 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrectAD: A Self-Correcting Agentic System to Improve End-to-end Planning in Autonomous Driving
Nov 17, 2025End-to-end planning methods are the de facto standard of the current autonomous driving system, while the robustness of the data-driven approaches suffers due to the notorious long-tail problem (i.e., rare but safety-critical failure cases). In this work, we explore whether recent diffusion-based video generation methods (a.k.a. world models), paired with structured 3D layouts, can enable a fully automated pipeline to self-correct such failure cases. We first introduce an agent to simulate the role of product manager, dubbed PM-Agent, which formulates data requirements to collect data similar to the failure cases. Then, we use a generative model that can simulate both data collection and annotation. However, existing generative models struggle to generate high-fidelity data conditioned on 3D layouts. To address this, we propose DriveSora, which can generate spatiotemporally consistent videos aligned with the 3D annotations requested by PM-Agent. We integrate these components into our self-correcting agentic system, CorrectAD. Importantly, our pipeline is an end-to-end model-agnostic and can be applied to improve any end-to-end planner. Evaluated on both nuScenes and a more challenging in-house dataset across multiple end-to-end planners, CorrectAD corrects 62.5% and 49.8% of failure cases, reducing collision rates by 39% and 27%, respectively.
ChemBOMAS: Accelerated BO in Chemistry with LLM-Enhanced Multi-Agent System
Sep 10, 2025The efficiency of Bayesian optimization (BO) in chemistry is often hindered by sparse experimental data and complex reaction mechanisms. To overcome these limitations, we introduce ChemBOMAS, a new framework named LLM-Enhanced Multi-Agent System for accelerating BO in chemistry. ChemBOMAS's optimization process is enhanced by LLMs and synergistically employs two strategies: knowledge-driven coarse-grained optimization and data-driven fine-grained optimization. First, in the knowledge-driven coarse-grained optimization stage, LLMs intelligently decompose the vast search space by reasoning over existing chemical knowledge to identify promising candidate regions. Subsequently, in the data-driven fine-grained optimization stage, LLMs enhance the BO process