 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoarse-to-fine Hybrid 3D Mapping System with Co-calibrated Omnidirectional Camera and Non-repetitive LiDAR
Feb 08, 2023



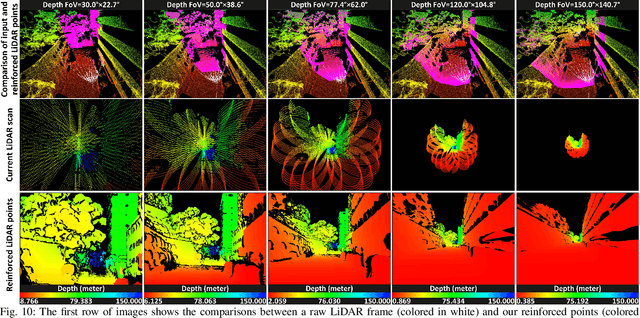
This paper presents a novel 3D mapping robot with an omnidirectional field-of-view (FoV) sensor suite composed of a non-repetitive LiDAR and an omnidirectional camera. Thanks to the non-repetitive scanning nature of the LiDAR, an automatic targetless co-calibration method is proposed to simultaneously calibrate the intrinsic parameters for the omnidirectional camera and the extrinsic parameters for the camera and LiDAR, which is crucial for the required step in bringing color and texture information to the point clouds in surveying and mapping tasks. Comparisons and analyses are made to target-based intrinsic calibration and mutual information (MI)-based extrinsic calibration, respectively. With this co-calibrated sensor suite, the hybrid mapping robot integrates both the odometry-based mapping mode and stationary mapping mode. Meanwhile, we proposed a new workflow to achieve coarse-to-fine mapping, including efficient and coarse mapping in a global environment with odometry-based mapping mode; planning for viewpoints in the region-of-interest (ROI) based on the coarse map (relies on the previous work); navigating to each viewpoint and performing finer and more precise stationary scanning and mapping of the ROI. The fine map is stitched with the global coarse map, which provides a more efficient and precise result than the conventional stationary approaches and the emerging odometry-based approaches, respectively.
ImMesh: An Immediate LiDAR Localization and Meshing Framework
Jan 12, 2023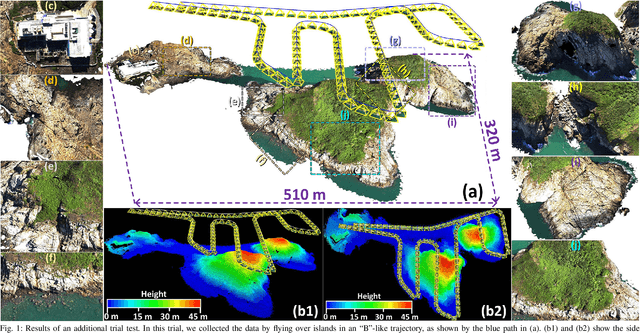
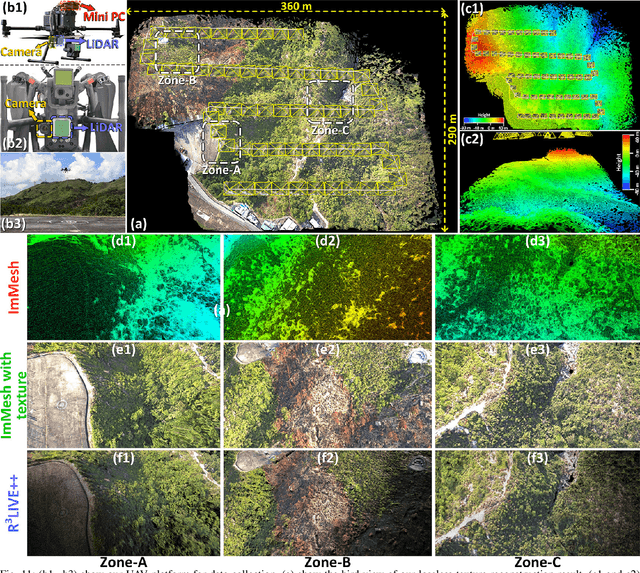

In this paper, we propose a novel LiDAR(-inertial) odometry and mapping framework to achieve the goal of simultaneous localization and meshing in real-time. This proposed framework termed ImMesh comprises four tightly-coupled modules: receiver, localization, meshing, and broadcaster. The localization module utilizes the prepossessed sensor data from the receiver, estimates the sensor pose online by registering LiDAR scans to maps, and dynamically grows the map. Then, our meshing module takes the registered LiDAR scan for incrementally reconstructing the triangle mesh on the fly. Finally, the real-time odometry, map, and mesh are published via our broadcaster. The key contribution of this work is the meshing module, which represents a scene by an efficient hierarchical voxels structure, performs fast finding of voxels observed by new scans, and reconstructs triangle facets in each voxel in an incremental manner. This voxel-wise meshing operation is delicately designed for the purpose of efficiency; it first performs a dimension reduction by projecting 3D points to a 2D local plane contained in the voxel, and then executes the meshing operation with pull, commit and push steps for incremental reconstruction of triangle facets. To the best of our knowledge, this is the first work in literature that can reconstruct online the triangle mesh of large-scale scenes, just relying on a standard CPU without GPU acceleration. To share our findings and make contributions to the community, we make our code publicly available on our GitHub: https://github.com/hku-mars/ImMesh.
