 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGarment Inertial Denoiser (GID): Endowing Accurate Motion Capture via Loose IMU Denoiser
Jan 04, 2026Wearable inertial motion capture (MoCap) provides a portable, occlusion-free, and privacy-preserving alternative to camera-based systems, but its accuracy depends on tightly attached sensors - an intrusive and uncomfortable requirement for daily use. Embedding IMUs into loose-fitting garments is a desirable alternative, yet sensor-body displacement introduces severe, structured, and location-dependent corruption that breaks standard inertial pipelines. We propose GID (Garment Inertial Denoiser), a lightweight, plug-and-play Transformer that factorizes loose-wear MoCap into three stages: (i) location-specific denoising, (ii) adaptive cross-wear fusion, and (iii) general pose prediction. GID uses a location-aware expert architecture, where a shared spatio-temporal backbone models global motion while per-IMU expert heads specialize in local garment dynamics, and a lightweight fusion module ensures cross-part consistency. This inductive bias enables stable training and effective learning from limited paired loose-tight IMU data. We also introduce GarMoCap, a combined public and newly collected dataset covering diverse users, motions, and garments. Experiments show that GID enables accurate, real-time denoising from single-user training and generalizes across unseen users, motions, and garment types, consistently improving state-of-the-art inertial MoCap methods when used as a drop-in module.
Transformer IMU Calibrator: Dynamic On-body IMU Calibration for Inertial Motion Capture
Jun 12, 2025In this paper, we propose a novel dynamic calibration method for sparse inertial motion capture systems, which is the first to break the restrictive absolute static assumption in IMU calibration, i.e., the coordinate drift RG'G and measurement offset RBS remain constant during the entire motion, thereby significantly expanding their application scenarios. Specifically, we achieve real-time estimation of RG'G and RBS under two relaxed assumptions: i) the matrices change negligibly in a short time window; ii) the human movements/IMU readings are diverse in such a time window. Intuitively, the first assumption reduces the number of candidate matrices, and the second assumption provides diverse constraints, which greatly reduces the solution space and allows for accurate estimation of RG'G and RBS from a short history of IMU readings in real time. To achieve this, we created synthetic datasets of paired RG'G, RBS matrices and IMU readings, and learned their mappings using a Transformer-based model. We also designed a calibration trigger based on the diversity of IMU readings to ensure that assumption ii) is met before applying our method. To our knowledge, we are the first to achieve implicit IMU calibration (i.e., seamlessly putting IMUs into use without the need for an explicit calibration process), as well as the first to enable long-term and accurate motion capture using sparse IMUs. The code and dataset are available at https://github.com/ZuoCX1996/TIC.