within these candidate regions by generating pseudo-data points, thereby improving data utilization efficiency and accelerating convergence. Benchmark evaluations** further confirm that ChemBOMAS significantly enhances optimization effectiveness and efficiency compared to various BO algorithms. Importantly, the practical utility of ChemBOMAS was validated through wet-lab experiments conducted under pharmaceutical industry protocols, targeting conditional optimization for a previously unreported and challenging chemical reaction. In the wet experiment, ChemBOMAS achieved an optimal objective value of 96%. This was substantially higher than the 15% achieved by domain experts. This real-world success, together with strong performance on benchmark evaluations, highlights ChemBOMAS as a powerful tool to accelerate chemical discovery.
FoMo4Wheat: Toward reliable crop vision foundation models with globally curated data
Sep 08, 2025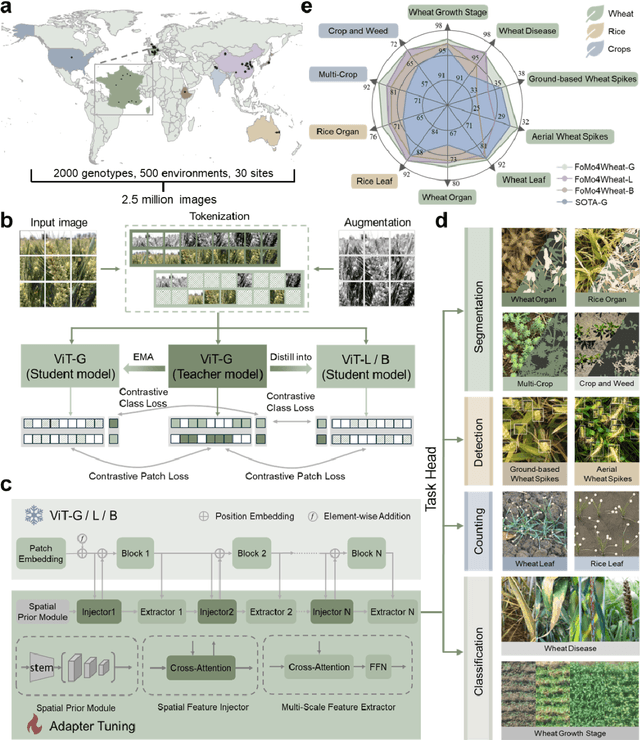

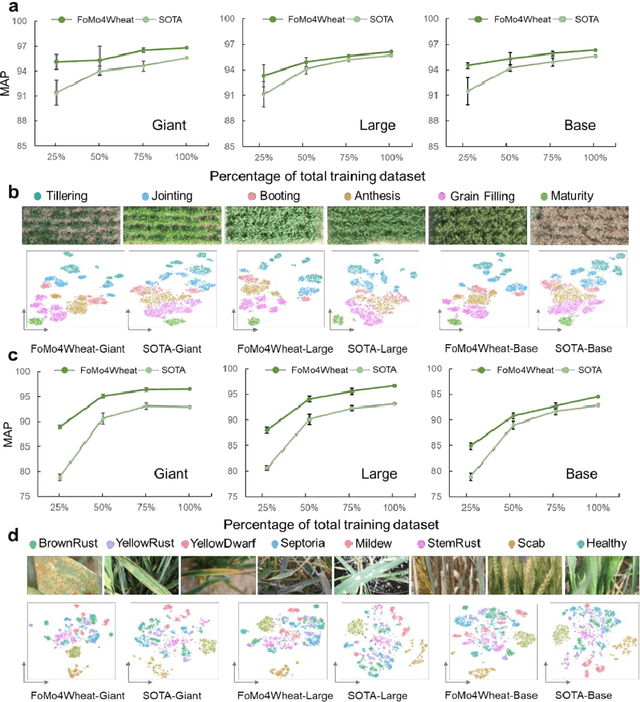
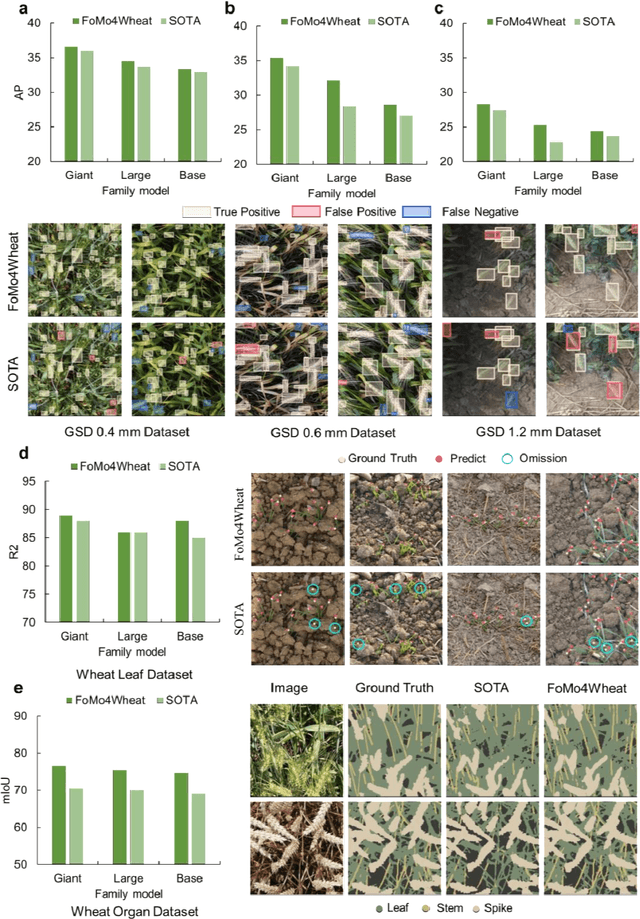
Vision-driven field monitoring is central to digital agriculture, yet models built on general-domain pretrained backbones often fail to generalize across tasks, owing to the interaction of fine, variable canopy structures with fluctuating field conditions. We present FoMo4Wheat, one of the first crop-domain vision foundation model pretrained with self-supervision on ImAg4Wheat, the largest and most diverse wheat image dataset to date (2.5 million high-resolution images collected over a decade at 30 global sites, spanning >2,000 genotypes and >500 environmental conditions). This wheat-specific pretraining yields representations that are robust for wheat and transferable to other crops and weeds. Across ten in-field vision tasks at canopy and organ levels, FoMo4Wheat models consistently outperform state-of-the-art models pretrained on general-domain dataset. These results demonstrate the value of crop-specific foundation models for reliable in-field perception and chart a path toward a universal crop foundation model with cross-species and cross-task capabilities. FoMo4Wheat models and the ImAg4Wheat dataset are publicly available online: https://github.com/PheniX-Lab/FoMo4Wheat and https://huggingface.co/PheniX-Lab/FoMo4Wheat. The demonstration website is: https://fomo4wheat.phenix-lab.com/.
