 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWATCH: World-aware Allied Trajectory and pose reconstruction for Camera and Human
Sep 04, 2025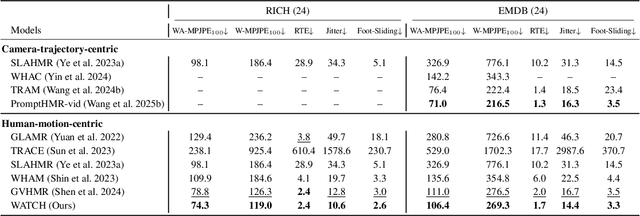
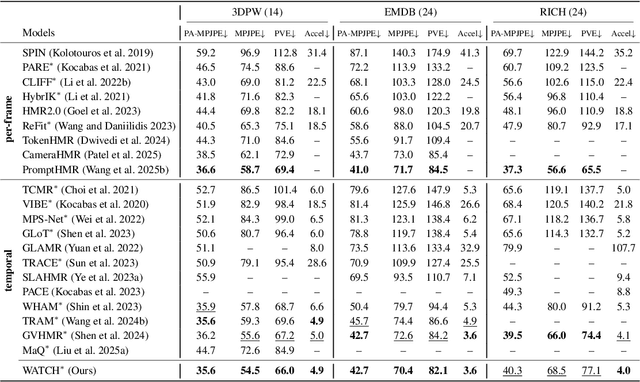

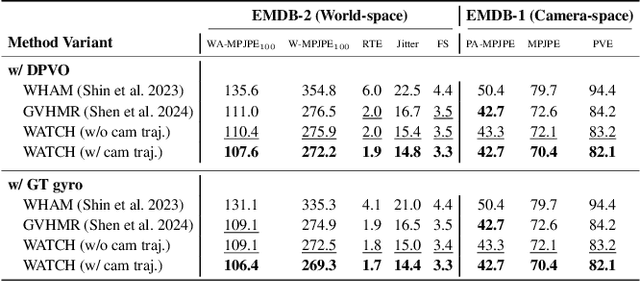
Global human motion reconstruction from in-the-wild monocular videos is increasingly demanded across VR, graphics, and robotics applications, yet requires accurate mapping of human poses from camera to world coordinates-a task challenged by depth ambiguity, motion ambiguity, and the entanglement between camera and human movements. While human-motion-centric approaches excel in preserving motion details and physical plausibility, they suffer from two critical limitations: insufficient exploitation of camera orientation information and ineffective integration of camera translation cues. We present WATCH (World-aware Allied Trajectory and pose reconstruction for Camera and Human), a unified framework addressing both challenges. Our approach introduces an analytical heading angle decomposition technique that offers superior efficiency and extensibility compared to existing geometric methods. Additionally, we design a camera trajectory integration mechanism inspired by world models, providing an effective pathway for leveraging camera translation information beyond naive hard-decoding approaches. Through experiments on in-the-wild benchmarks, WATCH achieves state-of-the-art performance in end-to-end trajectory reconstruction. Our work demonstrates the effectiveness of jointly modeling camera-human motion relationships and offers new insights for addressing the long-standing challenge of camera translation integration in global human motion reconstruction. The code will be available publicly.
EmoFace: Audio-driven Emotional 3D Face Animation
Jul 17, 2024



Audio-driven emotional 3D face animation aims to generate emotionally expressive talking heads with synchronized lip movements. However, previous research has often overlooked the influence of diverse emotions on facial expressions or proved unsuitable for driving MetaHuman models. In response to this deficiency, we introduce EmoFace, a novel audio-driven methodology for creating facial animations with vivid emotional dynamics. Our approach can generate facial expressions with multiple emotions, and has the ability to generate random yet natural blinks and eye movements, while maintaining accurate lip synchronization. We propose independent speech encoders and emotion encoders to learn the relationship between audio, emotion and corresponding facial controller rigs, and finally map into the sequence of controller values. Additionally, we introduce two post-processing techniques dedicated to enhancing the authenticity of the animation, particularly in blinks and eye movements. Furthermore, recognizing the scarcity of emotional audio-visual data suitable for MetaHuman model manipulation, we contribute an emotional audio-visual dataset and derive control parameters for each frames. Our proposed methodology can be applied in producing dialogues animations of non-playable characters (NPCs) in video games, and driving avatars in virtual reality environments. Our further quantitative and qualitative experiments, as well as an user study comparing with existing researches show that our approach demonstrates superior results in driving 3D facial models. The code and sample data are available at https://github.com/SJTU-Lucy/EmoFace.
SyncDreamer: Generating Multiview-consistent Images from a Single-view Image
Sep 07, 2023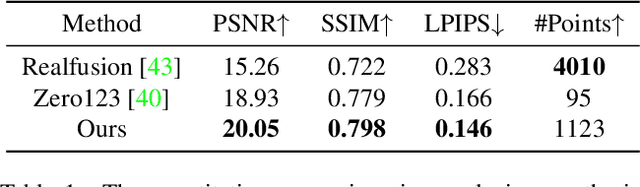