SuDA: Support-based Domain Adaptation for Sim2Real Motion Capture with Flexible Sensors
May 25, 2024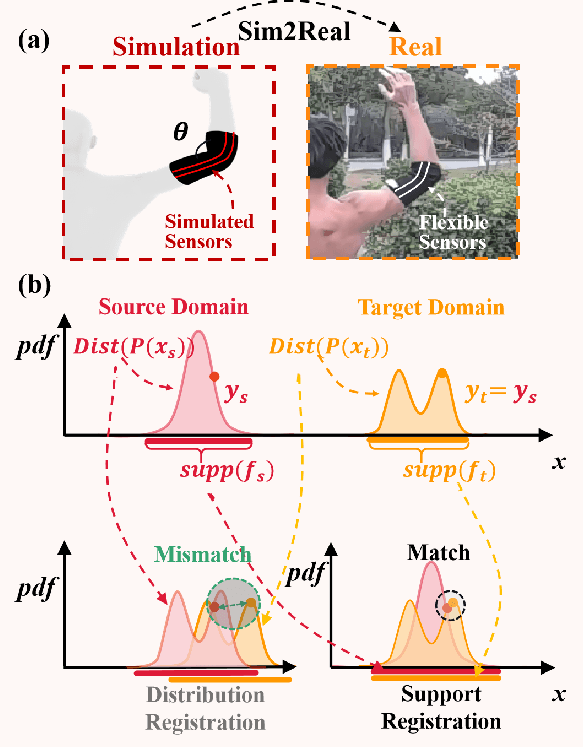

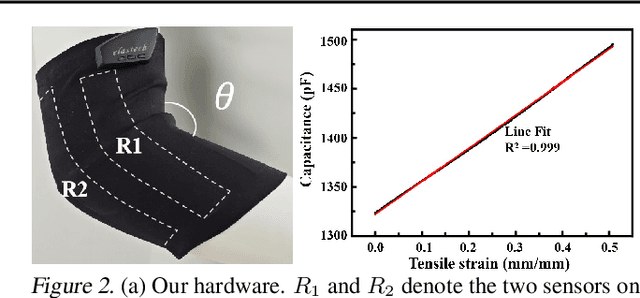
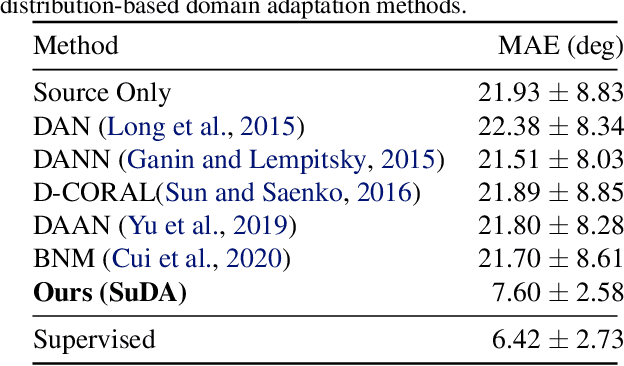
Flexible sensors hold promise for human motion capture (MoCap), offering advantages such as wearability, privacy preservation, and minimal constraints on natural movement. However, existing flexible sensor-based MoCap methods rely on deep learning and necessitate large and diverse labeled datasets for training. These data typically need to be collected in MoCap studios with specialized equipment and substantial manual labor, making them difficult and expensive to obtain at scale. Thanks to the high-linearity of flexible sensors, we address this challenge by proposing a novel Sim2Real Mocap solution based on domain adaptation, eliminating the need for labeled data yet achieving comparable accuracy to supervised learning. Our solution relies on a novel Support-based Domain Adaptation method, namely SuDA, which aligns the supports of the predictive functions rather than the instance-dependent distributions between the source and target domains. Extensive experimental results demonstrate the effectiveness of our method andits superiority over state-of-the-art distribution-based domain adaptation methods in our task.
Learning Point-wise Abstaining Penalty for Point Cloud Anomaly Detection
Sep 20, 2023LiDAR-based semantic scene understanding is an important module in the modern autonomous driving perception stack. However, identifying Out-Of-Distribution (OOD) points in a LiDAR point cloud is challenging as point clouds lack semantically rich features when compared with RGB images. We revisit this problem from the perspective of selective classification, which introduces a selective function into the standard closed-set classification setup. Our solution is built upon the basic idea of abstaining from choosing any known categories but learns a point-wise abstaining penalty with a marginbased loss. Synthesizing outliers to approximate unlimited OOD samples is also critical to this idea, so we propose a strong synthesis pipeline that generates outliers originated from various factors: unrealistic object categories, sampling patterns and sizes. We demonstrate that learning different abstaining penalties, apart from point-wise penalty, for different types of (synthesized) outliers can further improve the performance. We benchmark our method on SemanticKITTI and nuScenes and achieve state-of-the-art results. Risk-coverage analysis further reveals intrinsic properties of different methods. Codes and models will be publicly available.