OleSpeech-IV: A Large-Scale Multispeaker and Multilingual Conversational Speech Dataset with Diverse Topics
Sep 04, 2025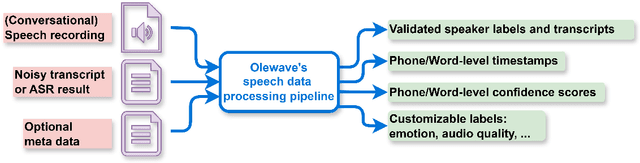
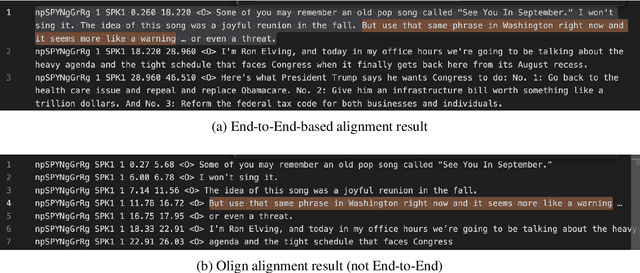
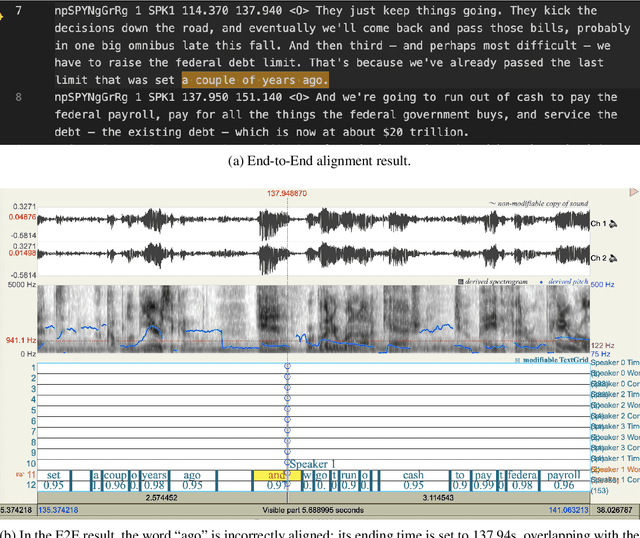
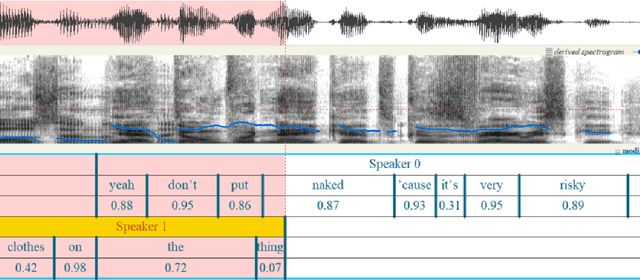
OleSpeech-IV dataset is a large-scale multispeaker and multilingual conversational speech dataset with diverse topics. The audio content comes from publicly-available English podcasts, talk shows, teleconferences, and other conversations. Speaker names, turns, and transcripts are human-sourced and refined by a proprietary pipeline, while additional information such as timestamps and confidence scores is derived from the pipeline. The IV denotes its position as Tier IV in the Olewave dataset series. In addition, we have open-sourced a subset, OleSpeech-IV-2025-EN-AR-100, for non-commercial research use.
