 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGR-Dexter Technical Report
Dec 30, 2025Vision-language-action (VLA) models have enabled language-conditioned, long-horizon robot manipulation, but most existing systems are limited to grippers. Scaling VLA policies to bimanual robots with high degree-of-freedom (DoF) dexterous hands remains challenging due to the expanded action space, frequent hand-object occlusions, and the cost of collecting real-robot data. We present GR-Dexter, a holistic hardware-model-data framework for VLA-based generalist manipulation on a bimanual dexterous-hand robot. Our approach combines the design of a compact 21-DoF robotic hand, an intuitive bimanual teleoperation system for real-robot data collection, and a training recipe that leverages teleoperated robot trajectories together with large-scale vision-language and carefully curated cross-embodiment datasets. Across real-world evaluations spanning long-horizon everyday manipulation and generalizable pick-and-place, GR-Dexter achieves strong in-domain performance and improved robustness to unseen objects and unseen instructions. We hope GR-Dexter serves as a practical step toward generalist dexterous-hand robotic manipulation.
Long-horizon Locomotion and Manipulation on a Quadrupedal Robot with Large Language Models
Apr 08, 2024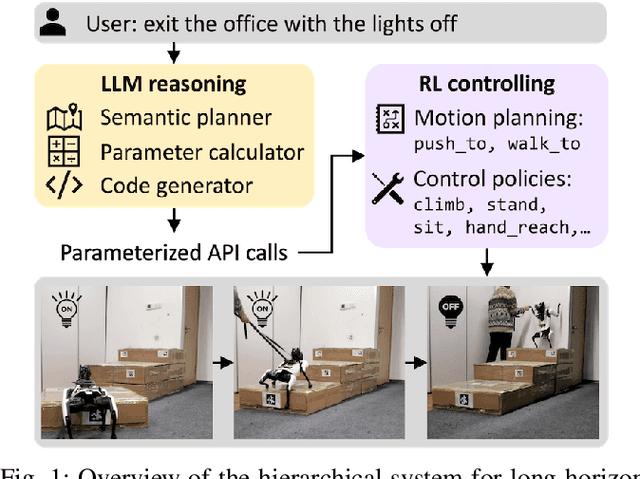



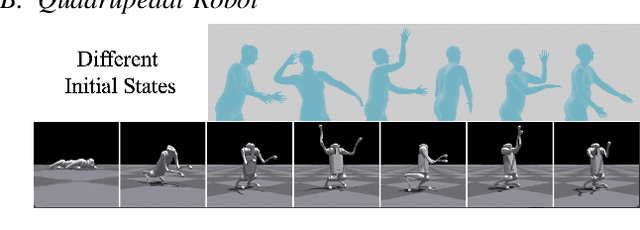
We present a large language model (LLM) based system to empower quadrupedal robots with problem-solving abilities for long-horizon tasks beyond short-term motions. Long-horizon tasks for quadrupeds are challenging since they require both a high-level understanding of the semantics of the problem for task planning and a broad range of locomotion and manipulation skills to interact with the environment. Our system builds a high-level reasoning layer with large language models, which generates hybrid discrete-continuous plans as robot code from task descriptions. It comprises multiple LLM agents: a semantic planner for sketching a plan, a parameter calculator for predicting arguments in the plan, and a code generator to convert the plan into executable robot code. At the low level, we adopt reinforcement learning to train a set of motion planning and control skills to unleash the flexibility of quadrupeds for rich environment interactions. Our system is tested on long-horizon tasks that are infeasible to complete with one single skill. Simulation and real-world experiments show that it successfully figures out multi-step strategies and demonstrates non-trivial behaviors, including building tools or notifying a human for help.