TOPIC: A Parallel Association Paradigm for Multi-Object Tracking under Complex Motions and Diverse Scenes
Aug 22, 2023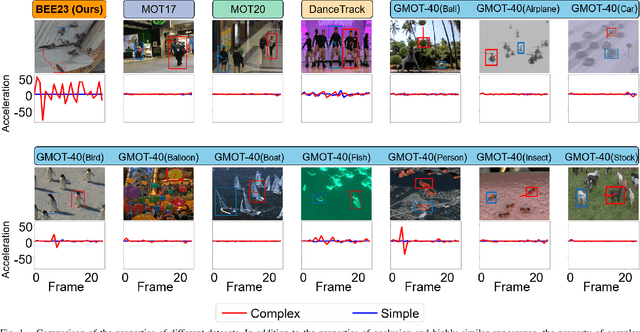
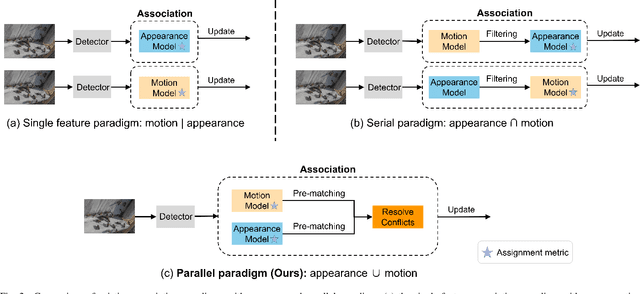


Video data and algorithms have been driving advances in multi-object tracking (MOT). While existing MOT datasets focus on occlusion and appearance similarity, complex motion patterns are widespread yet overlooked. To address this issue, we introduce a new dataset called BEE23 to highlight complex motions. Identity association algorithms have long been the focus of MOT research. Existing trackers can be categorized into two association paradigms: single-feature paradigm (based on either motion or appearance feature) and serial paradigm (one feature serves as secondary while the other is primary). However, these paradigms are incapable of fully utilizing different features. In this paper, we propose a parallel paradigm and present the Two rOund Parallel matchIng meChanism (TOPIC) to implement it. The TOPIC leverages both motion and appearance features and can adaptively select the preferable one as the assignment metric based on motion level. Moreover, we provide an Attention-based Appearance Reconstruct Module (AARM) to reconstruct appearance feature embeddings, thus enhancing the representation of appearance features. Comprehensive experiments show that our approach achieves state-of-the-art performance on four public datasets and BEE23. Notably, our proposed parallel paradigm surpasses the performance of existing association paradigms by a large margin, e.g., reducing false negatives by 12% to 51% compared to the single-feature association paradigm. The introduced dataset and association paradigm in this work offers a fresh perspective for advancing the MOT field. The source code and dataset are available at https://github.com/holmescao/TOPICTrack.
Motion-R3: Fast and Accurate Motion Annotation via Representation-based Representativeness Ranking
Apr 04, 2023



In this paper, we follow a data-centric philosophy and propose a novel motion annotation method based on the inherent representativeness of motion data in a given dataset. Specifically, we propose a Representation-based Representativeness Ranking R3 method that ranks all motion data in a given dataset according to their representativeness in a learned motion representation space. We further propose a novel dual-level motion constrastive learning method to learn the motion representation space in a more informative way. Thanks to its high efficiency, our method is particularly responsive to frequent requirements change and enables agile development of motion annotation models. Experimental results on the HDM05 dataset against state-of-the-art methods demonstrate the superiority of our method.
