 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiAct: Text-to-Motion Generation from Composite Text via Tailored Attention Guidance
May 29, 2026Text-to-motion generation has progressed rapidly in recent years, offering an expressive interface for animation and human-computer interaction. However, current models remain brittle when handling prompts that describe multiple actions occurring at the same time. Rather than realizing all components of a composite description, models frequently prioritize a single dominant action and neglect the rest, leading to incomplete or ambiguous motion. We present MultiAct, an unpaired, inference-time framework for compositional text-to-motion synthesis that operates directly on pretrained motion generators without retraining or architectural modification. Our method counteracts semantic collapse by adaptively amplifying cross-attention scores associated with underrepresented prompt components. We note that effective modulation depends on prompt-specific choices, such as which tokens and layers to target, and introduce a lightweight auxiliary decision scheme that determines the most effective attention-strengthening parametrization. Extensive quantitative and qualitative evaluations demonstrate that MultiAct consistently outperforms existing baselines on composite prompts, achieving improved semantic coverage while preserving motion realism. Project page: https://natsala13.github.io/multiact.github.io.
Mocap Anywhere: Towards Pairwise-Distance based Motion Capture in the Wild (for the Wild)
Jan 27, 2026We introduce a novel motion capture system that reconstructs full-body 3D motion using only sparse pairwise distance (PWD) measurements from body-mounted(UWB) sensors. Using time-of-flight ranging between wireless nodes, our method eliminates the need for external cameras, enabling robust operation in uncontrolled and outdoor environments. Unlike traditional optical or inertial systems, our approach is shape-invariant and resilient to environmental constraints such as lighting and magnetic interference. At the core of our system is Wild-Poser (WiP for short), a compact, real-time Transformer-based architecture that directly predicts 3D joint positions from noisy or corrupted PWD measurements, which can later be used for joint rotation reconstruction via learned methods. WiP generalizes across subjects of varying morphologies, including non-human species, without requiring individual body measurements or shape fitting. Operating in real time, WiP achieves low joint position error and demonstrates accurate 3D motion reconstruction for both human and animal subjects in-the-wild. Our empirical analysis highlights its potential for scalable, low-cost, and general purpose motion capture in real-world settings.
SparsePoser: Real-time Full-body Motion Reconstruction from Sparse Data
Nov 03, 2023
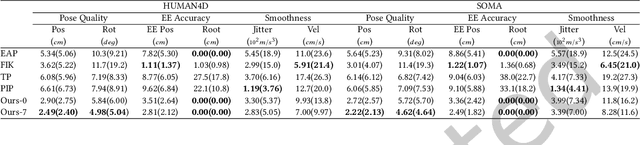

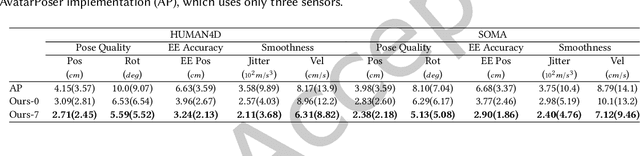
Accurate and reliable human motion reconstruction is crucial for creating natural interactions of full-body avatars in Virtual Reality (VR) and entertainment applications. As the Metaverse and social applications gain popularity, users are seeking cost-effective solutions to create full-body animations that are comparable in quality to those produced by commercial motion capture systems. In order to provide affordable solutions, though, it is important to minimize the number of sensors attached to the subject's body. Unfortunately, reconstructing the full-body pose from sparse data is a heavily under-determined problem. Some studies that use IMU sensors face challenges in reconstructing the pose due to positional drift and ambiguity of the poses. In recent years, some mainstream VR systems have released 6-degree-of-freedom (6-DoF) tracking devices providing positional and rotational information. Nevertheless, most solutions for reconstructing full-body poses rely on traditional inverse kinematics (IK) solutions, which often produce non-continuous and unnatural poses. In this article, we introduce SparsePoser, a novel deep learning-based solution for reconstructing a full-body pose from a reduced set of six tracking devices. Our system incorporates a convolutional-based autoencoder that synthesizes high-quality continuous human poses by learning the human motion manifold from motion capture data. Then, we employ a learned IK component, made of multiple lightweight feed-forward neural networks, to adjust the hands and feet toward the corresponding trackers. We extensively evaluate our method on publicly available motion capture datasets and with real-time live demos. We show that our method outperforms state-of-the-art techniques using IMU sensors or 6-DoF tracking devices, and can be used for users with different body dimensions and proportions.
Motion-R3: Fast and Accurate Motion Annotation via Representation-based Representativeness Ranking
Apr 04, 2023



