 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMesh-Learner: Texturing Mesh with Spherical Harmonics
Apr 28, 2025In this paper, we present a 3D reconstruction and rendering framework termed Mesh-Learner that is natively compatible with traditional rasterization pipelines. It integrates mesh and spherical harmonic (SH) texture (i.e., texture filled with SH coefficients) into the learning process to learn each mesh s view-dependent radiance end-to-end. Images are rendered by interpolating surrounding SH Texels at each pixel s sampling point using a novel interpolation method. Conversely, gradients from each pixel are back-propagated to the related SH Texels in SH textures. Mesh-Learner exploits graphic features of rasterization pipeline (texture sampling, deferred rendering) to render, which makes Mesh-Learner naturally compatible with tools (e.g., Blender) and tasks (e.g., 3D reconstruction, scene rendering, reinforcement learning for robotics) that are based on rasterization pipelines. Our system can train vast, unlimited scenes because we transfer only the SH textures within the frustum to the GPU for training. At other times, the SH textures are stored in CPU RAM, which results in moderate GPU memory usage. The rendering results on interpolation and extrapolation sequences in the Replica and FAST-LIVO2 datasets achieve state-of-the-art performance compared to existing state-of-the-art methods (e.g., 3D Gaussian Splatting and M2-Mapping). To benefit the society, the code will be available at https://github.com/hku-mars/Mesh-Learner.
GS-SDF: LiDAR-Augmented Gaussian Splatting and Neural SDF for Geometrically Consistent Rendering and Reconstruction
Mar 13, 2025Digital twins are fundamental to the development of autonomous driving and embodied artificial intelligence. However, achieving high-granularity surface reconstruction and high-fidelity rendering remains a challenge. Gaussian splatting offers efficient photorealistic rendering but struggles with geometric inconsistencies due to fragmented primitives and sparse observational data in robotics applications. Existing regularization methods, which rely on render-derived constraints, often fail in complex environments. Moreover, effectively integrating sparse LiDAR data with Gaussian splatting remains challenging. We propose a unified LiDAR-visual system that synergizes Gaussian splatting with a neural signed distance field. The accurate LiDAR point clouds enable a trained neural signed distance field to offer a manifold geometry field, This motivates us to offer an SDF-based Gaussian initialization for physically grounded primitive placement and a comprehensive geometric regularization for geometrically consistent rendering and reconstruction. Experiments demonstrate superior reconstruction accuracy and rendering quality across diverse trajectories. To benefit the community, the codes will be released at https://github.com/hku-mars/GS-SDF.