Diverse Motion In-betweening with Dual Posture Stitching
Mar 25, 2023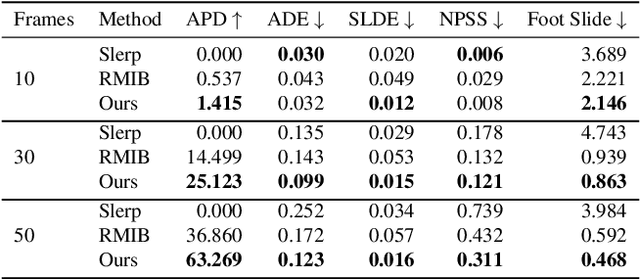
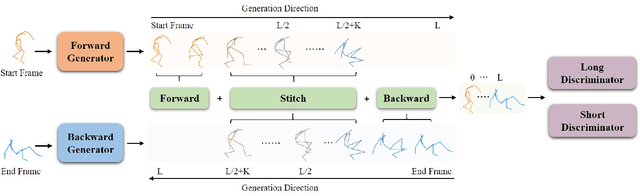
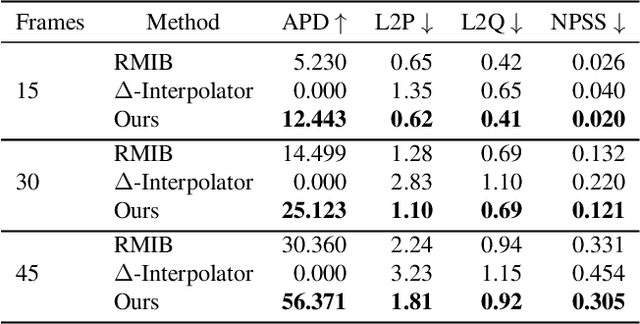
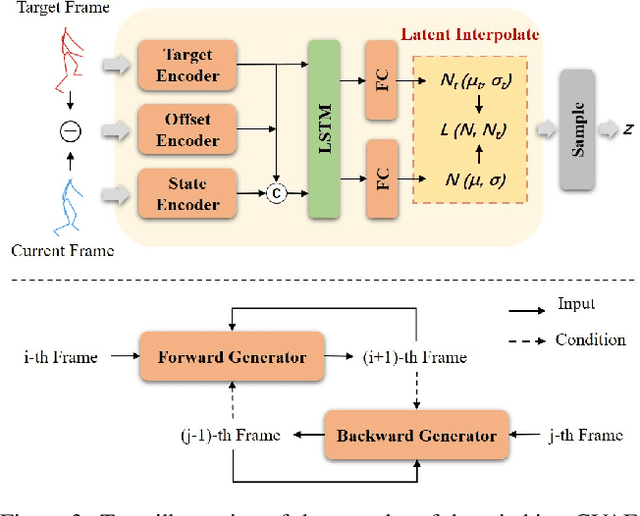
In-betweening is a technique for generating transitions given initial and target character states. The majority of existing works require multiple (often $>$10) frames as input, which are not always accessible. Our work deals with a focused yet challenging problem: to generate the transition when given exactly two frames (only the first and last). To cope with this challenging scenario, we implement our bi-directional scheme which generates forward and backward transitions from the start and end frames with two adversarial autoregressive networks, and stitches them in the middle of the transition where there is no strict ground truth. The autoregressive networks based on conditional variational autoencoders (CVAE) are optimized by searching for a pair of optimal latent codes that minimize a novel stitching loss between their outputs. Results show that our method achieves higher motion quality and more diverse results than existing methods on both the LaFAN1 and Human3.6m datasets.
Enable Natural Tactile Interaction for Robot Dog based on Large-format Distributed Flexible Pressure Sensors
Mar 14, 2023



Touch is an important channel for human-robot interaction, while it is challenging for robots to recognize human touch accurately and make appropriate responses. In this paper, we design and implement a set of large-format distributed flexible pressure sensors on a robot dog to enable natural human-robot tactile interaction. Through a heuristic study, we sorted out 81 tactile gestures commonly used when humans interact with real dogs and 44 dog reactions. A gesture classification algorithm based on ResNet is proposed to recognize these 81 human gestures, and the classification accuracy reaches 98.7%. In addition, an action prediction algorithm based on Transformer is proposed to predict dog actions from human gestures, reaching a 1-gram BLEU score of 0.87. Finally, we compare the tactile interaction with the voice interaction during a freedom human-robot-dog interactive playing study. The results show that tactile interaction plays a more significant role in alleviating user anxiety, stimulating user excitement and improving the acceptability of robot dogs.