In this paper, we follow a data-centric philosophy and propose a novel motion annotation method based on the inherent representativeness of motion data in a given dataset. Specifically, we propose a Representation-based Representativeness Ranking R3 method that ranks all motion data in a given dataset according to their representativeness in a learned motion representation space. We further propose a novel dual-level motion constrastive learning method to learn the motion representation space in a more informative way. Thanks to its high efficiency, our method is particularly responsive to frequent requirements change and enables agile development of motion annotation models. Experimental results on the HDM05 dataset against state-of-the-art methods demonstrate the superiority of our method.
A Hierarchy-Aware Pose Representation for Deep Character Animation
Nov 27, 2021

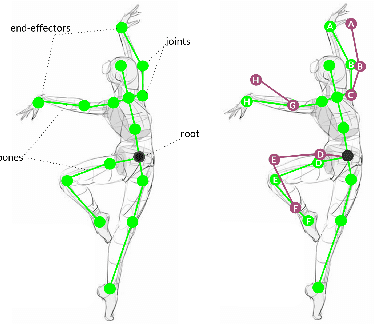

Data-driven character animation techniques rely on the existence of a properly established model of motion, capable of describing its rich context. However, commonly used motion representations often fail to accurately encode the full articulation of motion, or present artifacts. In this work, we address the fundamental problem of finding a robust pose representation for motion modeling, suitable for deep character animation, one that can better constrain poses and faithfully capture nuances correlated with skeletal characteristics. Our representation is based on dual quaternions, the mathematical abstractions with well-defined operations, which simultaneously encode rotational and positional orientation, enabling a hierarchy-aware encoding, centered around the root. We demonstrate that our representation overcomes common motion artifacts, and assess its performance compared to other popular representations. We conduct an ablation study to evaluate the impact of various losses that can be incorporated during learning. Leveraging the fact that our representation implicitly encodes skeletal motion attributes, we train a network on a dataset comprising of skeletons with different proportions, without the need to retarget them first to a universal skeleton, which causes subtle motion elements to be missed. We show that smooth and natural poses can be achieved, paving the way for fascinating applications.
Rhythm is a Dancer: Music-Driven Motion Synthesis with Global Structure
Nov 23, 2021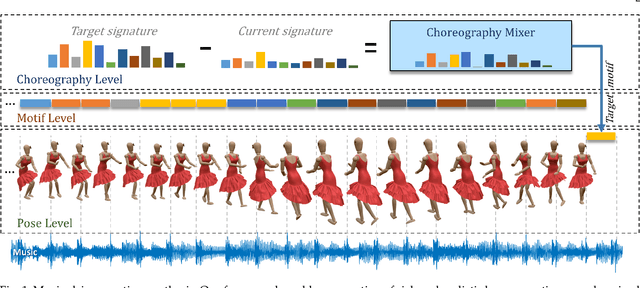
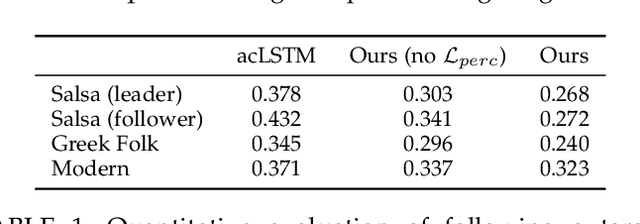
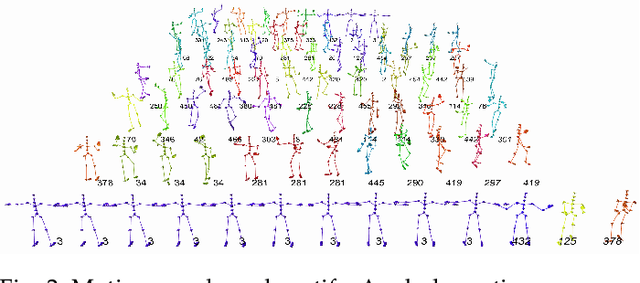