An End-to-End Learning-Based Multi-Sensor Fusion for Autonomous Vehicle Localization
Mar 07, 2025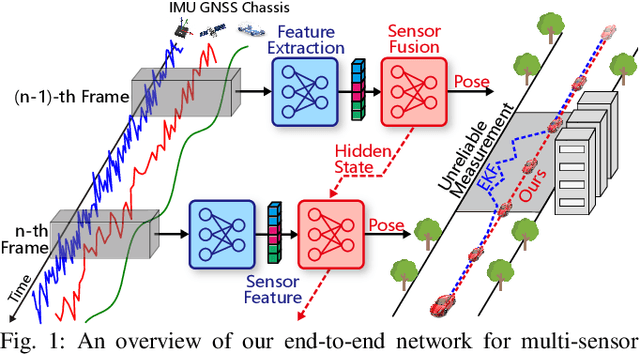
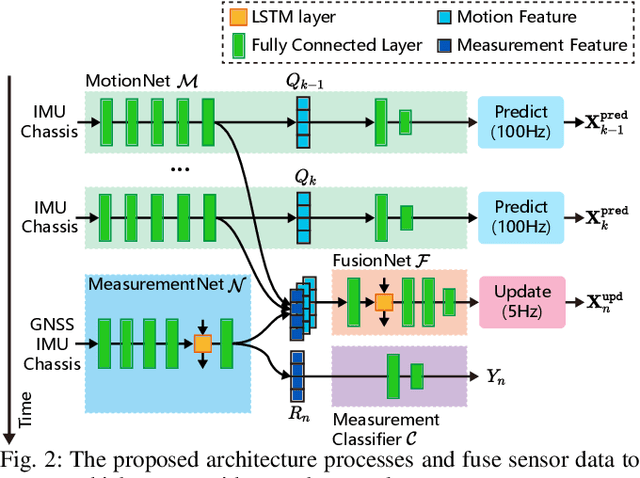
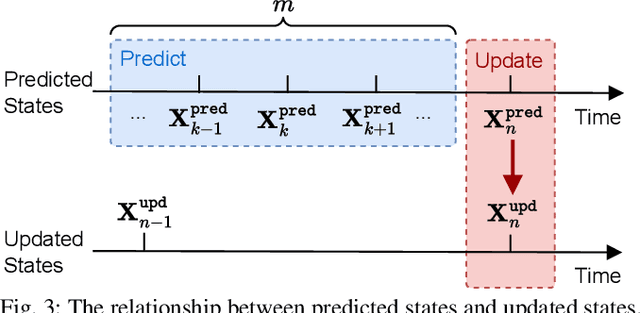

Multi-sensor fusion is essential for autonomous vehicle localization, as it is capable of integrating data from various sources for enhanced accuracy and reliability. The accuracy of the integrated location and orientation depends on the precision of the uncertainty modeling. Traditional methods of uncertainty modeling typically assume a Gaussian distribution and involve manual heuristic parameter tuning. However, these methods struggle to scale effectively and address long-tail scenarios. To address these challenges, we propose a learning-based method that encodes sensor information using higher-order neural network features, thereby eliminating the need for uncertainty estimation. This method significantly eliminates the need for parameter fine-tuning by developing an end-to-end neural network that is specifically designed for multi-sensor fusion. In our experiments, we demonstrate the effectiveness of our approach in real-world autonomous driving scenarios. Results show that the proposed method outperforms existing multi-sensor fusion methods in terms of both accuracy and robustness. A video of the results can be viewed at https://youtu.be/q4iuobMbjME.
Voxel-SLAM: A Complete, Accurate, and Versatile LiDAR-Inertial SLAM System
Oct 11, 2024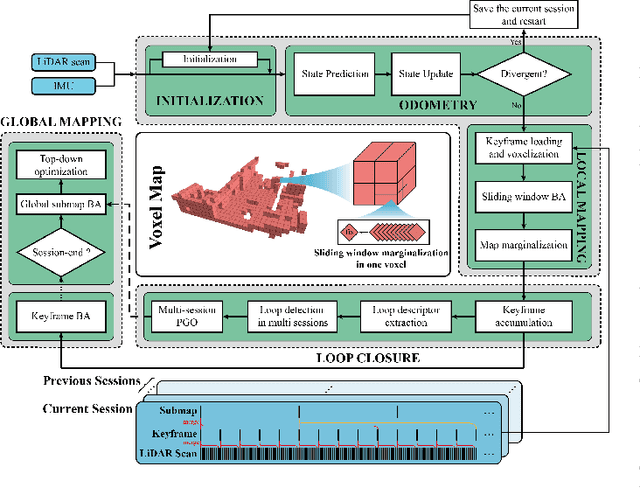
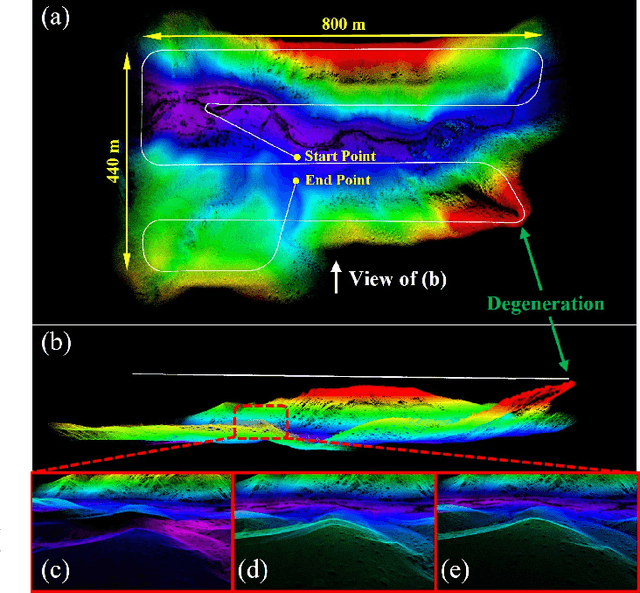
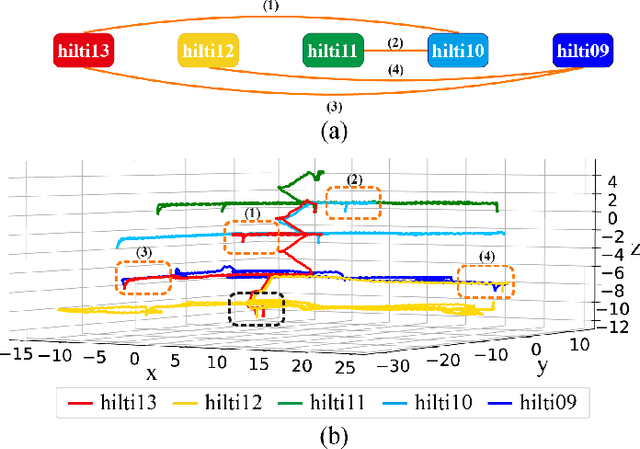

In this work, we present Voxel-SLAM: a complete, accurate, and versatile LiDAR-inertial SLAM system that fully utilizes short-term, mid-term, long-term, and multi-map data associations to achieve real-time estimation and high precision mapping. The system consists of five modules: initialization, odometry, local mapping, loop closure, and global mapping, all employing the same map representation, an adaptive voxel map. The initialization provides an accurate initial state estimation and a consistent local map for subsequent modules, enabling the system to start with a highly dynamic initial state. The odometry, exploiting the short-term data association, rapidly estimates current states and detects potential system divergence. The local mapping, exploiting the mid-term data association, employs a local LiDAR-inertial bundle adjustment (BA) to refine the states (and the local map) within a sliding window of recent LiDAR scans. The loop closure detects previously visited places in the current and all previous sessions. The global mapping refines the global map with an efficient hierarchical global BA. The loop closure and global mapping both