STD: Stable Triangle Descriptor for 3D place recognition
Sep 26, 2022


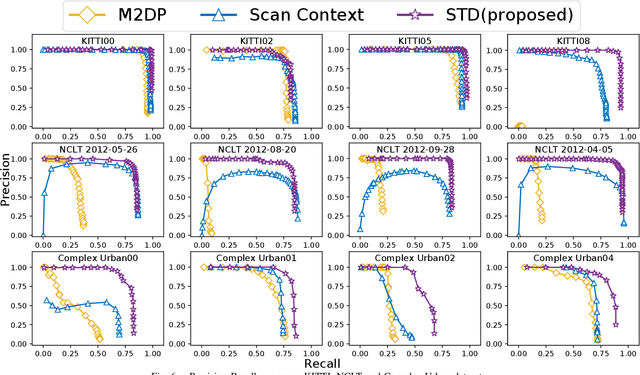
In this work, we present a novel global descriptor termed stable triangle descriptor (STD) for 3D place recognition. For a triangle, its shape is uniquely determined by the length of the sides or included angles. Moreover, the shape of triangles is completely invariant to rigid transformations. Based on this property, we first design an algorithm to efficiently extract local key points from the 3D point cloud and encode these key points into triangular descriptors. Then, place recognition is achieved by matching the side lengths (and some other information) of the descriptors between point clouds. The point correspondence obtained from the descriptor matching pair can be further used in geometric verification, which greatly improves the accuracy of place recognition. In our experiments, we extensively compare our proposed system against other state-of-the-art systems (i.e., M2DP, Scan Context) on public datasets (i.e., KITTI, NCLT, and Complex-Urban) and our self-collected dataset (with a non-repetitive scanning solid-state LiDAR). All the quantitative results show that STD has stronger adaptability and a great improvement in precision over its counterparts. To share our findings and make contributions to the community, we open source our code on our GitHub: https://github.com/hku-mars/STD.
Lidar with Velocity: Motion Distortion Correction of Point Clouds from Oscillating Scanning Lidars
Nov 18, 2021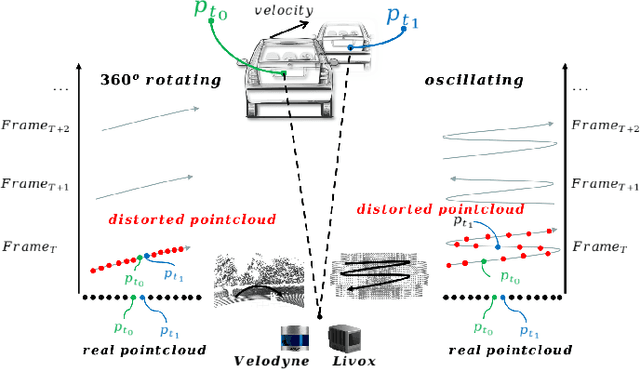
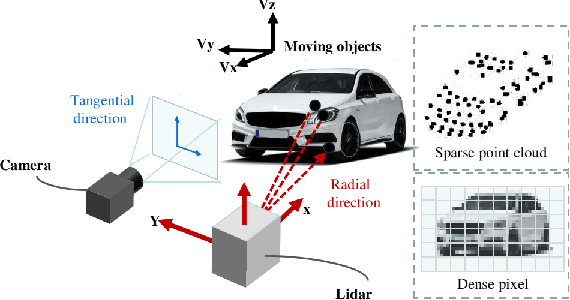
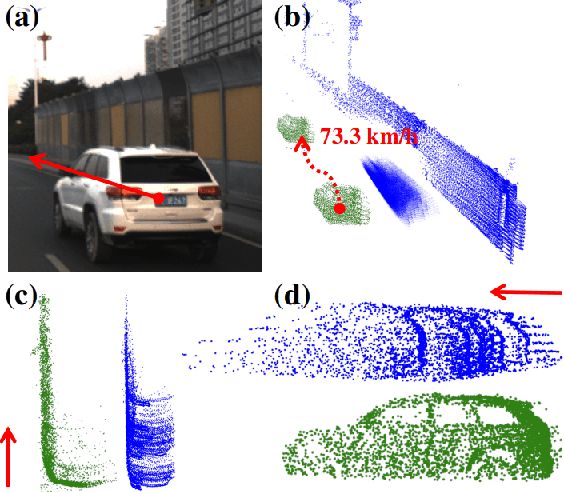