Synthesizing human motion with a global structure, such as a choreography, is a challenging task. Existing methods tend to concentrate on local smooth pose transitions and neglect the global context or the theme of the motion. In this work, we present a music-driven motion synthesis framework that generates long-term sequences of human motions which are synchronized with the input beats, and jointly form a global structure that respects a specific dance genre. In addition, our framework enables generation of diverse motions that are controlled by the content of the music, and not only by the beat. Our music-driven dance synthesis framework is a hierarchical system that consists of three levels: pose, motif, and choreography. The pose level consists of an LSTM component that generates temporally coherent sequences of poses. The motif level guides sets of consecutive poses to form a movement that belongs to a specific distribution using a novel motion perceptual-loss. And the choreography level selects the order of the performed movements and drives the system to follow the global structure of a dance genre. Our results demonstrate the effectiveness of our music-driven framework to generate natural and consistent movements on various dance types, having control over the content of the synthesized motions, and respecting the overall structure of the dance.
MotioNet: 3D Human Motion Reconstruction from Monocular Video with Skeleton Consistency
Jun 22, 2020
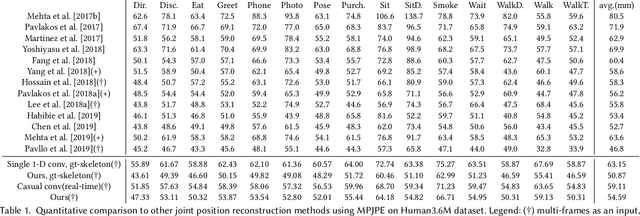

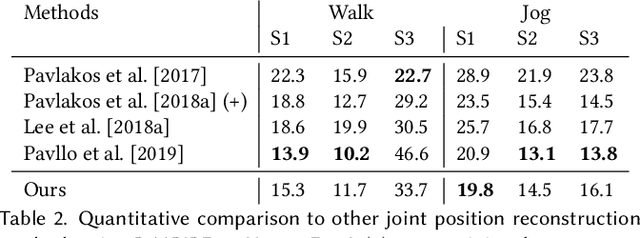
We introduce MotioNet, a deep neural network that directly reconstructs the motion of a 3D human skeleton from monocular video.While previous methods rely on either rigging or inverse kinematics (IK) to associate a consistent skeleton with temporally coherent joint rotations, our method is the first data-driven approach that directly outputs a kinematic skeleton, which is a complete, commonly used, motion representation. At the crux of our approach lies a deep neural network with embedded kinematic priors, which decomposes sequences of 2D joint positions into two separate attributes: a single, symmetric, skeleton, encoded by bone lengths, and a sequence of 3D joint rotations associated with global root positions and foot contact labels. These attributes are fed into an integrated forward kinematics (FK) layer that outputs 3D positions, which are compared to a ground truth. In addition, an adversarial loss is applied to the velocities of the recovered rotations, to ensure that they lie on the manifold of natural joint rotations. The key advantage of our approach is that it learns to infer natural joint rotations directly from the training data, rather than assuming an underlying model, or inferring them from joint positions using a data-agnostic IK solver. We show that enforcing a single consistent skeleton along with temporally coherent joint rotations constrains the solution space, leading to a more robust handling of self-occlusions and depth ambiguities.