exploit long-term and multi-map data associations. We conducted a comprehensive benchmark comparison with other state-of-the-art methods across 30 sequences from three representative scenes, including narrow indoor environments using hand-held equipment, large-scale wilderness environments with aerial robots, and urban environments on vehicle platforms. Other experiments demonstrate the robustness and efficiency of the initialization, the capacity to work in multiple sessions, and relocalization in degenerated environments.
LVBA: LiDAR-Visual Bundle Adjustment for RGB Point Cloud Mapping
Sep 17, 2024



Point cloud maps with accurate color are crucial in robotics and mapping applications. Existing approaches for producing RGB-colorized maps are primarily based on real-time localization using filter-based estimation or sliding window optimization, which may lack accuracy and global consistency. In this work, we introduce a novel global LiDAR-Visual bundle adjustment (BA) named LVBA to improve the quality of RGB point cloud mapping beyond existing baselines. LVBA first optimizes LiDAR poses via a global LiDAR BA, followed by a photometric visual BA incorporating planar features from the LiDAR point cloud for camera pose optimization. Additionally, to address the challenge of map point occlusions in constructing optimization problems, we implement a novel LiDAR-assisted global visibility algorithm in LVBA. To evaluate the effectiveness of LVBA, we conducted extensive experiments by comparing its mapping quality against existing state-of-the-art baselines (i.e., R$^3$LIVE and FAST-LIVO). Our results prove that LVBA can proficiently reconstruct high-fidelity, accurate RGB point cloud maps, outperforming its counterparts.
FAST-LIVO2: Fast, Direct LiDAR-Inertial-Visual Odometry
Aug 26, 2024

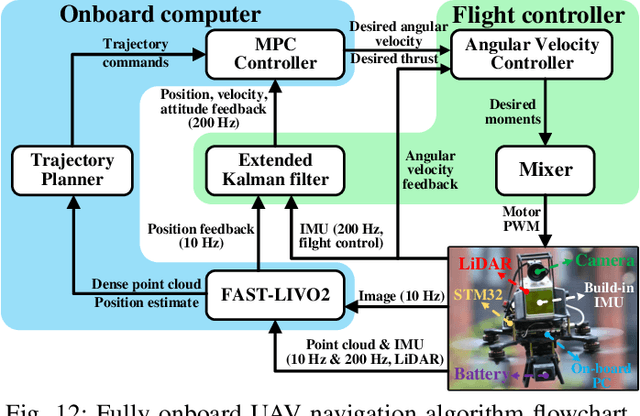

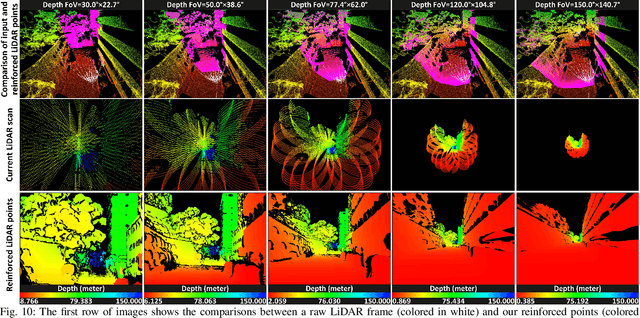
This paper proposes FAST-LIVO2: a fast, direct LiDAR-inertial-visual odometry framework to achieve accurate and robust state estimation in SLAM tasks and provide great potential in real-time, onboard robotic applications. FAST-LIVO2 fuses the IMU, LiDAR and image measurements efficiently through an ESIKF. To address the dimension mismatch between the heterogeneous LiDAR and image measurements, we use a sequential update strategy in the Kalman filter. To enhance the efficiency, we use direct methods for both the visual and LiDAR fusion, where the LiDAR module registers raw points without extracting edge or plane features and the visual module minimizes direct photometric errors without extracting ORB or FAST corner features. The fusion of both visual and LiDAR measurements is based on a single unified voxel map where the LiDAR module constructs the geometric structure for registering new LiDAR scans and the visual module attaches image patches to