 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAST-LIVO2: Fast, Direct LiDAR-Inertial-Visual Odometry
Aug 26, 2024

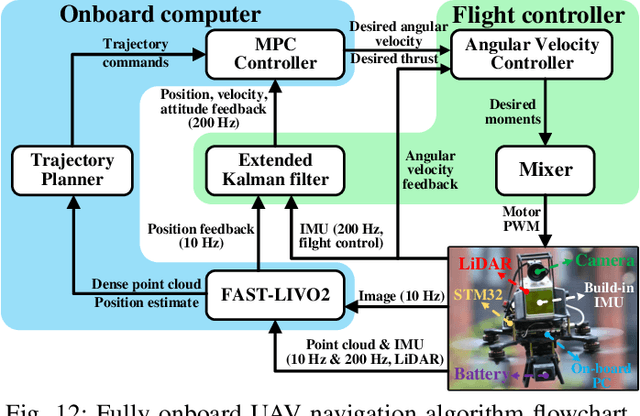

This paper proposes FAST-LIVO2: a fast, direct LiDAR-inertial-visual odometry framework to achieve accurate and robust state estimation in SLAM tasks and provide great potential in real-time, onboard robotic applications. FAST-LIVO2 fuses the IMU, LiDAR and image measurements efficiently through an ESIKF. To address the dimension mismatch between the heterogeneous LiDAR and image measurements, we use a sequential update strategy in the Kalman filter. To enhance the efficiency, we use direct methods for both the visual and LiDAR fusion, where the LiDAR module registers raw points without extracting edge or plane features and the visual module minimizes direct photometric errors without extracting ORB or FAST corner features. The fusion of both visual and LiDAR measurements is based on a single unified voxel map where the LiDAR module constructs the geometric structure for registering new LiDAR scans and the visual module attaches image patches to the LiDAR points. To enhance the accuracy of image alignment, we use plane priors from the LiDAR points in the voxel map (and even refine the plane prior) and update the reference patch dynamically after new images are aligned. Furthermore, to enhance the robustness of image alignment, FAST-LIVO2 employs an on-demanding raycast operation and estimates the image exposure time in real time. Lastly, we detail three applications of FAST-LIVO2: UAV onboard navigation demonstrating the system's computation efficiency for real-time onboard navigation, airborne mapping showcasing the system's mapping accuracy, and 3D model rendering (mesh-based and NeRF-based) underscoring the suitability of our reconstructed dense map for subsequent rendering tasks. We open source our code, dataset and application on GitHub to benefit the robotics community.
STD: Stable Triangle Descriptor for 3D place recognition
Sep 26, 2022