Lidar point cloud distortion from moving object is an important problem in autonomous driving, and recently becomes even more demanding with the emerging of newer lidars, which feature back-and-forth scanning patterns. Accurately estimating moving object velocity would not only provide a tracking capability but also correct the point cloud distortion with more accurate description of the moving object. Since lidar measures the time-of-flight distance but with a sparse angular resolution, the measurement is precise in the radial measurement but lacks angularly. Camera on the other hand provides a dense angular resolution. In this paper, Gaussian-based lidar and camera fusion is proposed to estimate the full velocity and correct the lidar distortion. A probabilistic Kalman-filter framework is provided to track the moving objects, estimate their velocities and simultaneously correct the point clouds distortions. The framework is evaluated on real road data and the fusion method outperforms the traditional ICP-based and point-cloud only method. The complete working framework is open-sourced (https://github.com/ISEE-Technology/lidar-with-velocity) to accelerate the adoption of the emerging lidars.
Efficient and Probabilistic Adaptive Voxel Mapping for Accurate Online 3D SLAM
Sep 21, 2021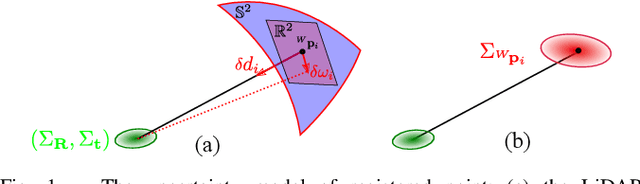

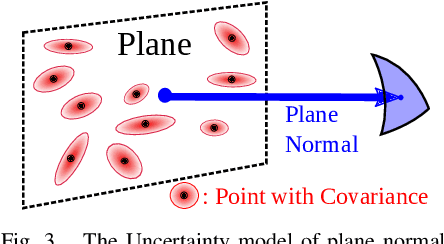

This paper proposes an efficient and probabilistic adaptive voxel mapping method for 3D SLAM. An accurate uncertainty model of point and plane is proposed for probabilistic plane representation. We analyze the need for coarse-to-fine voxel mapping and then use a novel voxel map organized by a Hash table and octrees to build and update the map efficiently. We apply the voxel map to the iterated Kalman filter and construct the maximum posterior probability problem for pose estimation. The experiments on the open KITTI dataset show the high accuracy and efficiency of our method in contrast with other state-of-the-art. Outdoor experiments on unstructured environments with non-repetitive scanning LiDAR further verify the adaptability of our mapping method to different environments and LiDAR scanning patterns.