the LiDAR points. To enhance the accuracy of image alignment, we use plane priors from the LiDAR points in the voxel map (and even refine the plane prior) and update the reference patch dynamically after new images are aligned. Furthermore, to enhance the robustness of image alignment, FAST-LIVO2 employs an on-demanding raycast operation and estimates the image exposure time in real time. Lastly, we detail three applications of FAST-LIVO2: UAV onboard navigation demonstrating the system's computation efficiency for real-time onboard navigation, airborne mapping showcasing the system's mapping accuracy, and 3D model rendering (mesh-based and NeRF-based) underscoring the suitability of our reconstructed dense map for subsequent rendering tasks. We open source our code, dataset and application on GitHub to benefit the robotics community.
Visual Localization in 3D Maps: Comparing Point Cloud, Mesh, and NeRF Representations
Aug 21, 2024



This paper introduces and assesses a cross-modal global visual localization system that can localize camera images within a color 3D map representation built using both visual and lidar sensing. We present three different state-of-the-art methods for creating the color 3D maps: point clouds, meshes, and neural radiance fields (NeRF). Our system constructs a database of synthetic RGB and depth image pairs from these representations. This database serves as the basis for global localization. We present an automatic approach that builds this database by synthesizing novel images of the scene and exploiting the 3D structure encoded in the different representations. Next, we present a global localization system that relies on the synthetic image database to accurately estimate the 6 DoF camera poses of monocular query images. Our localization approach relies on different learning-based global descriptors and feature detectors which enable robust image retrieval and matching despite the domain gap between (real) query camera images and the synthetic database images. We assess the system's performance through extensive real-world experiments in both indoor and outdoor settings, in order to evaluate the effectiveness of each map representation and the benefits against traditional structure-from-motion localization approaches. Our results show that all three map representations can achieve consistent localization success rates of 55% and higher across various environments. NeRF synthesized images show superior performance, localizing query images at an average success rate of 72%. Furthermore, we demonstrate that our synthesized database enables global localization even when the map creation data and the localization sequence are captured when travelling in opposite directions. Our system, operating in real-time on a mobile laptop equipped with a GPU, achieves a processing rate of 1Hz.