In this paper, we present a novel diffusion model called that generates multiview-consistent images from a single-view image. Using pretrained large-scale 2D diffusion models, recent work Zero123 demonstrates the ability to generate plausible novel views from a single-view image of an object. However, maintaining consistency in geometry and colors for the generated images remains a challenge. To address this issue, we propose a synchronized multiview diffusion model that models the joint probability distribution of multiview images, enabling the generation of multiview-consistent images in a single reverse process. SyncDreamer synchronizes the intermediate states of all the generated images at every step of the reverse process through a 3D-aware feature attention mechanism that correlates the corresponding features across different views. Experiments show that SyncDreamer generates images with high consistency across different views, thus making it well-suited for various 3D generation tasks such as novel-view-synthesis, text-to-3D, and image-to-3D.
Motion-R3: Fast and Accurate Motion Annotation via Representation-based Representativeness Ranking
Apr 04, 2023



In this paper, we follow a data-centric philosophy and propose a novel motion annotation method based on the inherent representativeness of motion data in a given dataset. Specifically, we propose a Representation-based Representativeness Ranking R3 method that ranks all motion data in a given dataset according to their representativeness in a learned motion representation space. We further propose a novel dual-level motion constrastive learning method to learn the motion representation space in a more informative way. Thanks to its high efficiency, our method is particularly responsive to frequent requirements change and enables agile development of motion annotation models. Experimental results on the HDM05 dataset against state-of-the-art methods demonstrate the superiority of our method.
Diverse Motion In-betweening with Dual Posture Stitching
Mar 25, 2023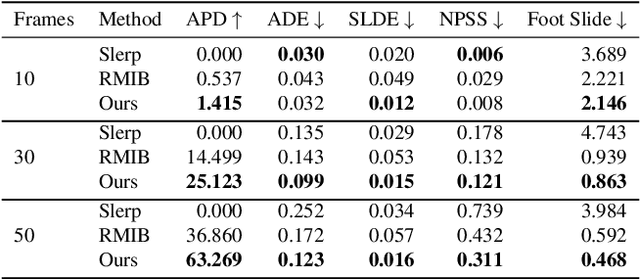
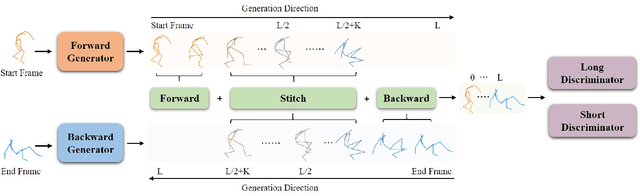
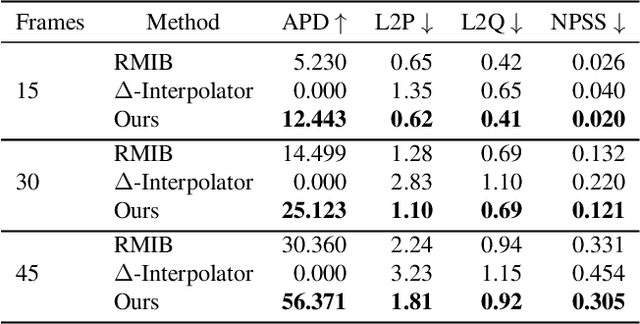
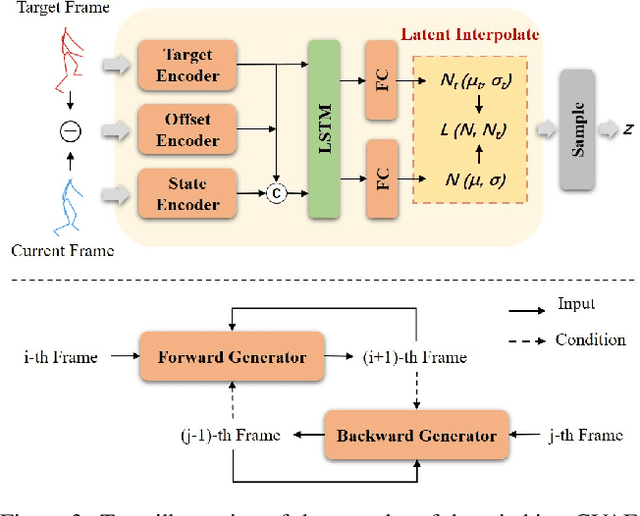
In-betweening is a technique for generating transitions given initial and target character states. The majority of existing works require multiple (often $>$10) frames as input, which are not always accessible. Our work deals with a focused yet challenging problem: to generate the transition when given exactly two frames (only the first and last). To cope with this challenging scenario, we implement our bi-directional scheme which generates forward and backward transitions from the start and end frames with two adversarial autoregressive networks, and stitches them in the middle of the transition where there is no strict ground truth. The autoregressive networks based on conditional variational autoencoders (CVAE) are optimized by searching for a pair of optimal latent codes that minimize a novel stitching loss between their outputs. Results show that our method achieves higher motion quality and more diverse results than existing methods on both the LaFAN1 and Human3.6m datasets.