CMPhysBench: A Benchmark for Evaluating Large Language Models in Condensed Matter Physics
Aug 25, 2025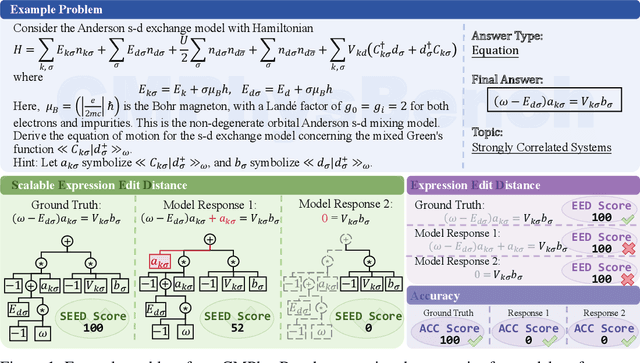
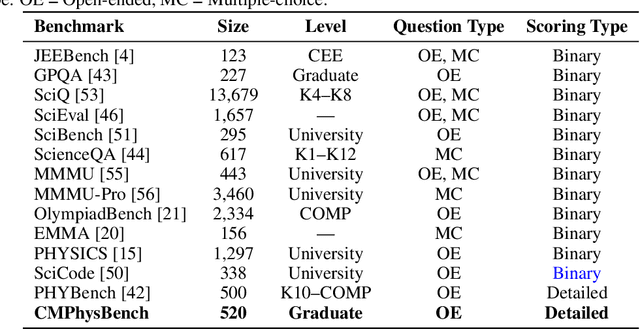
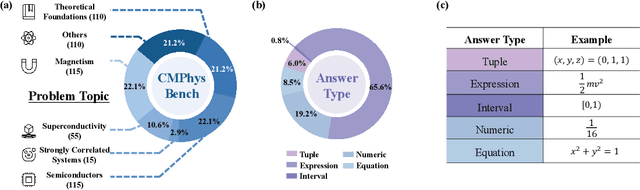

We introduce CMPhysBench, designed to assess the proficiency of Large Language Models (LLMs) in Condensed Matter Physics, as a novel Benchmark. CMPhysBench is composed of more than 520 graduate-level meticulously curated questions covering both representative subfields and foundational theoretical frameworks of condensed matter physics, such as magnetism, superconductivity, strongly correlated systems, etc. To ensure a deep understanding of the problem-solving process,we focus exclusively on calculation problems, requiring LLMs to independently generate comprehensive solutions. Meanwhile, leveraging tree-based representations of expressions, we introduce the Scalable Expression Edit Distance (SEED) score, which provides fine-grained (non-binary) partial credit and yields a more accurate assessment of similarity between prediction and ground-truth. Our results show that even the best models, Grok-4, reach only 36 average SEED score and 28% accuracy on CMPhysBench, underscoring a significant capability gap, especially for this practical and frontier domain relative to traditional physics. The code anddataset are publicly available at https://github.com/CMPhysBench/CMPhysBench.
Reasoning BO: Enhancing Bayesian Optimization with Long-Context Reasoning Power of LLMs
May 19, 2025Many real-world scientific and industrial applications require the optimization of expensive black-box functions. Bayesian Optimization (BO) provides an effective framework for such problems. However, traditional BO methods are prone to get trapped in local optima and often lack interpretable insights. To address this issue, this paper designs Reasoning BO, a novel framework that leverages reasoning models to guide the sampling process in BO while incorporating multi-agent systems and knowledge graphs for online knowledge accumulation. By integrating the reasoning and contextual understanding capabilities of Large Language Models (LLMs), we can provide strong guidance to enhance the BO process. As the optimization progresses, Reasoning BO provides real-time sampling recommendations along with critical insights grounded in plausible scientific theories, aiding in the discovery of superior solutions within the search space. We systematically evaluate our approach across 10 diverse tasks encompassing synthetic mathematical functions and complex real-world applications. The framework demonstrates its capability to progressively refine sampling strategies through real-time insights and hypothesis evolution, effectively identifying higher-performing regions of the search space for focused exploration. This process highlights the powerful reasoning and context-learning abilities of LLMs in optimization scenarios. For example, in the Direct Arylation task, our method increased the yield to 60.7%, whereas traditional BO achieved only a 25.2% yield. Furthermore, our investigation reveals that smaller LLMs, when fine-tuned through reinforcement learning, can attain comparable performance to their larger counterparts. This enhanced reasoning capability paves the way for more efficient automated scientific experimentation while maintaining computational feasibility.
