 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAPO: Stabilizing Reinforcement Learning for LLMs by Silencing Rare Spurious Tokens
Feb 17, 2026Reinforcement Learning (RL) has significantly improved large language model reasoning, but existing RL fine-tuning methods rely heavily on heuristic techniques such as entropy regularization and reweighting to maintain stability. In practice, they often experience late-stage performance collapse, leading to degraded reasoning quality and unstable training. We derive that the magnitude of token-wise policy gradients in RL is negatively correlated with token probability and local policy entropy. Building on this result, we prove that training instability is driven by a tiny fraction of tokens, approximately 0.01\%, which we term \emph{spurious tokens}. When such tokens appear in correct responses, they contribute little to the reasoning outcome but inherit the full sequence-level reward, leading to abnormally amplified gradient updates. Motivated by this observation, we propose Spurious-Token-Aware Policy Optimization (STAPO) for large-scale model refining, which selectively masks such updates and renormalizes the loss over valid tokens. Across six mathematical reasoning benchmarks using Qwen 1.7B, 8B, and 14B base models, STAPO consistently demonstrates superior entropy stability and achieves an average performance improvement of 7.13\% over GRPO, 20-Entropy and JustRL.
UniSplat: Unified Spatio-Temporal Fusion via 3D Latent Scaffolds for Dynamic Driving Scene Reconstruction
Nov 06, 2025Feed-forward 3D reconstruction for autonomous driving has advanced rapidly, yet existing methods struggle with the joint challenges of sparse, non-overlapping camera views and complex scene dynamics. We present UniSplat, a general feed-forward framework that learns robust dynamic scene reconstruction through unified latent spatio-temporal fusion. UniSplat constructs a 3D latent scaffold, a structured representation that captures geometric and semantic scene context by leveraging pretrained foundation models. To effectively integrate information across spatial views and temporal frames, we introduce an efficient fusion mechanism that operates directly within the 3D scaffold, enabling consistent spatio-temporal alignment. To ensure complete and detailed reconstructions, we design a dual-branch decoder that generates dynamic-aware Gaussians from the fused scaffold by combining point-anchored refinement with voxel-based generation, and maintain a persistent memory of static Gaussians to enable streaming scene completion beyond current camera coverage. Extensive experiments on real-world datasets demonstrate that UniSplat achieves state-of-the-art performance in novel view synthesis, while providing robust and high-quality renderings even for viewpoints outside the original camera coverage.
DriveX: Omni Scene Modeling for Learning Generalizable World Knowledge in Autonomous Driving
May 25, 2025Data-driven learning has advanced autonomous driving, yet task-specific models struggle with out-of-distribution scenarios due to their narrow optimization objectives and reliance on costly annotated data. We present DriveX, a self-supervised world model that learns generalizable scene dynamics and holistic representations (geometric, semantic, and motion) from large-scale driving videos. DriveX introduces Omni Scene Modeling (OSM), a module that unifies multimodal supervision-3D point cloud forecasting, 2D semantic representation, and image generation-to capture comprehensive scene evolution. To simplify learning complex dynamics, we propose a decoupled latent world modeling strategy that separates world representation learning from future state decoding, augmented by dynamic-aware ray sampling to enhance motion modeling. For downstream adaptation, we design Future Spatial Attention (FSA), a unified paradigm that dynamically aggregates spatiotemporal features from DriveX's predictions to enhance task-specific inference. Extensive experiments demonstrate DriveX's effectiveness: it achieves significant improvements in 3D future point cloud prediction over prior work, while attaining state-of-the-art results on diverse tasks including occupancy prediction, flow estimation, and end-to-end driving. These results validate DriveX's capability as a general-purpose world model, paving the way for robust and unified autonomous driving frameworks.