Occupancy Grid Mapping without Ray-Casting for High-resolution LiDAR Sensors
Jul 17, 2023
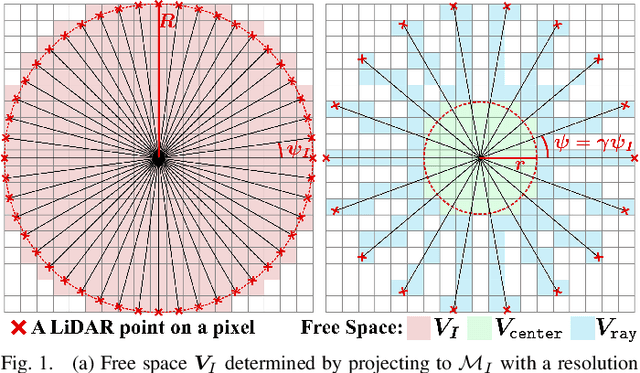
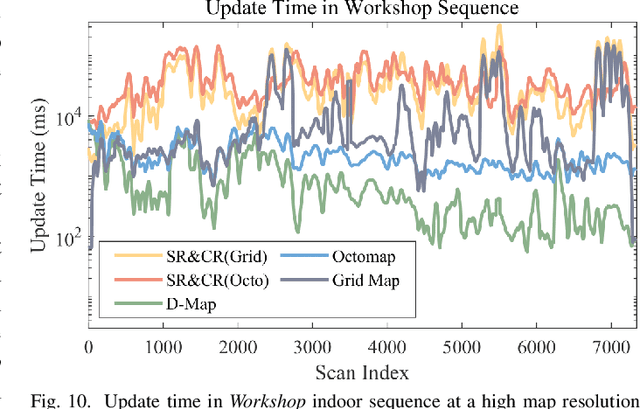

Occupancy mapping is a fundamental component of robotic systems to reason about the unknown and known regions of the environment. This article presents an efficient occupancy mapping framework for high-resolution LiDAR sensors, termed D-Map. The framework introduces three main novelties to address the computational efficiency challenges of occupancy mapping. Firstly, we use a depth image to determine the occupancy state of regions instead of the traditional ray-casting method. Secondly, we introduce an efficient on-tree update strategy on a tree-based map structure. These two techniques avoid redundant visits to small cells, significantly reducing the number of cells to be updated. Thirdly, we remove known cells from the map at each update by leveraging the low false alarm rate of LiDAR sensors. This approach not only enhances our framework's update efficiency by reducing map size but also endows it with an interesting decremental property, which we have named D-Map. To support our design, we provide theoretical analyses of the accuracy of the depth image projection and time complexity of occupancy updates. Furthermore, we conduct extensive benchmark experiments on various LiDAR sensors in both public and private datasets. Our framework demonstrates superior efficiency in comparison with other state-of-the-art methods while maintaining comparable mapping accuracy and high memory efficiency. We demonstrate two real-world applications of D-Map for real-time occupancy mapping on a handle device and an aerial platform carrying a high-resolution LiDAR. In addition, we open-source the implementation of D-Map on GitHub to benefit society: github.com/hku-mars/D-Map.
ImMesh: An Immediate LiDAR Localization and Meshing Framework
Jan 12, 2023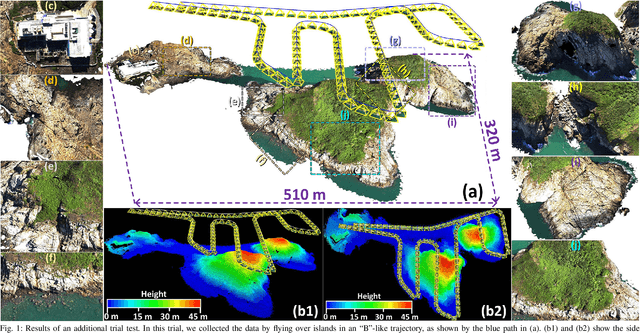
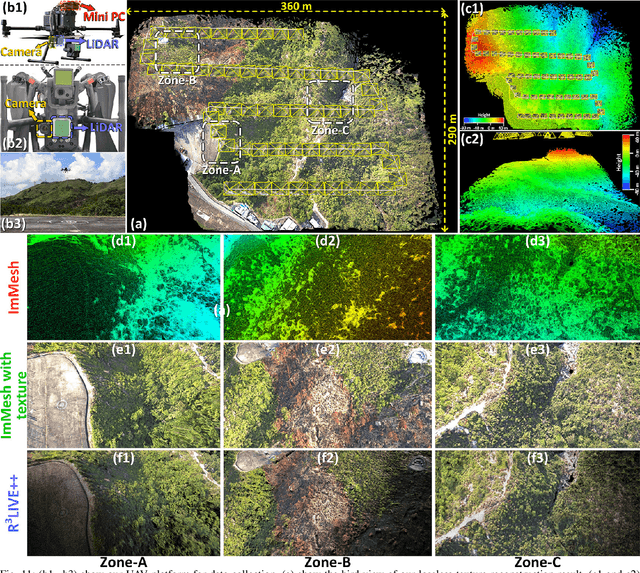

In this paper, we propose a novel LiDAR(-inertial) odometry and mapping framework to achieve the goal of simultaneous localization and meshing in real-time. This proposed framework termed ImMesh comprises four tightly-coupled modules: receiver, localization, meshing, and broadcaster. The localization module utilizes the prepossessed sensor data from the receiver, estimates the sensor pose online by registering LiDAR scans to maps, and dynamically grows the map. Then, our meshing module takes the registered LiDAR scan for incrementally reconstructing the triangle mesh on the fly. Finally, the real-time odometry, map, and mesh are published via our broadcaster. The key contribution of this work is the meshing module, which represents a scene by an efficient hierarchical voxels structure, performs fast finding of voxels observed by new scans, and reconstructs triangle facets in each voxel in an incremental manner. This voxel-wise meshing operation is delicately designed for the purpose of efficiency; it first performs a dimension reduction by projecting 3D points to a 2D local plane contained in the voxel, and then executes the meshing operation with pull, commit and push steps for incremental reconstruction of triangle facets. To the best of our knowledge, this is the first work in literature that can reconstruct online the triangle mesh of large-scale scenes, just relying on a standard CPU without GPU acceleration. To share our findings and make contributions to the community, we make our code publicly available on our GitHub: https://github.com/hku-mars/ImMesh.
