 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep2Motion: Locomotion Reconstruction from Pressure Sensing Insoles
Oct 26, 2025Human motion is fundamentally driven by continuous physical interaction with the environment. Whether walking, running, or simply standing, the forces exchanged between our feet and the ground provide crucial insights for understanding and reconstructing human movement. Recent advances in wearable insole devices offer a compelling solution for capturing these forces in diverse, real-world scenarios. Sensor insoles pose no constraint on the users' motion (unlike mocap suits) and are unaffected by line-of-sight limitations (in contrast to optical systems). These qualities make sensor insoles an ideal choice for robust, unconstrained motion capture, particularly in outdoor environments. Surprisingly, leveraging these devices with recent motion reconstruction methods remains largely unexplored. Aiming to fill this gap, we present Step2Motion, the first approach to reconstruct human locomotion from multi-modal insole sensors. Our method utilizes pressure and inertial data-accelerations and angular rates-captured by the insoles to reconstruct human motion. We evaluate the effectiveness of our approach across a range of experiments to show its versatility for diverse locomotion styles, from simple ones like walking or jogging up to moving sideways, on tiptoes, slightly crouching, or dancing.
Environment-aware Motion Matching
Oct 26, 2025
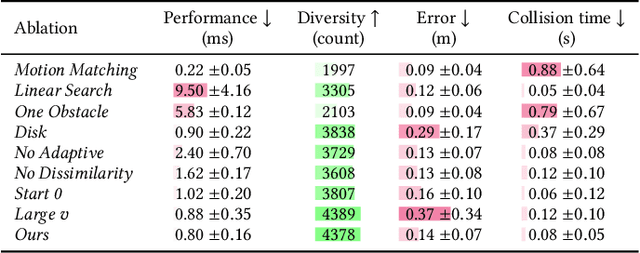
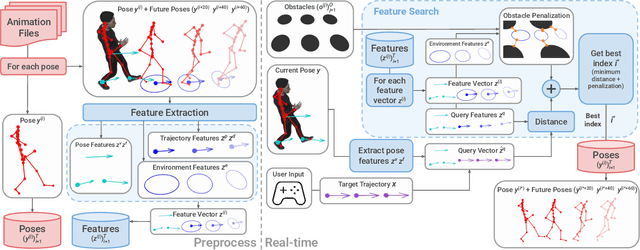
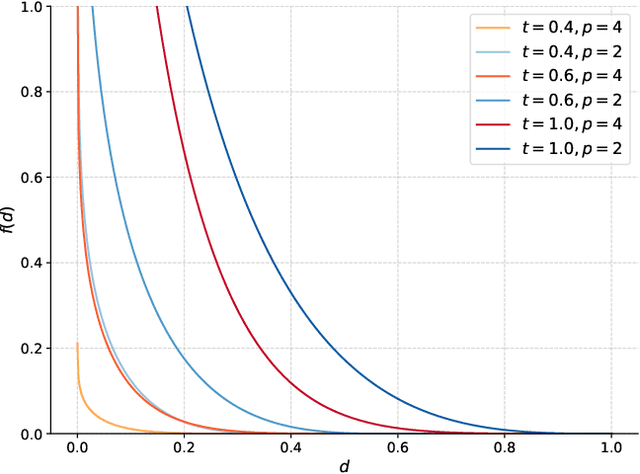
Interactive applications demand believable characters that respond naturally to dynamic environments. Traditional character animation techniques often struggle to handle arbitrary situations, leading to a growing trend of dynamically selecting motion-captured animations based on predefined features. While Motion Matching has proven effective for locomotion by aligning to target trajectories, animating environment interactions and crowd behaviors remains challenging due to the need to consider surrounding elements. Existing approaches often involve manual setup or lack the naturalism of motion capture. Furthermore, in crowd animation, body animation is frequently treated as a separate process from trajectory planning, leading to inconsistencies between body pose and root motion. To address these limitations, we present Environment-aware Motion Matching, a novel real-time system for full-body character animation that dynamically adapts to obstacles and other agents, emphasizing the bidirectional relationship between pose and trajectory. In a preprocessing step, we extract shape, pose, and trajectory features from a motion capture database. At runtime, we perform an efficient search that matches user input and current pose while penalizing collisions with a dynamic environment. Our method allows characters to naturally adjust their pose and trajectory to navigate crowded scenes.
SparsePoser: Real-time Full-body Motion Reconstruction from Sparse Data
Nov 03, 2023Accurate and reliable human motion reconstruction is crucial for creating natural interactions of full-body avatars in Virtual Reality (VR) and entertainment applications. As the Metaverse and social applications gain popularity, users are seeking cost-effective solutions to create full-body animations that are comparable in quality to those produced by commercial motion capture systems. In order to provide affordable solutions, though, it is important to minimize the number of sensors attached to the subject's body. Unfortunately, reconstructing the full-body pose from sparse data is a heavily under-determined problem. Some studies that use IMU sensors face challenges in reconstructing the pose due to positional drift and ambiguity of the poses. In recent years, some mainstream VR systems have released 6-degree-of-freedom (6-DoF) tracking devices providing positional and rotational information. Nevertheless, most solutions for reconstructing full-body poses rely on traditional inverse kinematics (IK) solutions, which often produce non-continuous and unnatural poses. In this article, we introduce SparsePoser, a novel deep learning-based solution for reconstructing a full-body pose from a reduced set of six tracking devices. Our system incorporates a convolutional-based autoencoder that synthesizes high-quality continuous human poses by learning the human motion manifold from motion capture data. Then, we employ a learned IK component, made of multiple lightweight feed-forward neural networks, to adjust the hands and feet toward the corresponding trackers. We extensively evaluate our method on publicly available motion capture datasets and with real-time live demos. We show that our method outperforms state-of-the-art techniques using IMU sensors or 6-DoF tracking devices, and can be used for users with different body dimensions and proportions.