Language-Guided Generation of Physically Realistic Robot Motion and Control
Jun 18, 2023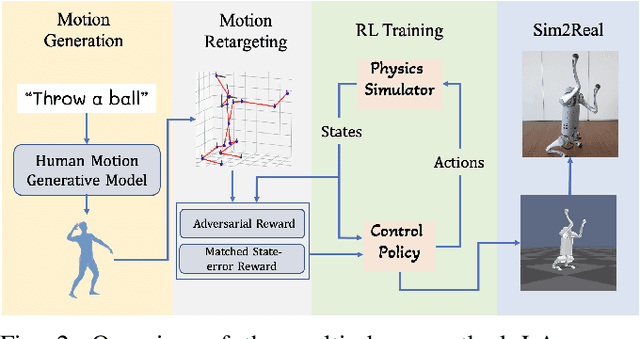
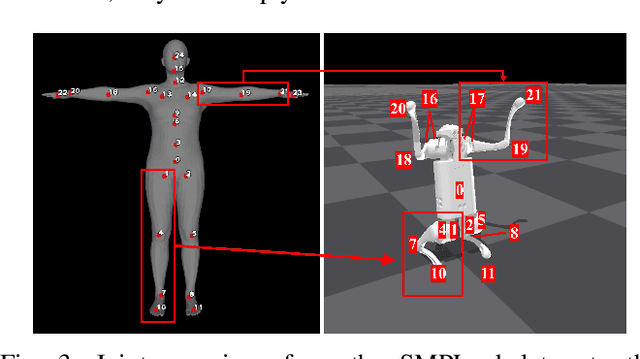
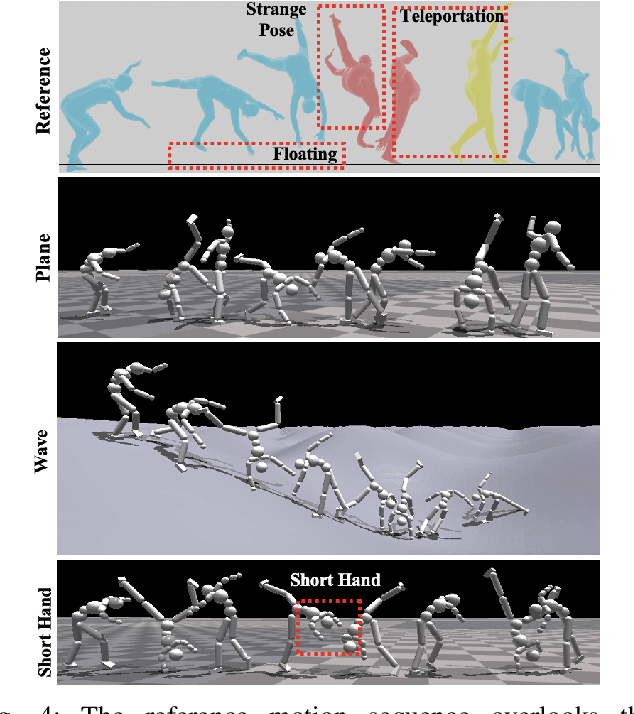
We aim to control a robot to physically behave in the real world following any high-level language command like "cartwheel" or "kick. " Although human motion datasets exist, this task remains particularly challenging since generative models can produce physically unrealistic motions, which will be more severe for robots due to different body structures and physical properties. In addition, to control a physical robot to perform a desired motion, a control policy must be learned. We develop LAnguage-Guided mOtion cONtrol (LAGOON), a multi-phase method to generate physically realistic robot motions under language commands. LAGOON first leverages a pre-trained model to generate human motion from a language command. Then an RL phase is adopted to train a control policy in simulation to mimic the generated human motion. Finally, with domain randomization, we show that our learned policy can be successfully deployed to a quadrupedal robot, leading to a robot dog that can stand up and wave its front legs in the real world to mimic the behavior of a hand-waving human.
Diverse Motion In-betweening with Dual Posture Stitching
Mar 25, 2023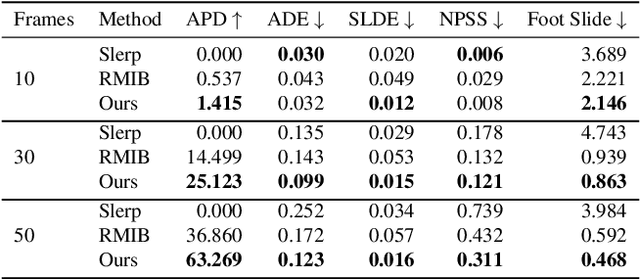
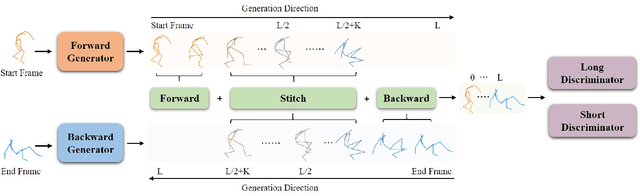
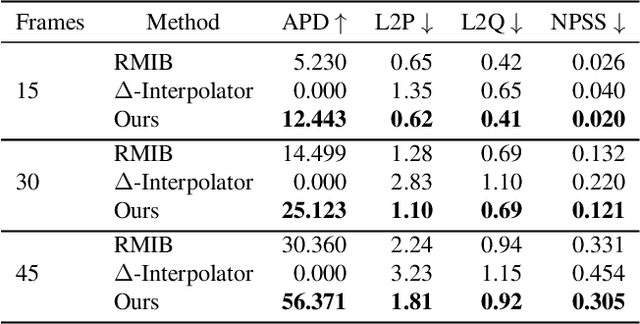
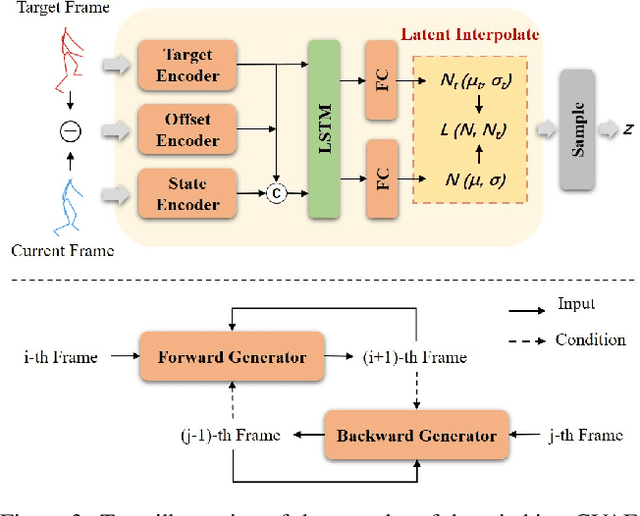
In-betweening is a technique for generating transitions given initial and target character states. The majority of existing works require multiple (often $>$10) frames as input, which are not always accessible. Our work deals with a focused yet challenging problem: to generate the transition when given exactly two frames (only the first and last). To cope with this challenging scenario, we implement our bi-directional scheme which generates forward and backward transitions from the start and end frames with two adversarial autoregressive networks, and stitches them in the middle of the transition where there is no strict ground truth. The autoregressive networks based on conditional variational autoencoders (CVAE) are optimized by searching for a pair of optimal latent codes that minimize a novel stitching loss between their outputs. Results show that our method achieves higher motion quality and more diverse results than existing methods on both the LaFAN1 and Human3.6m datasets.