An End-to-End Learning-Based Multi-Sensor Fusion for Autonomous Vehicle Localization
Mar 07, 2025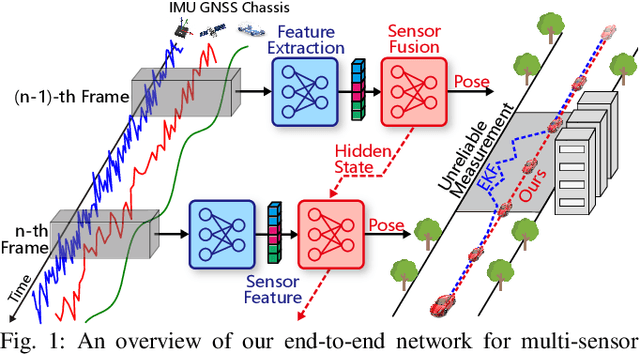
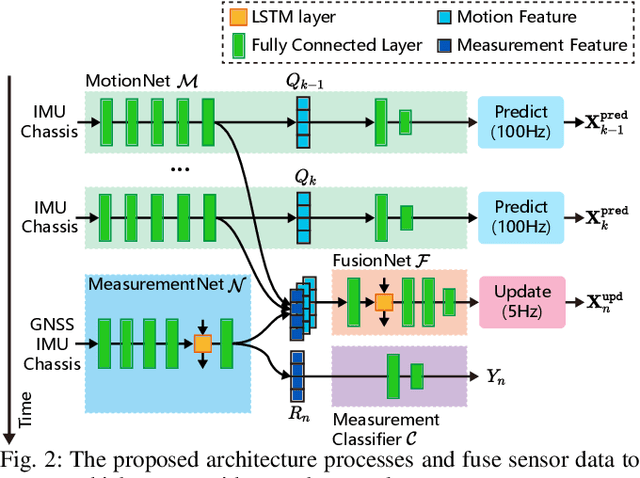
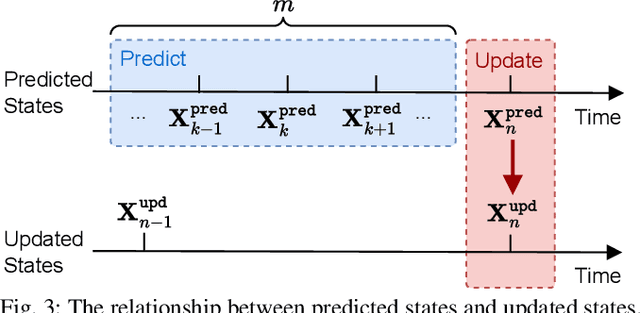

Multi-sensor fusion is essential for autonomous vehicle localization, as it is capable of integrating data from various sources for enhanced accuracy and reliability. The accuracy of the integrated location and orientation depends on the precision of the uncertainty modeling. Traditional methods of uncertainty modeling typically assume a Gaussian distribution and involve manual heuristic parameter tuning. However, these methods struggle to scale effectively and address long-tail scenarios. To address these challenges, we propose a learning-based method that encodes sensor information using higher-order neural network features, thereby eliminating the need for uncertainty estimation. This method significantly eliminates the need for parameter fine-tuning by developing an end-to-end neural network that is specifically designed for multi-sensor fusion. In our experiments, we demonstrate the effectiveness of our approach in real-world autonomous driving scenarios. Results show that the proposed method outperforms existing multi-sensor fusion methods in terms of both accuracy and robustness. A video of the results can be viewed at https://youtu.be/q4iuobMbjME.