MARSIM: A light-weight point-realistic simulator for LiDAR-based UAVs
Dec 01, 2022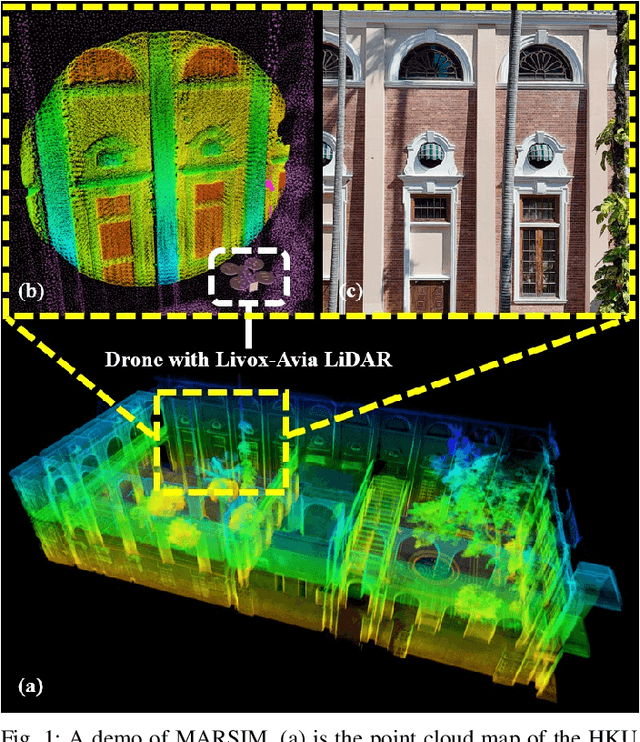


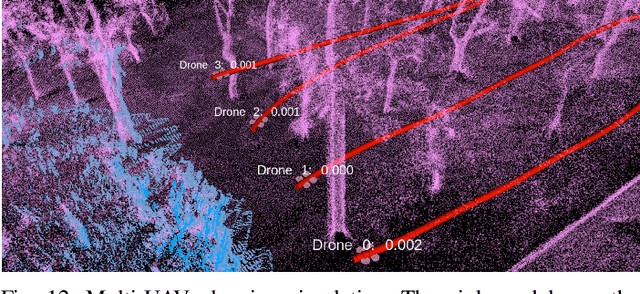
The emergence of low-cost, small form factor and light-weight solid-state LiDAR sensors have brought new opportunities for autonomous unmanned aerial vehicles (UAVs) by advancing navigation safety and computation efficiency. Yet the successful developments of LiDAR-based UAVs must rely on extensive simulations. Existing simulators can hardly perform simulations of real-world environments due to the requirements of dense mesh maps that are difficult to obtain. In this paper, we develop a point-realistic simulator of real-world scenes for LiDAR-based UAVs. The key idea is the underlying point rendering method, where we construct a depth image directly from the point cloud map and interpolate it to obtain realistic LiDAR point measurements. Our developed simulator is able to run on a light-weight computing platform and supports the simulation of LiDARs with different resolution and scanning patterns, dynamic obstacles, and multi-UAV systems. Developed in the ROS framework, the simulator can easily communicate with other key modules of an autonomous robot, such as perception, state estimation, planning, and control. Finally, the simulator provides 10 high-resolution point cloud maps of various real-world environments, including forests of different densities, historic building, office, parking garage, and various complex indoor environments. These realistic maps provide diverse testing scenarios for an autonomous UAV. Evaluation results show that the developed simulator achieves superior performance in terms of time and memory consumption against Gazebo and that the simulated UAV flights highly match the actual one in real-world environments. We believe such a point-realistic and light-weight simulator is crucial to bridge the gap between UAV simulation and experiments and will significantly facilitate the research of LiDAR-based autonomous UAVs in the future.