* 7 pages, 5 figures
A dataset of ant colonies motion trajectories in indoor and outdoor scenes for social cluster behavior study
Apr 09, 2022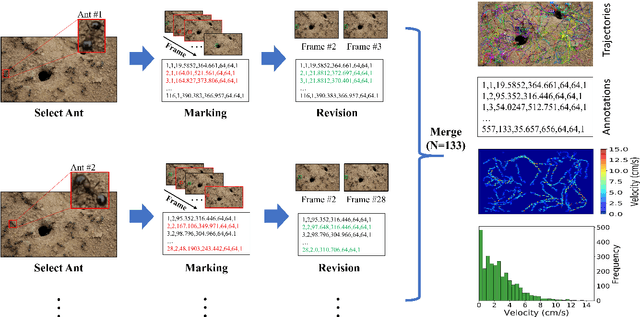
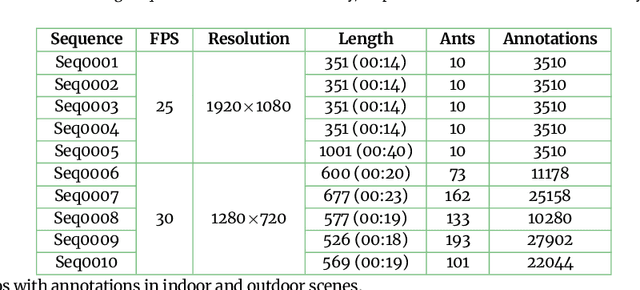
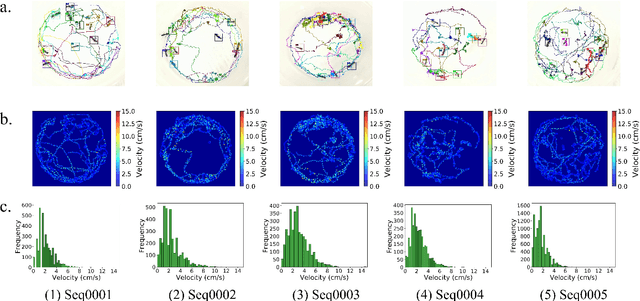
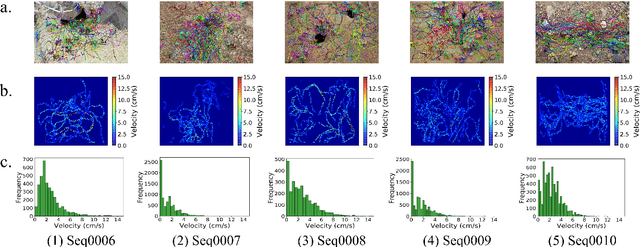
Motion and interaction of social insects (such as ants) have been studied by many researchers to understand the clustering mechanism. Most studies in the field of ant behavior have only focused on indoor environments, while outdoor environments are still underexplored. In this paper, we collect 10 videos of ant colonies from different indoor and outdoor scenes. And we develop an image sequence marking software named VisualMarkData, which enables us to provide annotations of ants in the video. In all 5354 frames, the location information and the identification number of each ant are recorded for a total of 712 ants and 114112 annotations. Moreover, we provide visual analysis tools to assess and validate the technical quality and reproducibility of our data. It is hoped that this dataset will contribute to a deeper exploration on the behavior of the ant colony.
