mechanism that adds no extra parameters, thereby guaranteeing consistency across views. Despite these advancements, synthesizing high-resolution videos under multimodal constraints introduces dual challenges: investigating the optimal classifier-free guidance coniguration under intricate multi-condition inputs and mitigating excessive computational latency in high-resolution rendering--both of which remain underexplored in prior researches. To resolve these limitations, we introduce two innovations: Multi-Control Auxiliary Branch Distillation, which streamlines multi-condition CFG selection while circumventing high computational overhead, and Resolution Progressive Sampling, a training-free acceleration strategy that staggers resolution scaling to reduce high latency due to high resolution. These innovations collectively achieve a 2.62x speedup with minimal quality degradation. Evaluated on the nuScenes dataset, DiVE achieves SOTA performance in multi-view video generation, yielding photorealistic outputs with exceptional temporal and cross-view coherence.
DrivingSphere: Building a High-fidelity 4D World for Closed-loop Simulation
Nov 18, 2024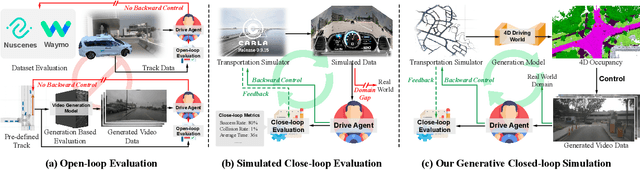
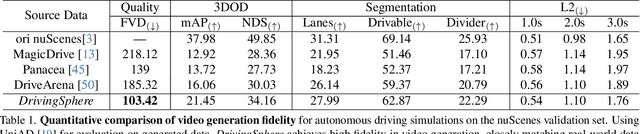
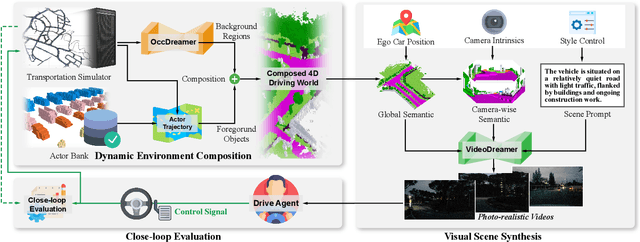

Autonomous driving evaluation requires simulation environments that closely replicate actual road conditions, including real-world sensory data and responsive feedback loops. However, many existing simulations need to predict waypoints along fixed routes on public datasets or synthetic photorealistic data, \ie, open-loop simulation usually lacks the ability to assess dynamic decision-making. While the recent efforts of closed-loop simulation offer feedback-driven environments, they cannot process visual sensor inputs or produce outputs that differ from real-world data. To address these challenges, we propose DrivingSphere, a realistic and closed-loop simulation framework. Its core idea is to build 4D world representation and generate real-life and controllable driving scenarios. In specific, our framework includes a Dynamic Environment Composition module that constructs a detailed 4D driving world with a format of occupancy equipping with static backgrounds and dynamic objects, and a Visual Scene Synthesis module that transforms this data into high-fidelity, multi-view video outputs, ensuring spatial and temporal consistency. By providing a dynamic and realistic simulation environment, DrivingSphere enables comprehensive testing and validation of autonomous driving algorithms, ultimately advancing the development of more reliable autonomous cars. The benchmark will be publicly released.
DiVE: DiT-based Video Generation with Enhanced Control
Sep 03, 2024



Generating high-fidelity, temporally consistent videos in autonomous driving scenarios faces a significant challenge, e.g. problematic maneuvers in corner cases. Despite recent video generation works are proposed to tackcle the mentioned problem, i.e. models built on top of Diffusion Transformers (DiT), works are still missing which are targeted on exploring the potential for multi-view videos generation scenarios. Noticeably, we propose the first DiT-based framework specifically designed for generating temporally and multi-view consistent videos which precisely match the given bird's-eye view layouts control. Specifically, the proposed framework leverages a parameter-free spatial view-inflated attention mechanism to guarantee the cross-view consistency, where joint cross-attention modules and ControlNet-Transformer are integrated to further improve the precision of control. To demonstrate our advantages, we extensively investigate the qualitative comparisons on nuScenes dataset, particularly in some most challenging corner cases. In summary, the effectiveness of our proposed method in producing long, controllable, and highly consistent videos under difficult conditions is proven to be effective.
Unleashing Generalization of End-to-End Autonomous Driving with Controllable Long Video Generation
Jun 03, 2024Using generative models to synthesize new data has become a de-facto standard in autonomous driving to address the data scarcity issue. Though existing approaches are able to boost perception models, we discover that these approaches fail to improve the performance of planning of end-to-end autonomous driving models as the generated videos are usually less than 8 frames and the spatial and temporal inconsistencies are not negligible. To this end, we propose Delphi, a novel diffusion-based long video generation method with a shared noise modeling mechanism across the multi-views to increase spatial consistency, and a feature-aligned module to achieves both precise controllability and temporal consistency. Our method can generate up to 40 frames of video without loss of consistency which is about 5 times longer compared with state-of-the-art methods. Instead of randomly generating new data, we further design a sampling policy to let Delphi generate new data that are similar to those failure cases to improve the sample efficiency. This is achieved by building a failure-case driven framework with the help of pre-trained visual language models. Our extensive experiment demonstrates that our Delphi generates a higher quality of long videos surpassing previous state-of-the-art methods. Consequentially, with only generating 4% of the training dataset size, our framework is able to go beyond perception and prediction tasks, for the first time to the best of our knowledge, boost the planning performance of the end-to-end autonomous driving model by a margin of 25%.