Pixel-level Extrinsic Self Calibration of High Resolution LiDAR and Camera in Targetless Environments
Mar 02, 2021
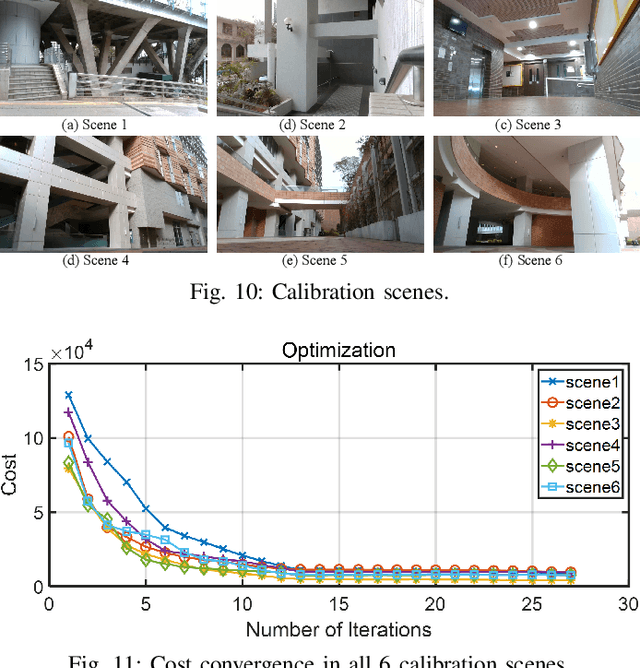


In this letter, we present a novel method for automatic extrinsic calibration of high-resolution LiDARs and RGB cameras in targetless environments. Our approach does not require checkerboards but can achieve pixel-level accuracy by aligning natural edge features in the two sensors. On the theory level, we analyze the constraints imposed by edge features and the sensitivity of calibration accuracy with respect to edge distribution in the scene. On the implementation level, we carefully investigate the physical measuring principles of LiDARs and propose an efficient and accurate LiDAR edge extraction method based on point cloud voxel cutting and plane fitting. Due to the edges' richness in natural scenes, we have carried out experiments in many indoor and outdoor scenes. The results show that this method has high robustness, accuracy, and consistency. It can promote the research and application of the fusion between LiDAR and camera. We have open-sourced our code on GitHub to benefit the community.
CamVox: A Low-cost and Accurate Lidar-assisted Visual SLAM System
Nov 23, 2020
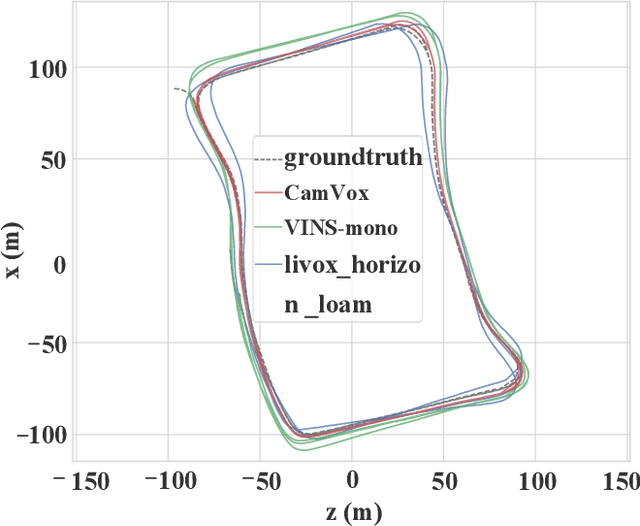

Combining lidar in camera-based simultaneous localization and mapping (SLAM) is an effective method in improving overall accuracy, especially at a large scale outdoor scenario. Recent development of low-cost lidars (e.g. Livox lidar) enable us to explore such SLAM systems with lower budget and higher performance. In this paper we propose CamVox by adapting Livox lidars into visual SLAM (ORB-SLAM2) by exploring the lidars' unique features. Based on the non-repeating nature of Livox lidars, we propose an automatic lidar-camera calibration method that will work in uncontrolled scenes. The long depth detection range also benefit a more efficient mapping. Comparison of CamVox with visual SLAM (VINS-mono) and lidar SLAM (LOAM) are evaluated on the same dataset to demonstrate the performance. We open sourced our hardware, code and dataset on GitHub.