Swarm behavior tracking based on a deep vision algorithm
Apr 07, 2022
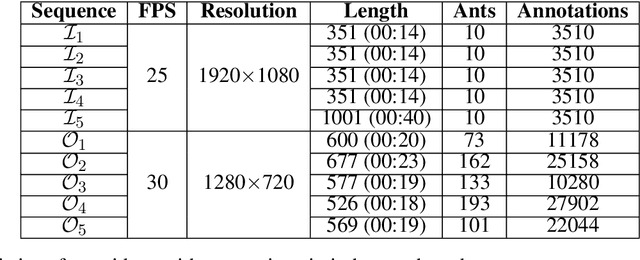
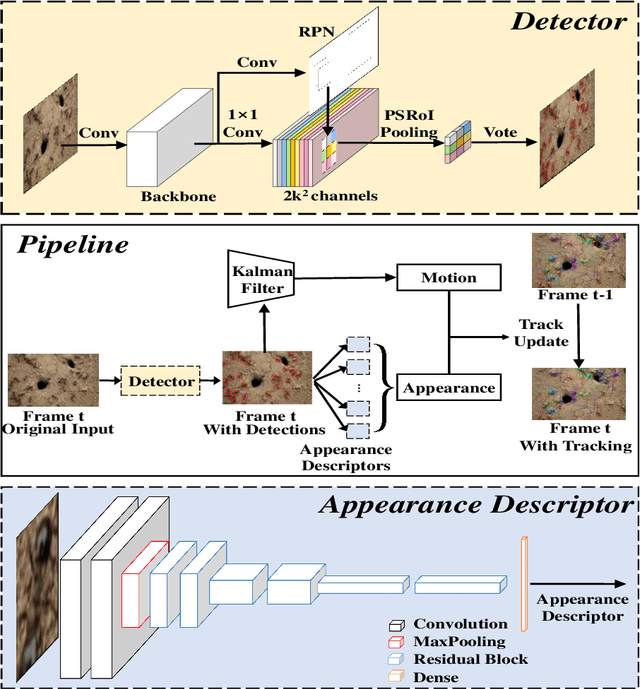
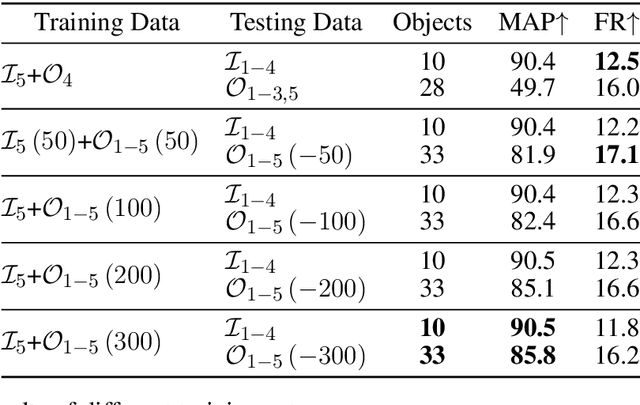
The intelligent swarm behavior of social insects (such as ants) springs up in different environments, promising to provide insights for the study of embodied intelligence. Researching swarm behavior requires that researchers could accurately track each individual over time. Obviously, manually labeling individual insects in a video is labor-intensive. Automatic tracking methods, however, also poses serious challenges: (1) individuals are small and similar in appearance; (2) frequent interactions with each other cause severe and long-term occlusion. With the advances of artificial intelligence and computing vision technologies, we are hopeful to provide a tool to automate monitor multiple insects to address the above challenges. In this paper, we propose a detection and tracking framework for multi-ant tracking in the videos by: (1) adopting a two-stage object detection framework using ResNet-50 as backbone and coding the position of regions of interest to locate ants accurately; (2) using the ResNet model to develop the appearance descriptors of ants; (3) constructing long-term appearance sequences and combining them with motion information to achieve online tracking. To validate our method, we construct an ant database including 10 videos of ants from different indoor and outdoor scenes. We achieve a state-of-the-art performance of 95.7\% mMOTA and 81.1\% mMOTP in indoor videos, 81.8\% mMOTA and 81.9\% mMOTP in outdoor videos. Additionally, Our method runs 6-10 times faster than existing methods for insect tracking. Experimental results demonstrate that our method provides a powerful tool for accelerating the unraveling of the mechanisms underlying the swarm behavior of social insects.