Transforming Image Super-Resolution: A ConvFormer-based Efficient Approach
Jan 11, 2024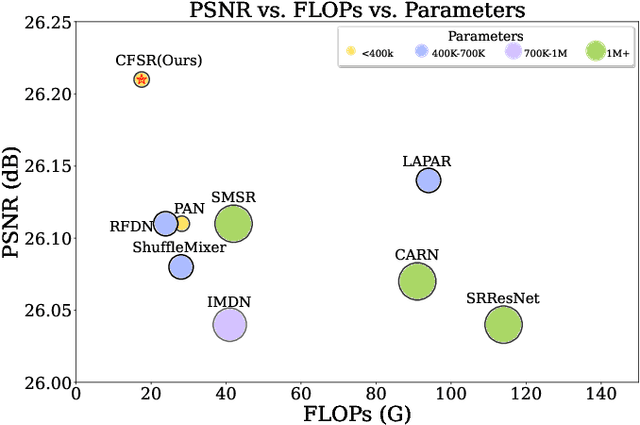
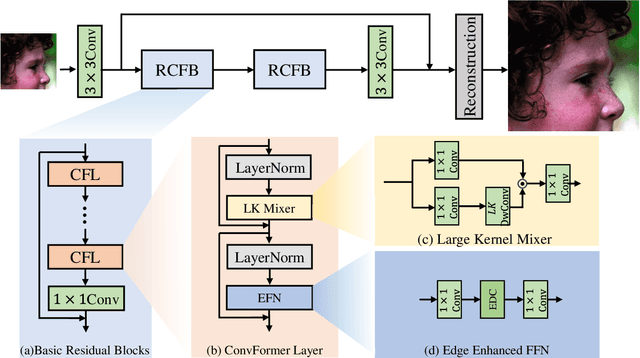
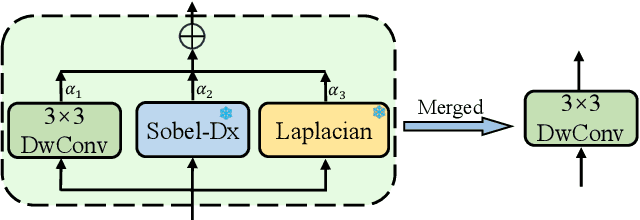
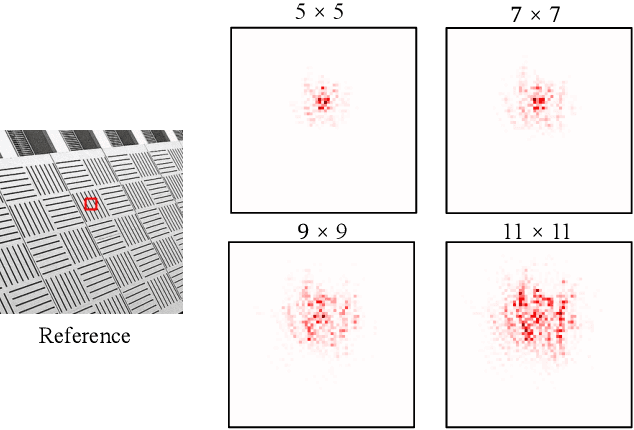
Recent progress in single-image super-resolution (SISR) has achieved remarkable performance, yet the computational costs of these methods remain a challenge for deployment on resource-constrained devices. Especially for transformer-based methods, the self-attention mechanism in such models brings great breakthroughs while incurring substantial computational costs. To tackle this issue, we introduce the Convolutional Transformer layer (ConvFormer) and the ConvFormer-based Super-Resolution network (CFSR), which offer an effective and efficient solution for lightweight image super-resolution tasks. In detail, CFSR leverages the large kernel convolution as the feature mixer to replace the self-attention module, efficiently modeling long-range dependencies and extensive receptive fields with a slight computational cost. Furthermore, we propose an edge-preserving feed-forward network, simplified as EFN, to obtain local feature aggregation and simultaneously preserve more high-frequency information. Extensive experiments demonstrate that CFSR can achieve an advanced trade-off between computational cost and performance when compared to existing lightweight SR methods. Compared to state-of-the-art methods, e.g. ShuffleMixer, the proposed CFSR achieves 0.39 dB gains on Urban100 dataset for x2 SR task while containing 26% and 31% fewer parameters and FLOPs, respectively. Code and pre-trained models are available at https://github.com/Aitical/CFSR.