KAN See Your Face
Nov 27, 2024



With the advancement of face reconstruction (FR) systems, privacy-preserving face recognition (PPFR) has gained popularity for its secure face recognition, enhanced facial privacy protection, and robustness to various attacks. Besides, specific models and algorithms are proposed for face embedding protection by mapping embeddings to a secure space. However, there is a lack of studies on investigating and evaluating the possibility of extracting face images from embeddings of those systems, especially for PPFR. In this work, we introduce the first approach to exploit Kolmogorov-Arnold Network (KAN) for conducting embedding-to-face attacks against state-of-the-art (SOTA) FR and PPFR systems. Face embedding mapping (FEM) models are proposed to learn the distribution mapping relation between the embeddings from the initial domain and target domain. In comparison with Multi-Layer Perceptrons (MLP), we provide two variants, FEM-KAN and FEM-MLP, for efficient non-linear embedding-to-embedding mapping in order to reconstruct realistic face images from the corresponding face embedding. To verify our methods, we conduct extensive experiments with various PPFR and FR models. We also measure reconstructed face images with different metrics to evaluate the image quality. Through comprehensive experiments, we demonstrate the effectiveness of FEMs in accurate embedding mapping and face reconstruction.
ShieldDiff: Suppressing Sexual Content Generation from Diffusion Models through Reinforcement Learning
Oct 04, 2024



With the advance of generative AI, the text-to-image (T2I) model has the ability to generate various contents. However, the generated contents cannot be fully controlled. There is a potential risk that T2I model can generate unsafe images with uncomfortable contents. In our work, we focus on eliminating the NSFW (not safe for work) content generation from T2I model while maintaining the high quality of generated images by fine-tuning the pre-trained diffusion model via reinforcement learning by optimizing the well-designed content-safe reward function. The proposed method leverages a customized reward function consisting of the CLIP (Contrastive Language-Image Pre-training) and nudity rewards to prune the nudity contents that adhere to the pret-rained model and keep the corresponding semantic meaning on the safe side. In this way, the T2I model is robust to unsafe adversarial prompts since unsafe visual representations are mitigated from latent space. Extensive experiments conducted on different datasets demonstrate the effectiveness of the proposed method in alleviating unsafe content generation while preserving the high-fidelity of benign images as well as images generated by unsafe prompts. We compare with five existing state-of-the-art (SOTA) methods and achieve competitive performance on sexual content removal and image quality retention. In terms of robustness, our method outperforms counterparts under the SOTA black-box attacking model. Furthermore, our constructed method can be a benchmark for anti-NSFW generation with semantically-relevant safe alignment.
Fusion is all you need: Face Fusion for Customized Identity-Preserving Image Synthesis
Sep 27, 2024Text-to-image (T2I) models have significantly advanced the development of artificial intelligence, enabling the generation of high-quality images in diverse contexts based on specific text prompts. However, existing T2I-based methods often struggle to accurately reproduce the appearance of individuals from a reference image and to create novel representations of those individuals in various settings. To address this, we leverage the pre-trained UNet from Stable Diffusion to incorporate the target face image directly into the generation process. Our approach diverges from prior methods that depend on fixed encoders or static face embeddings, which often fail to bridge encoding gaps. Instead, we capitalize on UNet's sophisticated encoding capabilities to process reference images across multiple scales. By innovatively altering the cross-attention layers of the UNet, we effectively fuse individual identities into the generative process. This strategic integration of facial features across various scales not only enhances the robustness and consistency of the generated images but also facilitates efficient multi-reference and multi-identity generation. Our method sets a new benchmark in identity-preserving image generation, delivering state-of-the-art results in similarity metrics while maintaining prompt alignment.
Multiclass Arrhythmia Classification using Smartwatch Photoplethysmography Signals Collected in Real-life Settings
Sep 10, 2024Most deep learning models of multiclass arrhythmia classification are tested on fingertip photoplethysmographic (PPG) data, which has higher signal-to-noise ratios compared to smartwatch-derived PPG, and the best reported sensitivity value for premature atrial/ventricular contraction (PAC/PVC) detection is only 75%. To improve upon PAC/PVC detection sensitivity while maintaining high AF detection, we use multi-modal data which incorporates 1D PPG, accelerometers, and heart rate data as the inputs to a computationally efficient 1D bi-directional Gated Recurrent Unit (1D-Bi-GRU) model to detect three arrhythmia classes. We used motion-artifact prone smartwatch PPG data from the NIH-funded Pulsewatch clinical trial. Our multimodal model tested on 72 subjects achieved an unprecedented 83% sensitivity for PAC/PVC detection while maintaining a high accuracy of 97.31% for AF detection. These results outperformed the best state-of-the-art model by 20.81% for PAC/PVC and 2.55% for AF detection even while our model was computationally more efficient (14 times lighter and 2.7 faster).