DiffMap: Enhancing Map Segmentation with Map Prior Using Diffusion Model
May 03, 2024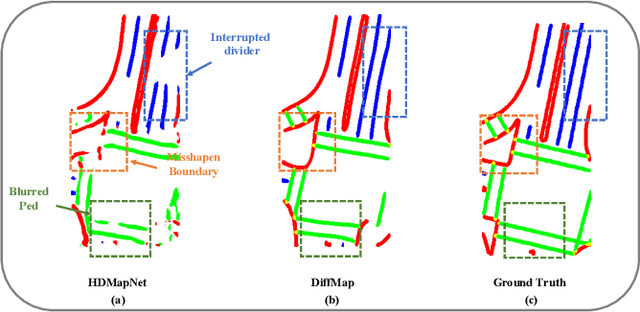
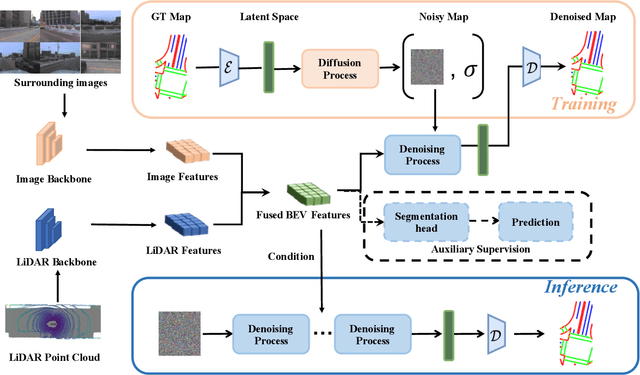
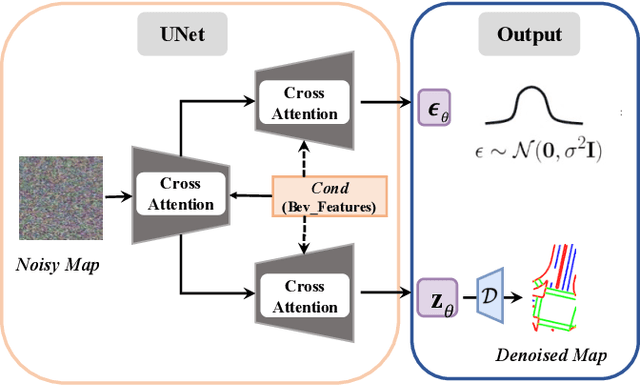

Constructing high-definition (HD) maps is a crucial requirement for enabling autonomous driving. In recent years, several map segmentation algorithms have been developed to address this need, leveraging advancements in Bird's-Eye View (BEV) perception. However, existing models still encounter challenges in producing realistic and consistent semantic map layouts. One prominent issue is the limited utilization of structured priors inherent in map segmentation masks. In light of this, we propose DiffMap, a novel approach specifically designed to model the structured priors of map segmentation masks using latent diffusion model. By incorporating this technique, the performance of existing semantic segmentation methods can be significantly enhanced and certain structural errors present in the segmentation outputs can be effectively rectified. Notably, the proposed module can be seamlessly integrated into any map segmentation model, thereby augmenting its capability to accurately delineate semantic information. Furthermore, through extensive visualization analysis, our model demonstrates superior proficiency in generating results that more accurately reflect real-world map layouts, further validating its efficacy in improving the quality of the generated maps.
Transferring CLIP's Knowledge into Zero-Shot Point Cloud Semantic Segmentation
Dec 12, 2023



Traditional 3D segmentation methods can only recognize a fixed range of classes that appear in the training set, which limits their application in real-world scenarios due to the lack of generalization ability. Large-scale visual-language pre-trained models, such as CLIP, have shown their generalization ability in the zero-shot 2D vision tasks, but are still unable to be applied to 3D semantic segmentation directly. In this work, we focus on zero-shot point cloud semantic segmentation and propose a simple yet effective baseline to transfer the visual-linguistic knowledge implied in CLIP to point cloud encoder at both feature and output levels. Both feature-level and output-level alignments are conducted between 2D and 3D encoders for effective knowledge transfer. Concretely, a Multi-granularity Cross-modal Feature Alignment (MCFA) module is proposed to align 2D and 3D features from global semantic and local position perspectives for feature-level alignment. For the output level, per-pixel pseudo labels of unseen classes are extracted using the pre-trained CLIP model as supervision for the 3D segmentation model to mimic the behavior of the CLIP image encoder. Extensive experiments are conducted on two popular benchmarks of point cloud segmentation. Our method outperforms significantly previous state-of-the-art methods under zero-shot setting (+29.2% mIoU on SemanticKITTI and 31.8% mIoU on nuScenes), and further achieves promising results in the annotation-free point cloud semantic segmentation setting, showing its great potential for label-efficient learning.