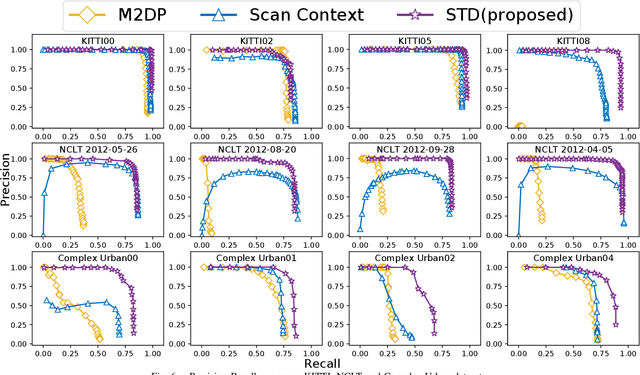
In this work, we present a novel global descriptor termed stable triangle descriptor (STD) for 3D place recognition. For a triangle, its shape is uniquely determined by the length of the sides or included angles. Moreover, the shape of triangles is completely invariant to rigid transformations. Based on this property, we first design an algorithm to efficiently extract local key points from the 3D point cloud and encode these key points into triangular descriptors. Then, place recognition is achieved by matching the side lengths (and some other information) of the descriptors between point clouds. The point correspondence obtained from the descriptor matching pair can be further used in geometric verification, which greatly improves the accuracy of place recognition. In our experiments, we extensively compare our proposed system against other state-of-the-art systems (i.e., M2DP, Scan Context) on public datasets (i.e., KITTI, NCLT, and Complex-Urban) and our self-collected dataset (with a non-repetitive scanning solid-state LiDAR). All the quantitative results show that STD has stronger adaptability and a great improvement in precision over its counterparts. To share our findings and make contributions to the community, we open source our code on our GitHub: https://github.com/hku-mars/STD.
A Robust Stereo Camera Localization Method with Prior LiDAR Map Constrains
Dec 02, 2019
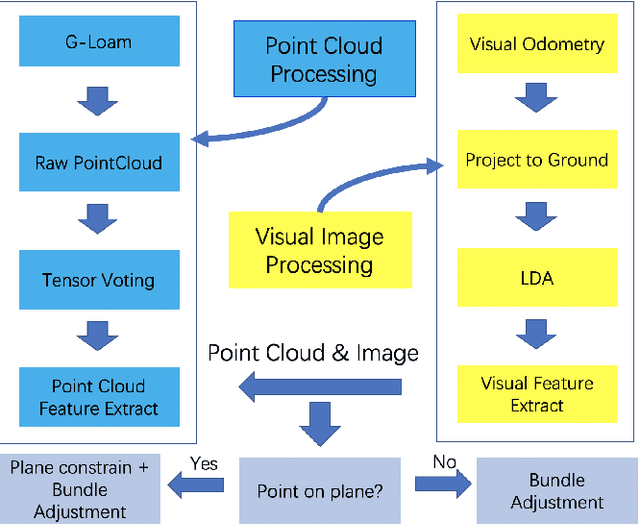
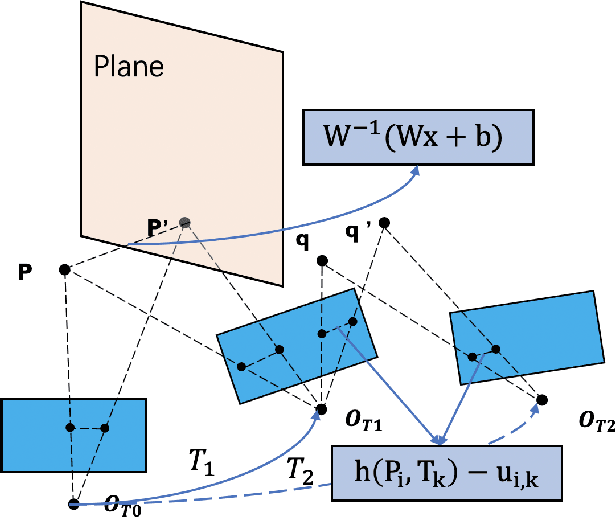
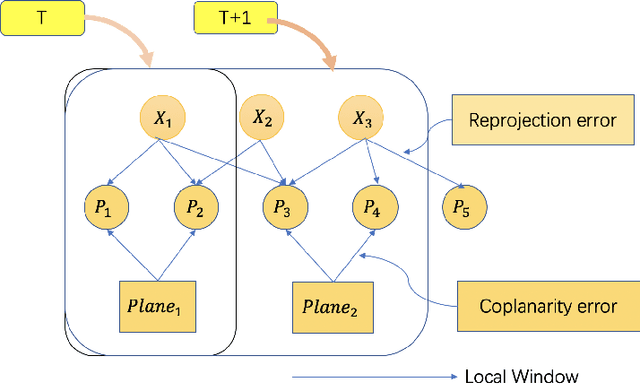
In complex environments, low-cost and robust localization is a challenging problem. For example, in a GPSdenied environment, LiDAR can provide accurate position information, but the cost is high. In general, visual SLAM based localization methods become unreliable when the sunlight changes greatly. Therefore, inexpensive and reliable methods are required. In this paper, we propose a stereo visual localization method based on the prior LiDAR map. Different from the conventional visual localization system, we design a novel visual optimization model by matching planar information between the LiDAR map and visual image. Bundle adjustment is built by using coplanarity constraints. To solve the optimization problem, we use a graph-based optimization algorithm and a local window optimization method. Finally, we estimate a full six degrees of freedom (DOF) pose without scale drift. To validate the efficiency, the proposed method has been tested on the KITTI dataset. The results show that our method is more robust and accurate than the state-of-art ORB-SLAM2.
Road Curb Detection Using A Novel Tensor Voting Algorithm
Nov 29, 2019

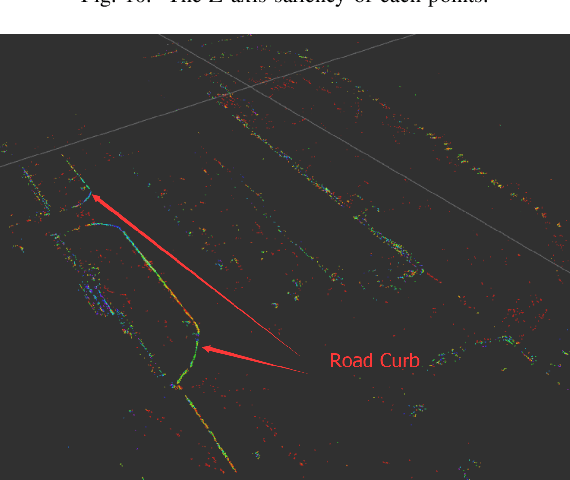
Road curb detection is very important and necessary for autonomous driving because it can improve the safety and robustness of robot navigation in the outdoor environment. In this paper, a novel road curb detection method based on tensor voting is presented. The proposed method processes the dense point cloud acquired using a 3D LiDAR. Firstly, we utilize a sparse tensor voting approach to extract the line and surface features. Then, we use an adaptive height threshold and a surface vector to extract the point clouds of the road curbs. Finally, we utilize the height threshold to segment different obstacles from the occupancy grid map. This also provides an effective way of generating high-definition maps. The experimental results illustrate that our proposed algorithm can detect road curbs with near real-time performance.