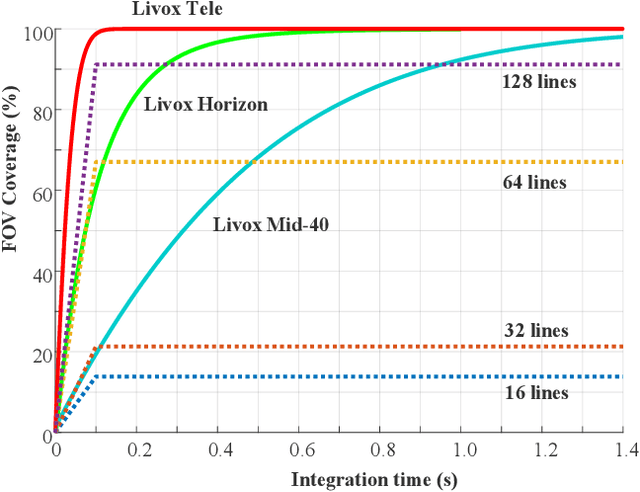
Low-cost Retina-like Robotic Lidars Based on Incommensurable Scanning
Jun 19, 2020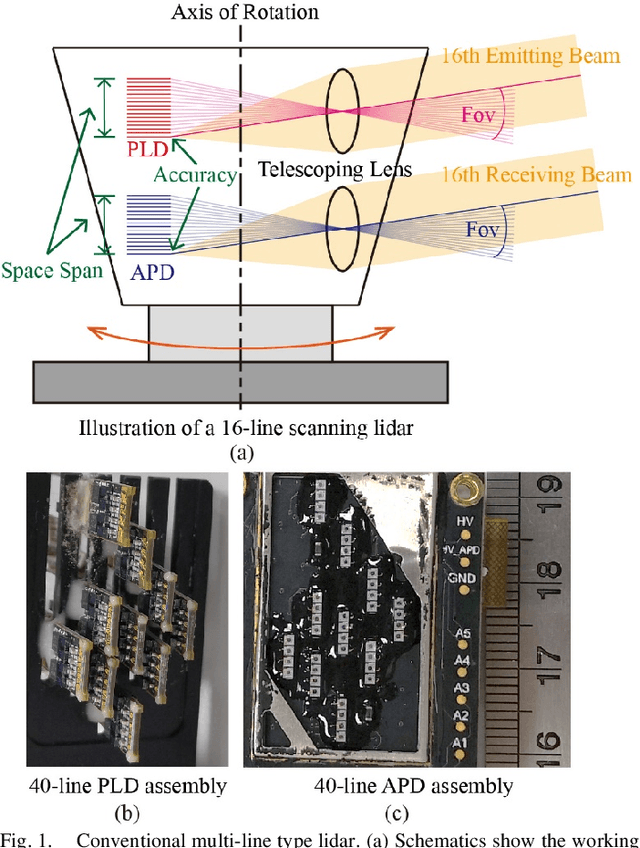

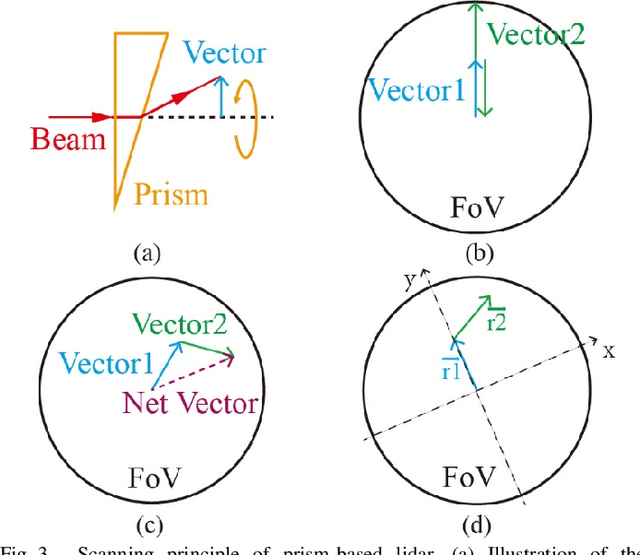
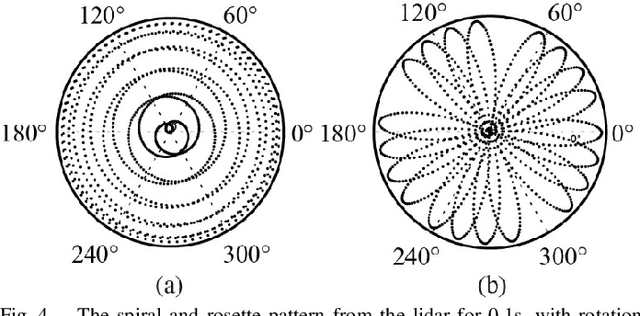
High performance lidars are essential in autonomous robots such as self-driving cars, automated ground vehicles and intelligent machines. Traditional mechanical scanning lidars offer superior performance in autonomous vehicles, but the potential mass application is limited by the inherent manufacturing difficulty. We propose a robotic lidar sensor based on incommensurable scanning that allows straightforward mass production and adoption in autonomous robots. Some unique features are additionally permitted by this incommensurable scanning. Similar to the fovea in human retina, this lidar features a peaked central angular density, enabling in applications that prefers eye-like attention. The incommensurable scanning method of this lidar could also provide a much higher resolution than conventional lidars which is beneficial in robotic applications such as sensor calibration. Examples making use of these advantageous features are demonstrated.