MultiSPANS: A Multi-range Spatial-Temporal Transformer Network for Traffic Forecast via Structural Entropy Optimization
Nov 06, 2023



Traffic forecasting is a complex multivariate time-series regression task of paramount importance for traffic management and planning. However, existing approaches often struggle to model complex multi-range dependencies using local spatiotemporal features and road network hierarchical knowledge. To address this, we propose MultiSPANS. First, considering that an individual recording point cannot reflect critical spatiotemporal local patterns, we design multi-filter convolution modules for generating informative ST-token embeddings to facilitate attention computation. Then, based on ST-token and spatial-temporal position encoding, we employ the Transformers to capture long-range temporal and spatial dependencies. Furthermore, we introduce structural entropy theory to optimize the spatial attention mechanism. Specifically, The structural entropy minimization algorithm is used to generate optimal road network hierarchies, i.e., encoding trees. Based on this, we propose a relative structural entropy-based position encoding and a multi-head attention masking scheme based on multi-layer encoding trees. Extensive experiments demonstrate the superiority of the presented framework over several state-of-the-art methods in real-world traffic datasets, and the longer historical windows are effectively utilized. The code is available at https://github.com/SELGroup/MultiSPANS.
Learning Point-wise Abstaining Penalty for Point Cloud Anomaly Detection
Sep 20, 2023



LiDAR-based semantic scene understanding is an important module in the modern autonomous driving perception stack. However, identifying Out-Of-Distribution (OOD) points in a LiDAR point cloud is challenging as point clouds lack semantically rich features when compared with RGB images. We revisit this problem from the perspective of selective classification, which introduces a selective function into the standard closed-set classification setup. Our solution is built upon the basic idea of abstaining from choosing any known categories but learns a point-wise abstaining penalty with a marginbased loss. Synthesizing outliers to approximate unlimited OOD samples is also critical to this idea, so we propose a strong synthesis pipeline that generates outliers originated from various factors: unrealistic object categories, sampling patterns and sizes. We demonstrate that learning different abstaining penalties, apart from point-wise penalty, for different types of (synthesized) outliers can further improve the performance. We benchmark our method on SemanticKITTI and nuScenes and achieve state-of-the-art results. Risk-coverage analysis further reveals intrinsic properties of different methods. Codes and models will be publicly available.
Delving into Shape-aware Zero-shot Semantic Segmentation
Apr 17, 2023



Thanks to the impressive progress of large-scale vision-language pretraining, recent recognition models can classify arbitrary objects in a zero-shot and open-set manner, with a surprisingly high accuracy. However, translating this success to semantic segmentation is not trivial, because this dense prediction task requires not only accurate semantic understanding but also fine shape delineation and existing vision-language models are trained with image-level language descriptions. To bridge this gap, we pursue \textbf{shape-aware} zero-shot semantic segmentation in this study. Inspired by classical spectral methods in the image segmentation literature, we propose to leverage the eigen vectors of Laplacian matrices constructed with self-supervised pixel-wise features to promote shape-awareness. Despite that this simple and effective technique does not make use of the masks of seen classes at all, we demonstrate that it out-performs a state-of-the-art shape-aware formulation that aligns ground truth and predicted edges during training. We also delve into the performance gains achieved on different datasets using different backbones and draw several interesting and conclusive observations: the benefits of promoting shape-awareness highly relates to mask compactness and language embedding locality. Finally, our method sets new state-of-the-art performance for zero-shot semantic segmentation on both Pascal and COCO, with significant margins. Code and models will be accessed at https://github.com/Liuxinyv/SAZS.